 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdgeConvFormer: Dynamic Graph CNN and Transformer based Anomaly Detection in Multivariate Time Series
Dec 04, 2023Transformer-based models for anomaly detection in multivariate time series can benefit from the self-attention mechanism due to its advantage in modeling long-term dependencies. However, Transformer-based anomaly detection models have problems such as a large amount of data being required for training, standard positional encoding is not suitable for multivariate time series data, and the interdependence between time series is not considered. To address these limitations, we propose a novel anomaly detection method, named EdgeConvFormer, which integrates Time2vec embedding, stacked dynamic graph CNN, and Transformer to extract global and local spatial-time information. This design of EdgeConvFormer empowers it with decomposition capacities for complex time series, progressive spatiotemporal correlation discovery between time series, and representation aggregation of multi-scale features. Experiments demonstrate that EdgeConvFormer can learn the spatial-temporal correlations from multivariate time series data and achieve better anomaly detection performance than the state-of-the-art approaches on many real-world datasets of different scales.
Hierarchical Classification of Kelps utilizing Deep Residual Features
Jun 26, 2019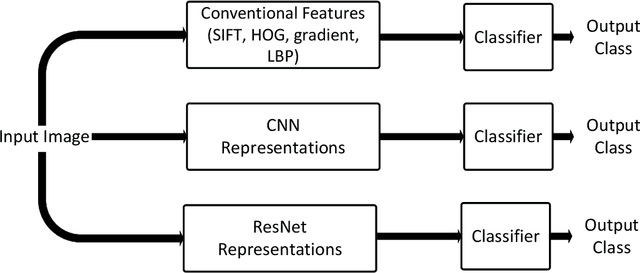
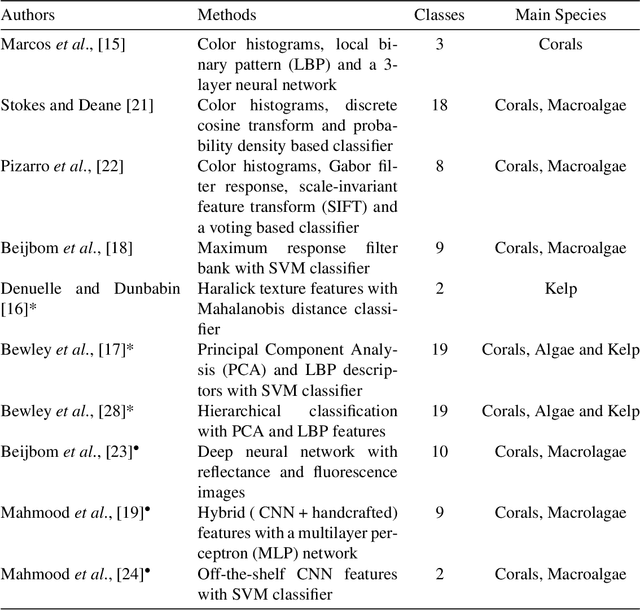
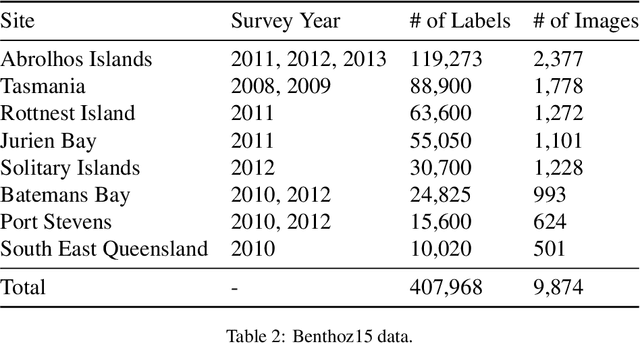

Across the globe, remote image data is rapidly being collected for the assessment of benthic communities from shallow to extremely deep waters on continental slopes to the abyssal seas. Exploiting this data is presently limited by the time it takes for experts to identify organisms found in these images. With this limitation in mind, a large effort has been made globally to introduce automation and machine learning algorithms to accelerate both classification and assessment of marine benthic biota. One major issue lies with organisms that move with swell and currents, like kelps. This paper presents an automatic hierarchical classification method to classify kelps from images collected by autonomous underwater vehicles. The proposed kelp classification approach exploits learned image representations extracted from deep residual networks. These powerful and generic features outperform the traditional off-the-shelf CNN features, which have already shown superior performance over the conventional hand-crafted features. Experiments also demonstrate that the hierarchical classification method outperforms the common parallel multi-class classifications by a significant margin. Experimental results are provided to illustrate the efficient applicability of the proposed method to study the change in kelp cover over time for annually repeated AUV surveys.
