 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effectiveness of Membership Inference in Targeted Data Extraction from Large Language Models
Dec 15, 2025Large Language Models (LLMs) are prone to memorizing training data, which poses serious privacy risks. Two of the most prominent concerns are training data extraction and Membership Inference Attacks (MIAs). Prior research has shown that these threats are interconnected: adversaries can extract training data from an LLM by querying the model to generate a large volume of text and subsequently applying MIAs to verify whether a particular data point was included in the training set. In this study, we integrate multiple MIA techniques into the data extraction pipeline to systematically benchmark their effectiveness. We then compare their performance in this integrated setting against results from conventional MIA benchmarks, allowing us to evaluate their practical utility in real-world extraction scenarios.
Detecting Quishing Attacks with Machine Learning Techniques Through QR Code Analysis
May 06, 2025



The rise of QR code based phishing ("Quishing") poses a growing cybersecurity threat, as attackers increasingly exploit QR codes to bypass traditional phishing defenses. Existing detection methods predominantly focus on URL analysis, which requires the extraction of the QR code payload, and may inadvertently expose users to malicious content. Moreover, QR codes can encode various types of data beyond URLs, such as Wi-Fi credentials and payment information, making URL-based detection insufficient for broader security concerns. To address these gaps, we propose the first framework for quishing detection that directly analyzes QR code structure and pixel patterns without extracting the embedded content. We generated a dataset of phishing and benign QR codes and we used it to train and evaluate multiple machine learning models, including Logistic Regression, Decision Trees, Random Forest, Naive Bayes, LightGBM, and XGBoost. Our best-performing model (XGBoost) achieves an AUC of 0.9106, demonstrating the feasibility of QR-centric detection. Through feature importance analysis, we identify key visual indicators of malicious intent and refine our feature set by removing non-informative pixels, improving performance to an AUC of 0.9133 with a reduced feature space. Our findings reveal that the structural features of QR code correlate strongly with phishing risk. This work establishes a foundation for quishing mitigation and highlights the potential of direct QR analysis as a critical layer in modern phishing defenses.
Fine-Tuning LLMs for Low-Resource Dialect Translation: The Case of Lebanese
Apr 30, 2025This paper examines the effectiveness of Large Language Models (LLMs) in translating the low-resource Lebanese dialect, focusing on the impact of culturally authentic data versus larger translated datasets. We compare three fine-tuning approaches: Basic, contrastive, and grammar-hint tuning, using open-source Aya23 models. Experiments reveal that models fine-tuned on a smaller but culturally aware Lebanese dataset (LW) consistently outperform those trained on larger, non-native data. The best results were achieved through contrastive fine-tuning paired with contrastive prompting, which indicates the benefits of exposing translation models to bad examples. In addition, to ensure authentic evaluation, we introduce LebEval, a new benchmark derived from native Lebanese content, and compare it to the existing FLoRes benchmark. Our findings challenge the "More Data is Better" paradigm and emphasize the crucial role of cultural authenticity in dialectal translation. We made our datasets and code available on Github.
Streamlining Systematic Reviews: A Novel Application of Large Language Models
Dec 14, 2024Systematic reviews (SRs) are essential for evidence-based guidelines but are often limited by the time-consuming nature of literature screening. We propose and evaluate an in-house system based on Large Language Models (LLMs) for automating both title/abstract and full-text screening, addressing a critical gap in the literature. Using a completed SR on Vitamin D and falls (14,439 articles), the LLM-based system employed prompt engineering for title/abstract screening and Retrieval-Augmented Generation (RAG) for full-text screening. The system achieved an article exclusion rate (AER) of 99.5%, specificity of 99.6%, a false negative rate (FNR) of 0%, and a negative predictive value (NPV) of 100%. After screening, only 78 articles required manual review, including all 20 identified by traditional methods, reducing manual screening time by 95.5%. For comparison, Rayyan, a commercial tool for title/abstract screening, achieved an AER of 72.1% and FNR of 5% when including articles Rayyan considered as undecided or likely to include. Lowering Rayyan's inclusion thresholds improved FNR to 0% but increased screening time. By addressing both screening phases, the LLM-based system significantly outperformed Rayyan and traditional methods, reducing total screening time to 25.5 hours while maintaining high accuracy. These findings highlight the transformative potential of LLMs in SR workflows by offering a scalable, efficient, and accurate solution, particularly for the full-text screening phase, which has lacked automation tools.
Large Multimodal Agents for Accurate Phishing Detection with Enhanced Token Optimization and Cost Reduction
