 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Target Detection for Sparse Hyperspectral Images
Apr 14, 2019

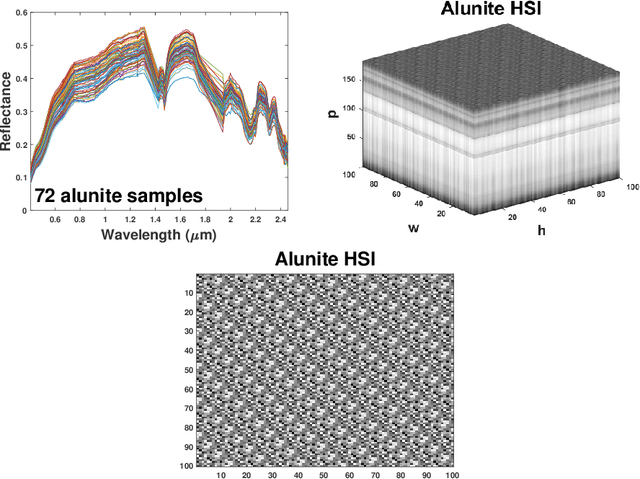

This chapter introduces a novel target detector for hyperspectral imagery. The detector is independent on the unknown covariance matrix, behaves well in large dimensions, distributional free, invariant to atmospheric effects, and does not require a background dictionary to be constructed. Based on a modification of the Robust Principal Component Analysis (RPCA), a given hyperspectral image (HSI) is regarded as being made up of the sum of low-rank background HSI and a sparse target HSI that contains the targets based on a pre-learned target dictionary specified by the user. The sparse component (that is, the sparse target HSI) is directly used for the detection, that is, the targets are simply detected at the non-zero entries of the sparse target HSI. Hence, a novel target detector is developed and which is simply a sparse HSI generated automatically from the original HSI, but containing only the targets with the background is suppressed. The detector is evaluated on real experiments, and the results of which demonstrate its effectiveness for hyperspectral target detection especially when the targets have overlapping spectral features with the background.
Efficient Implementation of a Recognition System Using the Cortex Ventral Stream Model
Nov 21, 2017



In this paper, an efficient implementation for a recognition system based on the original HMAX model of the visual cortex is proposed. Various optimizations targeted to increase accuracy at the so-called layers S1, C1, and S2 of the HMAX model are proposed. At layer S1, all unimportant information such as illumination and expression variations are eliminated from the images. Each image is then convolved with 64 separable Gabor filters in the spatial domain. At layer C1, the minimum scales values are exploited to be embedded into the maximum ones using the additive embedding space. At layer S2, the prototypes are generated in a more efficient way using Partitioning Around Medoid (PAM) clustering algorithm. The impact of these optimizations in terms of accuracy and computational complexity was evaluated on the Caltech101 database, and compared with the baseline performance using support vector machine (SVM) and nearest neighbor (NN) classifiers. The results show that our model provides significant improvement in accuracy at the S1 layer by more than 10% where the computational complexity is also reduced. The accuracy is slightly increased for both approximations at the C1 and S2 layers.
* 10 pages