Semi-supervised Learning on Graph with an Alternating Diffusion Process
Feb 16, 2019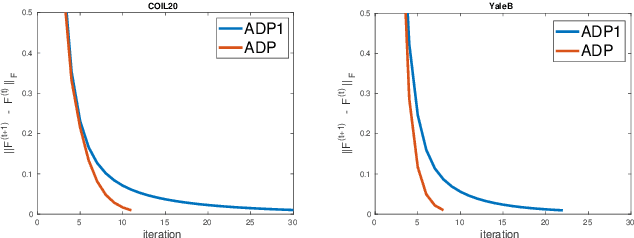
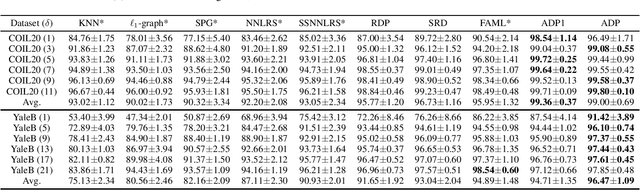
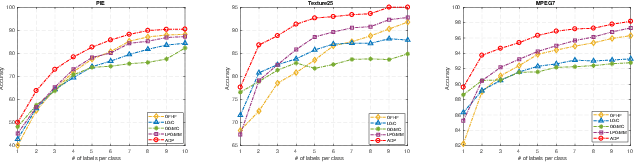

Graph-based semi-supervised learning usually involves two separate stages, constructing an affinity graph and then propagating labels for transductive inference on the graph. It is suboptimal to solve them independently, as the correlation between the affinity graph and labels are not fully exploited. In this paper, we integrate the two stages into one unified framework by formulating the graph construction as a regularized function estimation problem similar to label propagation. We propose an alternating diffusion process to solve the two problems simultaneously, which allows us to learn the graph and unknown labels in an iterative fashion. With the proposed framework, we are able to adequately leverage both the given labels and estimated labels to construct a better graph, and effectively propagate labels on such a dynamic graph updated simultaneously with the newly obtained labels. Extensive experiments on various real-world datasets have demonstrated the superiority of the proposed method compared to other state-of-the-art methods.
Exploiting Layerwise Convexity of Rectifier Networks with Sign Constrained Weights
Nov 14, 2017By introducing sign constraints on the weights, this paper proposes sign constrained rectifier networks (SCRNs), whose training can be solved efficiently by the well known majorization-minimization (MM) algorithms. We prove that the proposed two-hidden-layer SCRNs, which exhibit negative weights in the second hidden layer and negative weights in the output layer, are capable of separating any two (or more) disjoint pattern sets. Furthermore, the proposed two-hidden-layer SCRNs can decompose the patterns of each class into several clusters so that each cluster is convexly separable from all the patterns from the other classes. This provides a means to learn the pattern structures and analyse the discriminant factors between different classes of patterns.
