 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Image Camera Response Function Using Prediction Consistency and Gradual Refinement
Oct 08, 2020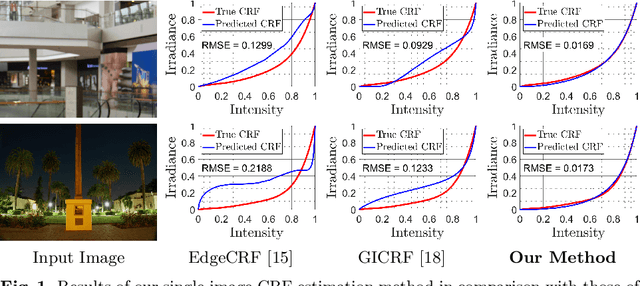
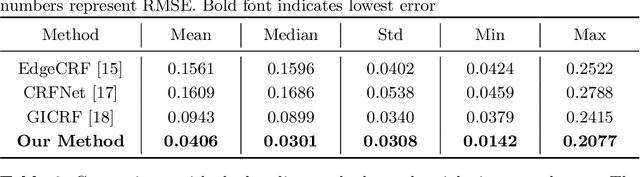
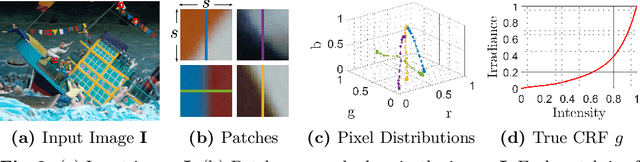
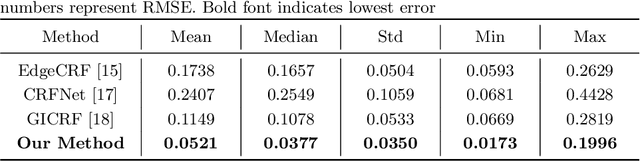
A few methods have been proposed to estimate the CRF from a single image, however most of them tend to fail in handling general real images. For instance, EdgeCRF based on patches extracted from colour edges works effectively only when the presence of noise is insignificant, which is not the case for many real images; and, CRFNet, a recent method based on fully supervised deep learning works only for the CRFs that are in the training data, and hence fail to deal with other possible CRFs beyond the training data. To address these problems, we introduce a non-deep-learning method using prediction consistency and gradual refinement. First, we rely more on the patches of the input image that provide more consistent predictions. If the predictions from a patch are more consistent, it means that the patch is likely to be less affected by noise or any inferior colour combinations, and hence, it can be more reliable for CRF estimation. Second, we employ a gradual refinement scheme in which we start from a simple CRF model to generate a result which is more robust to noise but less accurate, and then we gradually increase the model's complexity to improve the estimation. This is because a simple model, while being less accurate, overfits less to noise than a complex model does. Our experiments confirm that our method outperforms the existing single-image methods for both daytime and nighttime real images.
Depth Estimation in Nighttime using Stereo-Consistent Cyclic Translations
Sep 30, 2019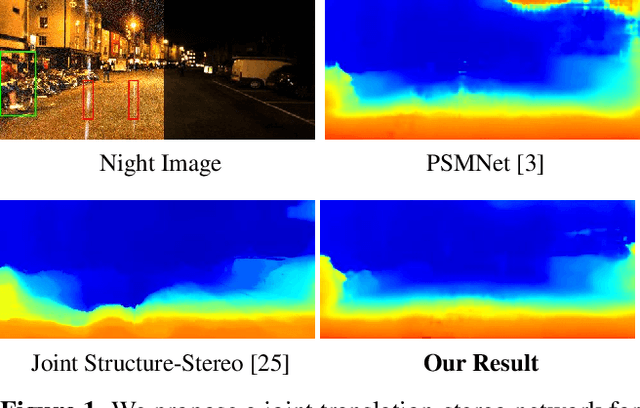
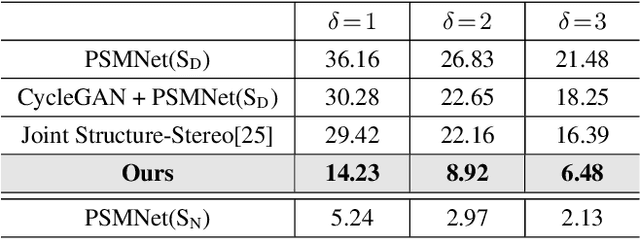
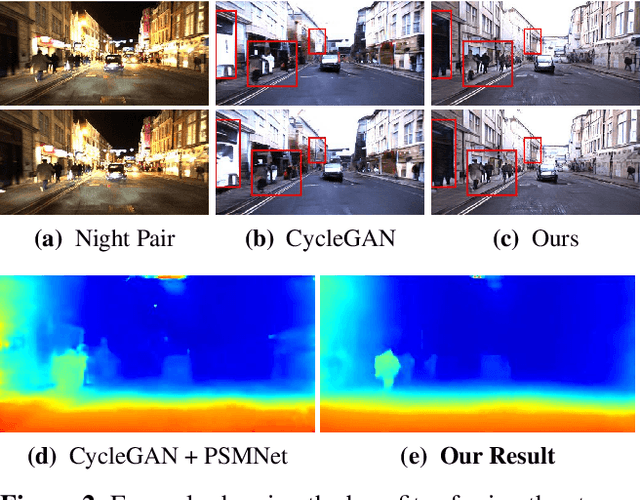
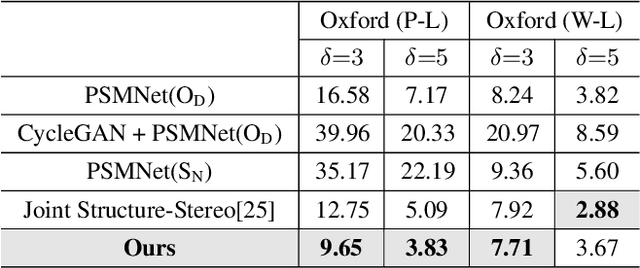
Most existing methods of depth from stereo are designed for daytime scenes, where the lighting can be assumed to be sufficiently bright and more or less uniform. Unfortunately, this assumption does not hold for nighttime scenes, causing the existing methods to be erroneous when deployed in nighttime. Nighttime is not only about low light, but also about glow, glare, non-uniform distribution of light, etc. One of the possible solutions is to train a network on nighttime images in a fully supervised manner. However, to obtain proper disparity ground-truths that are dense, independent from glare/glow, and can have sufficiently far depth ranges is extremely intractable. In this paper, to address the problem of depth from stereo in nighttime, we introduce a joint translation and stereo network that is robust to nighttime conditions. Our method uses no direct supervision and does not require ground-truth disparities of the nighttime training images. First, we utilize a translation network that can render realistic nighttime stereo images from given daytime stereo images. Second, we train a stereo network on the rendered nighttime images using the available disparity supervision from the daytime images, and simultaneously also train the translation network to gradually improve the rendered nighttime images. We introduce a stereo-consistency constraint into our translation network to ensure that the translated pairs are stereo-consistent. Our experiments show that our joint translation-stereo network outperforms the state-of-the-art methods.