On the Compressive Power of Deep Rectifier Networks for High Resolution Representation of Class Boundaries
Aug 24, 2017This paper provides a theoretical justification of the superior classification performance of deep rectifier networks over shallow rectifier networks from the geometrical perspective of piecewise linear (PWL) classifier boundaries. We show that, for a given threshold on the approximation error, the required number of boundary facets to approximate a general smooth boundary grows exponentially with the dimension of the data, and thus the number of boundary facets, referred to as boundary resolution, of a PWL classifier is an important quality measure that can be used to estimate a lower bound on the classification errors. However, learning naively an exponentially large number of boundary facets requires the determination of an exponentially large number of parameters and also requires an exponentially large number of training patterns. To overcome this issue of "curse of dimensionality", compressive representations of high resolution classifier boundaries are required. To show the superior compressive power of deep rectifier networks over shallow rectifier networks, we prove that the maximum boundary resolution of a single hidden layer rectifier network classifier grows exponentially with the number of units when this number is smaller than the dimension of the patterns. When the number of units is larger than the dimension of the patterns, the growth rate is reduced to a polynomial order. Consequently, the capacity of generating a high resolution boundary will increase if the same large number of units are arranged in multiple layers instead of a single hidden layer. Taking high dimensional spherical boundaries as examples, we show how deep rectifier networks can utilize geometric symmetries to approximate a boundary with the same accuracy but with a significantly fewer number of parameters than single hidden layer nets.
Leveraging Structural Context Models and Ranking Score Fusion for Human Interaction Prediction
Jun 07, 2017
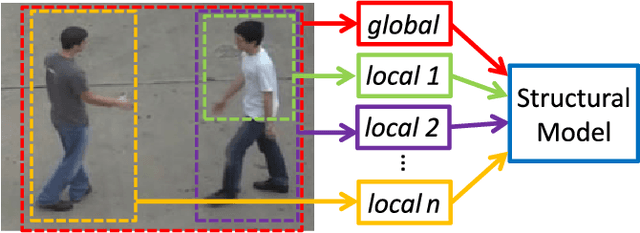
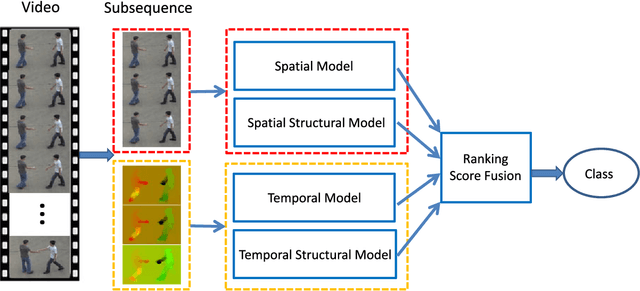
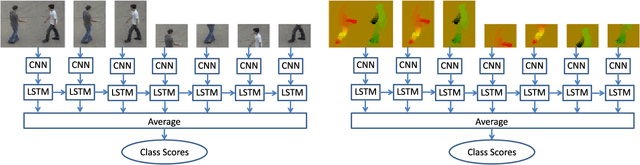
Predicting an interaction before it is fully executed is very important in applications such as human-robot interaction and video surveillance. In a two-human interaction scenario, there often contextual dependency structure between the global interaction context of the two humans and the local context of the different body parts of each human. In this paper, we propose to learn the structure of the interaction contexts, and combine it with the spatial and temporal information of a video sequence for a better prediction of the interaction class. The structural models, including the spatial and the temporal models, are learned with Long Short Term Memory (LSTM) networks to capture the dependency of the global and local contexts of each RGB frame and each optical flow image, respectively. LSTM networks are also capable of detecting the key information from the global and local interaction contexts. Moreover, to effectively combine the structural models with the spatial and temporal models for interaction prediction, a ranking score fusion method is also introduced to automatically compute the optimal weight of each model for score fusion. Experimental results on the BIT Interaction and the UT-Interaction datasets clearly demonstrate the benefits of the proposed method.