3D Rigid Motion Segmentation with Mixed and Unknown Number of Models
Aug 16, 2019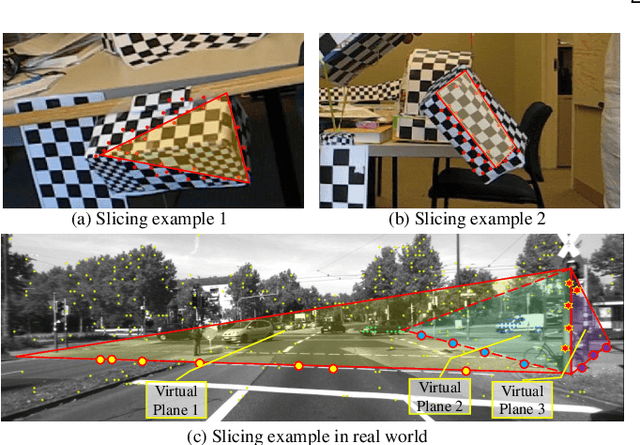
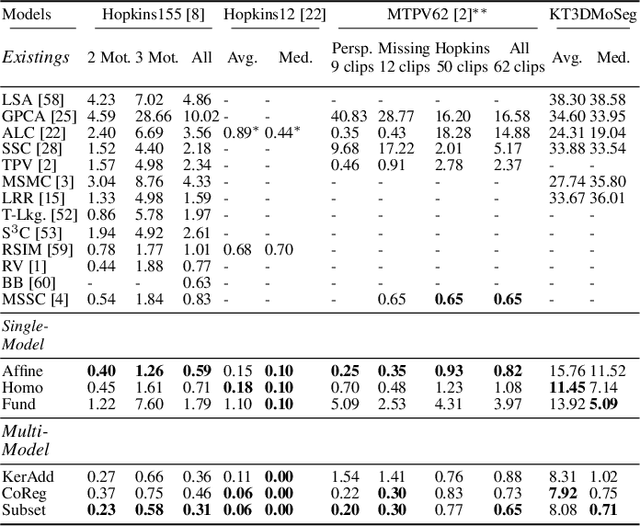

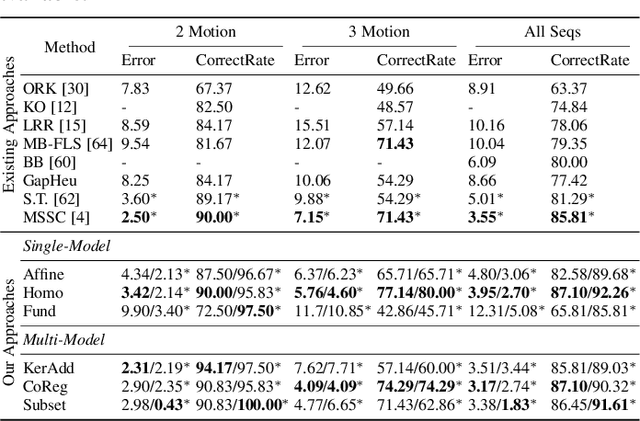
Many real-world video sequences cannot be conveniently categorized as general or degenerate; in such cases, imposing a false dichotomy in using the fundamental matrix or homography model for motion segmentation on video sequences would lead to difficulty. Even when we are confronted with a general scene-motion, the fundamental matrix approach as a model for motion segmentation still suffers from several defects, which we discuss in this paper. The full potential of the fundamental matrix approach could only be realized if we judiciously harness information from the simpler homography model. From these considerations, we propose a multi-model spectral clustering framework that synergistically combines multiple models (homography and fundamental matrix) together. We show that the performance can be substantially improved in this way. For general motion segmentation tasks, the number of independently moving objects is often unknown a priori and needs to be estimated from the observations. This is referred to as model selection and it is essentially still an open research problem. In this work, we propose a set of model selection criteria balancing data fidelity and model complexity. We perform extensive testing on existing motion segmentation datasets with both segmentation and model selection tasks, achieving state-of-the-art performance on all of them; we also put forth a more realistic and challenging dataset adapted from the KITTI benchmark, containing real-world effects such as strong perspectives and strong forward translations not seen in the traditional datasets.
Automatic Target Detection for Sparse Hyperspectral Images
Apr 14, 2019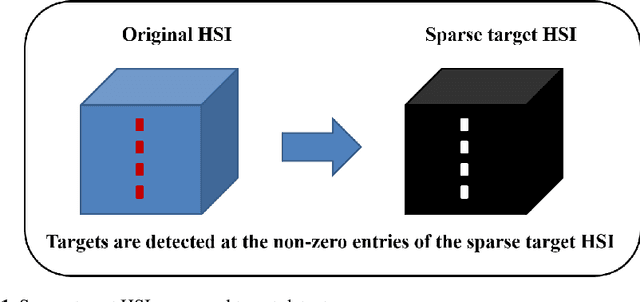

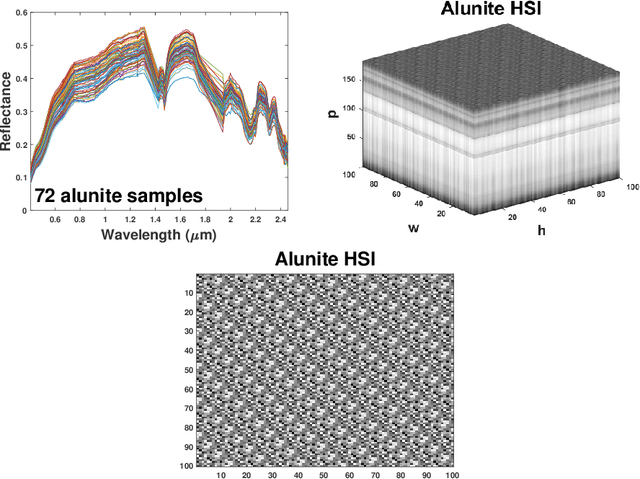

This chapter introduces a novel target detector for hyperspectral imagery. The detector is independent on the unknown covariance matrix, behaves well in large dimensions, distributional free, invariant to atmospheric effects, and does not require a background dictionary to be constructed. Based on a modification of the Robust Principal Component Analysis (RPCA), a given hyperspectral image (HSI) is regarded as being made up of the sum of low-rank background HSI and a sparse target HSI that contains the targets based on a pre-learned target dictionary specified by the user. The sparse component (that is, the sparse target HSI) is directly used for the detection, that is, the targets are simply detected at the non-zero entries of the sparse target HSI. Hence, a novel target detector is developed and which is simply a sparse HSI generated automatically from the original HSI, but containing only the targets with the background is suppressed. The detector is evaluated on real experiments, and the results of which demonstrate its effectiveness for hyperspectral target detection especially when the targets have overlapping spectral features with the background.
Learning for Multi-Type Subspace Clustering
Apr 03, 2019

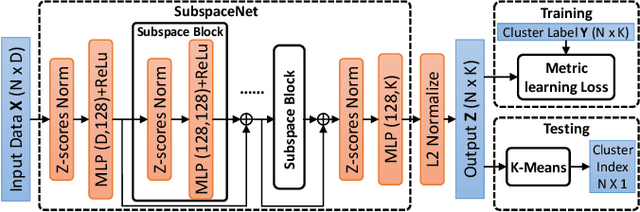
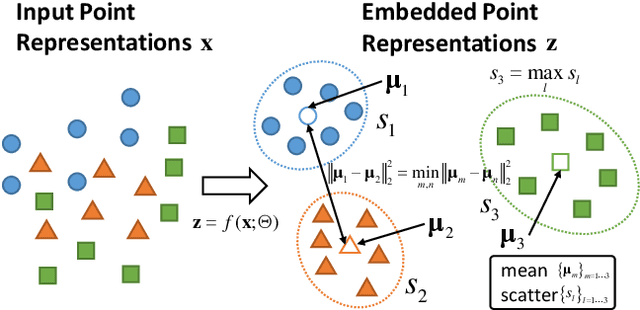
Subspace clustering has been extensively studied from the hypothesis-and-test, algebraic, and spectral clustering based perspectives. Most assume that only a single type/class of subspace is present. Generalizations to multiple types are non-trivial, plagued by challenges such as choice of types and numbers of models, sampling imbalance and parameter tuning. In this work, we formulate the multi-type subspace clustering problem as one of learning non-linear subspace filters via deep multi-layer perceptrons (mlps). The response to the learnt subspace filters serve as the feature embedding that is clustering-friendly, i.e., points of the same clusters will be embedded closer together through the network. For inference, we apply K-means to the network output to cluster the data. Experiments are carried out on both synthetic and real world multi-type fitting problems, producing state-of-the-art results.