A New Representation of Skeleton Sequences for 3D Action Recognition
Jun 05, 2017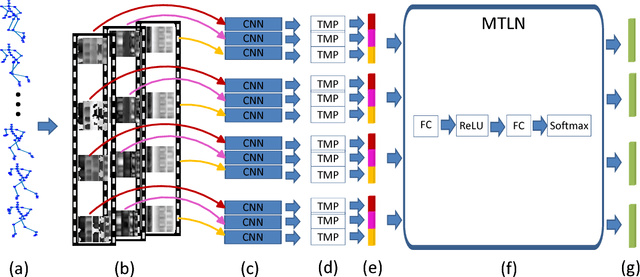
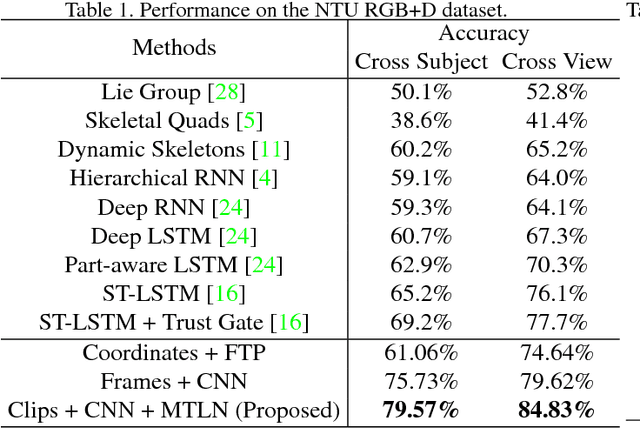
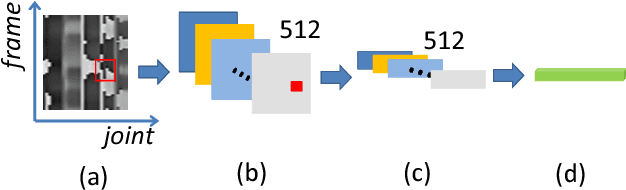
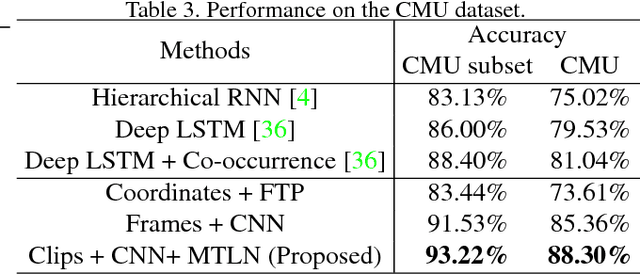
This paper presents a new method for 3D action recognition with skeleton sequences (i.e., 3D trajectories of human skeleton joints). The proposed method first transforms each skeleton sequence into three clips each consisting of several frames for spatial temporal feature learning using deep neural networks. Each clip is generated from one channel of the cylindrical coordinates of the skeleton sequence. Each frame of the generated clips represents the temporal information of the entire skeleton sequence, and incorporates one particular spatial relationship between the joints. The entire clips include multiple frames with different spatial relationships, which provide useful spatial structural information of the human skeleton. We propose to use deep convolutional neural networks to learn long-term temporal information of the skeleton sequence from the frames of the generated clips, and then use a Multi-Task Learning Network (MTLN) to jointly process all frames of the generated clips in parallel to incorporate spatial structural information for action recognition. Experimental results clearly show the effectiveness of the proposed new representation and feature learning method for 3D action recognition.
From Deep to Shallow: Transformations of Deep Rectifier Networks
Mar 30, 2017In this paper, we introduce transformations of deep rectifier networks, enabling the conversion of deep rectifier networks into shallow rectifier networks. We subsequently prove that any rectifier net of any depth can be represented by a maximum of a number of functions that can be realized by a shallow network with a single hidden layer. The transformations of both deep rectifier nets and deep residual nets are conducted to demonstrate the advantages of the residual nets over the conventional neural nets and the advantages of the deep neural nets over the shallow neural nets. In summary, for two rectifier nets with different depths but with same total number of hidden units, the corresponding single hidden layer representation of the deeper net is much more complex than the corresponding single hidden representation of the shallower net. Similarly, for a residual net and a conventional rectifier net with the same structure except for the skip connections in the residual net, the corresponding single hidden layer representation of the residual net is much more complex than the corresponding single hidden layer representation of the conventional net.