Rolling-Shutter-Aware Differential SfM and Image Rectification
Mar 10, 2019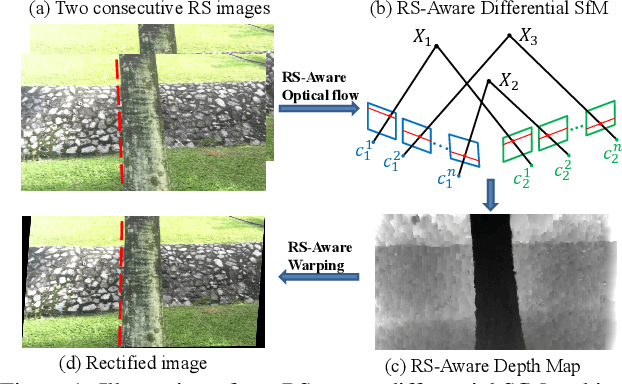
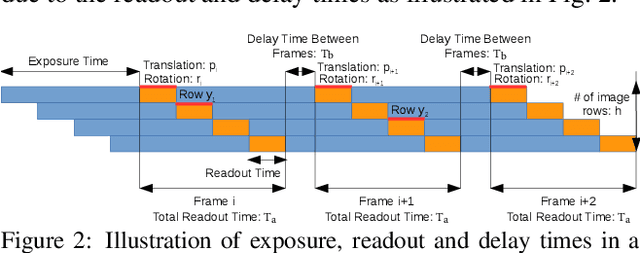

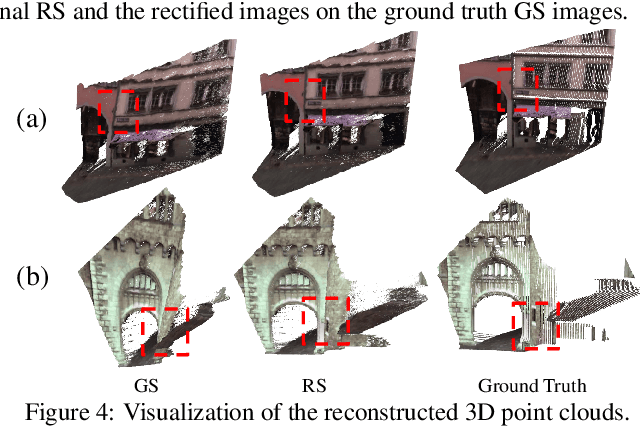
In this paper, we develop a modified differential Structure from Motion (SfM) algorithm that can estimate relative pose from two consecutive frames despite of Rolling Shutter (RS) artifacts. In particular, we show that under constant velocity assumption, the errors induced by the rolling shutter effect can be easily rectified by a linear scaling operation on each optical flow. We further propose a 9-point algorithm to recover the relative pose of a rolling shutter camera that undergoes constant acceleration motion. We demonstrate that the dense depth maps recovered from the relative pose of the RS camera can be used in a RS-aware warping for image rectification to recover high-quality Global Shutter (GS) images. Experiments on both synthetic and real RS images show that our RS-aware differential SfM algorithm produces more accurate results on relative pose estimation and 3D reconstruction from images distorted by RS effect compared to standard SfM algorithms that assume a GS camera model. We also demonstrate that our RS-aware warping for image rectification method outperforms state-of-the-art commercial software products, i.e. Adobe After Effects and Apple Imovie, at removing RS artifacts.
Learning for Multi-Model and Multi-Type Fitting
Jan 29, 2019

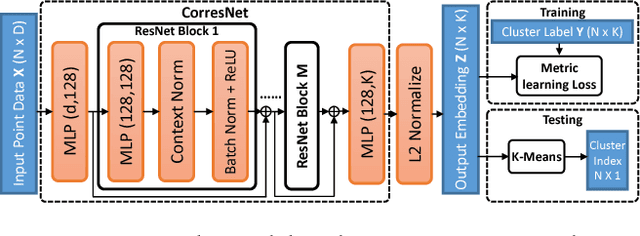
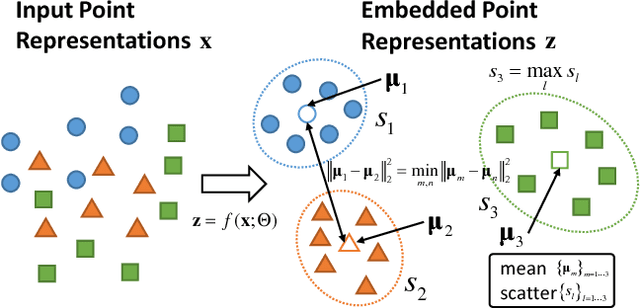
Multi-model fitting has been extensively studied from the random sampling and clustering perspectives. Most assume that only a single type/class of model is present and their generalizations to fitting multiple types of models/structures simultaneously are non-trivial. The inherent challenges include choice of types and numbers of models, sampling imbalance and parameter tuning, all of which render conventional approaches ineffective. In this work, we formulate the multi-model multi-type fitting problem as one of learning deep feature embedding that is clustering-friendly. In other words, points of the same clusters are embedded closer together through the network. For inference, we apply K-means to cluster the data in the embedded feature space and model selection is enabled by analyzing the K-means residuals. Experiments are carried out on both synthetic and real world multi-type fitting datasets, producing state-of-the-art results. Comparisons are also made on single-type multi-model fitting tasks with promising results as well.
Baseline Desensitizing In Translation Averaging
Jan 03, 2019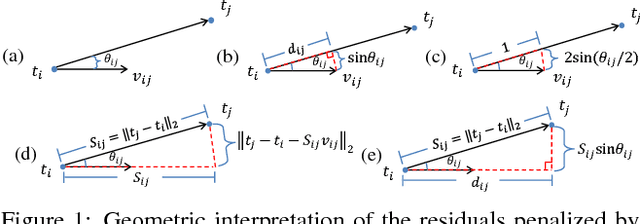
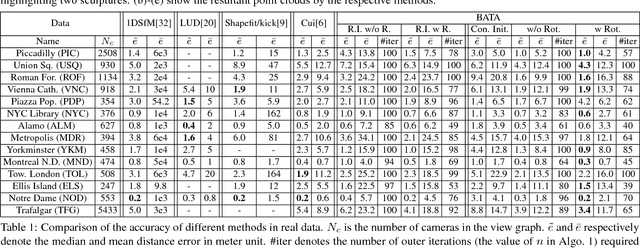
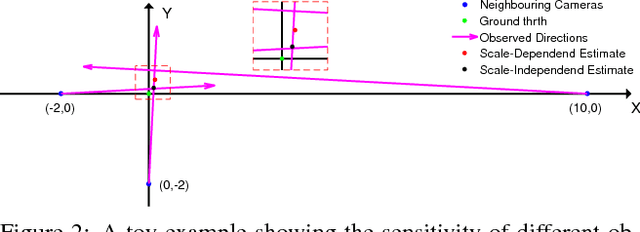
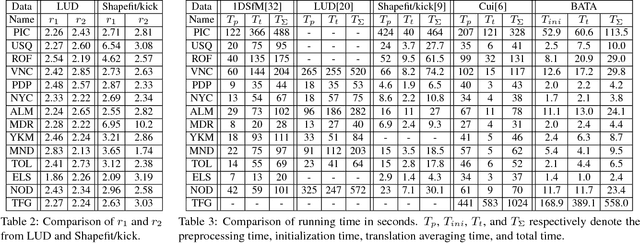
Many existing translation averaging algorithms are either sensitive to disparate camera baselines and have to rely on extensive preprocessing to improve the observed Epipolar Geometry graph, or if they are robust against disparate camera baselines, require complicated optimization to minimize the highly nonlinear angular error objective. In this paper, we carefully design a simple yet effective bilinear objective function, introducing a variable to perform the requisite normalization. The objective function enjoys the baseline-insensitive property of the angular error and yet is amenable to simple and efficient optimization by block coordinate descent, with good empirical performance. A rotation-assisted Iterative Reweighted Least Squares scheme is further put forth to help deal with outliers. We also contribute towards a better understanding of the behavior of two recent convex algorithms, LUD and Shapefit/kick, clarifying the underlying subtle difference that leads to the performance gap. Finally, we demonstrate that our algorithm achieves overall superior accuracies in benchmark dataset compared to state-of-theart methods, and is also several times faster.