ResFeats: Residual Network Based Features for Image Classification
Nov 21, 2016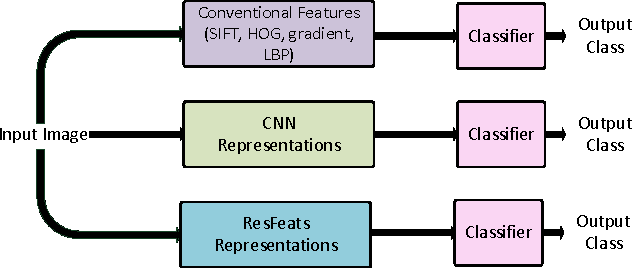
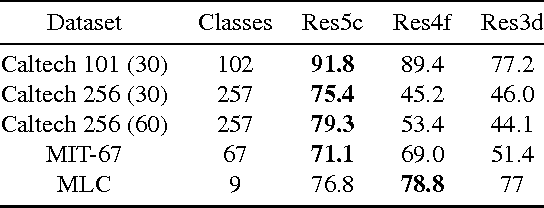

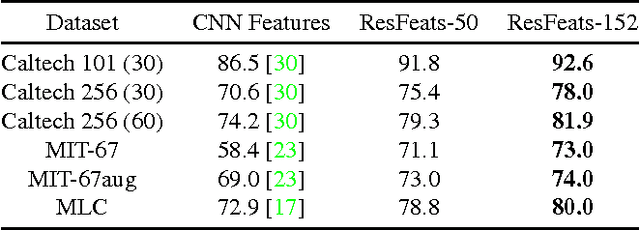
Deep residual networks have recently emerged as the state-of-the-art architecture in image segmentation and object detection. In this paper, we propose new image features (called ResFeats) extracted from the last convolutional layer of deep residual networks pre-trained on ImageNet. We propose to use ResFeats for diverse image classification tasks namely, object classification, scene classification and coral classification and show that ResFeats consistently perform better than their CNN counterparts on these classification tasks. Since the ResFeats are large feature vectors, we propose to use PCA for dimensionality reduction. Experimental results are provided to show the effectiveness of ResFeats with state-of-the-art classification accuracies on Caltech-101, Caltech-256 and MLC datasets and a significant performance improvement on MIT-67 dataset compared to the widely used CNN features.
A Spatial Layout and Scale Invariant Feature Representation for Indoor Scene Classification
Aug 14, 2015
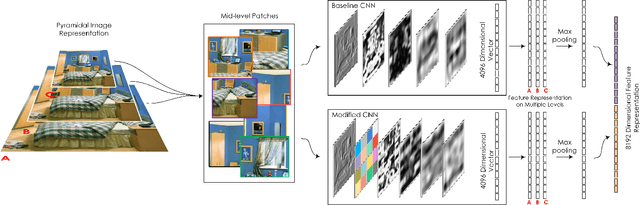
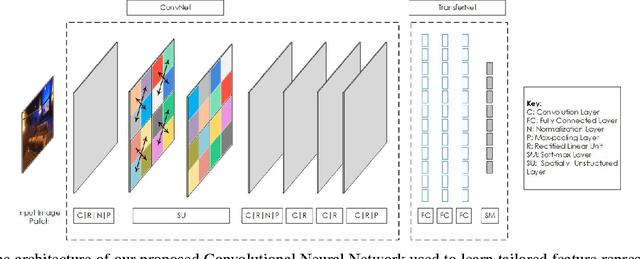

Unlike standard object classification, where the image to be classified contains one or multiple instances of the same object, indoor scene classification is quite different since the image consists of multiple distinct objects. Further, these objects can be of varying sizes and are present across numerous spatial locations in different layouts. For automatic indoor scene categorization, large scale spatial layout deformations and scale variations are therefore two major challenges and the design of rich feature descriptors which are robust to these challenges is still an open problem. This paper introduces a new learnable feature descriptor called "spatial layout and scale invariant convolutional activations" to deal with these challenges. For this purpose, a new Convolutional Neural Network architecture is designed which incorporates a novel 'Spatially Unstructured' layer to introduce robustness against spatial layout deformations. To achieve scale invariance, we present a pyramidal image representation. For feasible training of the proposed network for images of indoor scenes, the paper proposes a new methodology which efficiently adapts a trained network model (on a large scale data) for our task with only a limited amount of available training data. Compared with existing state of the art, the proposed approach achieves a relative performance improvement of 3.2%, 3.8%, 7.0%, 11.9% and 2.1% on MIT-67, Scene-15, Sports-8, Graz-02 and NYU datasets respectively.