Motion Segmentation by Exploiting Complementary Geometric Models
Apr 06, 2018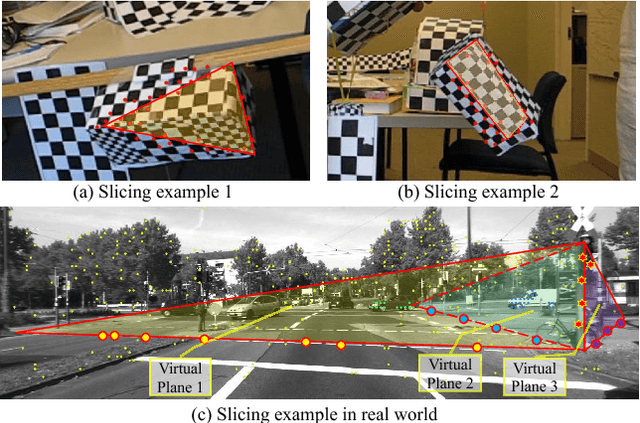
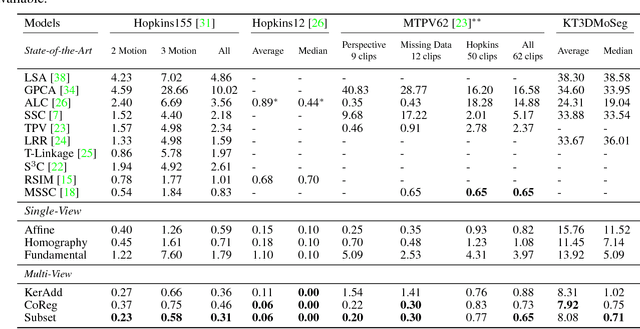
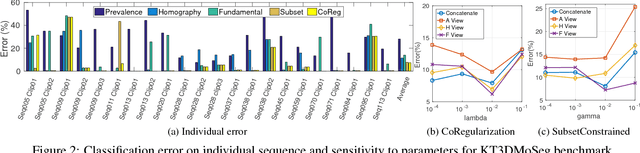

Many real-world sequences cannot be conveniently categorized as general or degenerate; in such cases, imposing a false dichotomy in using the fundamental matrix or homography model for motion segmentation would lead to difficulty. Even when we are confronted with a general scene-motion, the fundamental matrix approach as a model for motion segmentation still suffers from several defects, which we discuss in this paper. The full potential of the fundamental matrix approach could only be realized if we judiciously harness information from the simpler homography model. From these considerations, we propose a multi-view spectral clustering framework that synergistically combines multiple models together. We show that the performance can be substantially improved in this way. We perform extensive testing on existing motion segmentation datasets, achieving state-of-the-art performance on all of them; we also put forth a more realistic and challenging dataset adapted from the KITTI benchmark, containing real-world effects such as strong perspectives and strong forward translations not seen in the traditional datasets.
Single Image Deraining using Scale-Aware Multi-Stage Recurrent Network
Dec 19, 2017
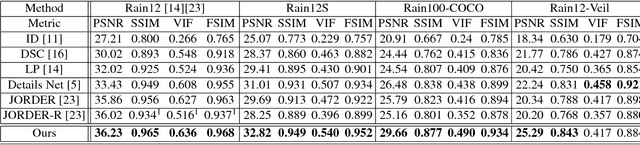


Given a single input rainy image, our goal is to visually remove rain streaks and the veiling effect caused by scattering and transmission of rain streaks and rain droplets. We are particularly concerned with heavy rain, where rain streaks of various sizes and directions can overlap each other and the veiling effect reduces contrast severely. To achieve our goal, we introduce a scale-aware multi-stage convolutional neural network. Our main idea here is that different sizes of rain-streaks visually degrade the scene in different ways. Large nearby streaks obstruct larger regions and are likely to reflect specular highlights more prominently than smaller distant streaks. These different effects of different streaks have their own characteristics in their image features, and thus need to be treated differently. To realize this, we create parallel sub-networks that are trained and made aware of these different scales of rain streaks. To our knowledge, this idea of parallel sub-networks that treats the same class of objects according to their unique sub-classes is novel, particularly in the context of rain removal. To verify our idea, we conducted experiments on both synthetic and real images, and found that our method is effective and outperforms the state-of-the-art methods.