Dec 03, 2024With the rise of sophisticated phishing attacks, there is a growing need for effective and economical detection solutions. This paper explores the use of large multimodal agents, specifically Gemini 1.5 Flash and GPT-4o mini, to analyze both URLs and webpage screenshots via APIs, thus avoiding the complexities of training and maintaining AI systems. Our findings indicate that integrating these two data types substantially enhances detection performance over using either type alone. However, API usage incurs costs per query that depend on the number of input and output tokens. To address this, we propose a two-tiered agentic approach: initially, one agent assesses the URL, and if inconclusive, a second agent evaluates both the URL and the screenshot. This method not only maintains robust detection performance but also significantly reduces API costs by minimizing unnecessary multi-input queries. Cost analysis shows that with the agentic approach, GPT-4o mini can process about 4.2 times as many websites per $100 compared to the multimodal approach (107,440 vs. 25,626), and Gemini 1.5 Flash can process about 2.6 times more websites (2,232,142 vs. 862,068). These findings underscore the significant economic benefits of the agentic approach over the multimodal method, providing a viable solution for organizations aiming to leverage advanced AI for phishing detection while controlling expenses.
To Ensemble or Not: Assessing Majority Voting Strategies for Phishing Detection with Large Language Models
Nov 29, 2024The effectiveness of Large Language Models (LLMs) significantly relies on the quality of the prompts they receive. However, even when processing identical prompts, LLMs can yield varying outcomes due to differences in their training processes. To leverage the collective intelligence of multiple LLMs and enhance their performance, this study investigates three majority voting strategies for text classification, focusing on phishing URL detection. The strategies are: (1) a prompt-based ensemble, which utilizes majority voting across the responses generated by a single LLM to various prompts; (2) a model-based ensemble, which entails aggregating responses from multiple LLMs to a single prompt; and (3) a hybrid ensemble, which combines the two methods by sending different prompts to multiple LLMs and then aggregating their responses. Our analysis shows that ensemble strategies are most suited in cases where individual components exhibit equivalent performance levels. However, when there is a significant discrepancy in individual performance, the effectiveness of the ensemble method may not exceed that of the highest-performing single LLM or prompt. In such instances, opting for ensemble techniques is not recommended.
Evaluating the Efficacy of Prompt-Engineered Large Multimodal Models Versus Fine-Tuned Vision Transformers in Image-Based Security Applications
Mar 26, 2024The success of Large Language Models (LLMs) has led to a parallel rise in the development of Large Multimodal Models (LMMs), such as Gemini-pro, which have begun to transform a variety of applications. These sophisticated multimodal models are designed to interpret and analyze complex data, integrating both textual and visual information on a scale previously unattainable, opening new avenues for a range of applications. This paper investigates the applicability and effectiveness of prompt-engineered Gemini-pro LMMs versus fine-tuned Vision Transformer (ViT) models in addressing critical security challenges. We focus on two distinct tasks: a visually evident task of detecting simple triggers, such as small squares in images, indicative of potential backdoors, and a non-visually evident task of malware classification through visual representations. Our results highlight a significant divergence in performance, with Gemini-pro falling short in accuracy and reliability when compared to fine-tuned ViT models. The ViT models, on the other hand, demonstrate exceptional accuracy, achieving near-perfect performance on both tasks. This study not only showcases the strengths and limitations of prompt-engineered LMMs in cybersecurity applications but also emphasizes the unmatched efficacy of fine-tuned ViT models for precise and dependable tasks.
Automatic Target Detection for Sparse Hyperspectral Images
Apr 14, 2019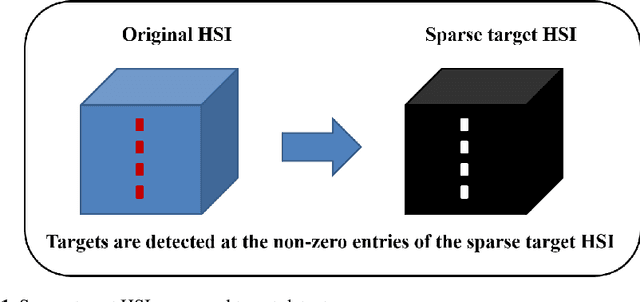


This chapter introduces a novel target detector for hyperspectral imagery. The detector is independent on the unknown covariance matrix, behaves well in large dimensions, distributional free, invariant to atmospheric effects, and does not require a background dictionary to be constructed. Based on a modification of the Robust Principal Component Analysis (RPCA), a given hyperspectral image (HSI) is regarded as being made up of the sum of low-rank background HSI and a sparse target HSI that contains the targets based on a pre-learned target dictionary specified by the user. The sparse component (that is, the sparse target HSI) is directly used for the detection, that is, the targets are simply detected at the non-zero entries of the sparse target HSI. Hence, a novel target detector is developed and which is simply a sparse HSI generated automatically from the original HSI, but containing only the targets with the background is suppressed. The detector is evaluated on real experiments, and the results of which demonstrate its effectiveness for hyperspectral target detection especially when the targets have overlapping spectral features with the background.
Efficient Implementation of a Recognition System Using the Cortex Ventral Stream Model
Nov 21, 2017



In this paper, an efficient implementation for a recognition system based on the original HMAX model of the visual cortex is proposed. Various optimizations targeted to increase accuracy at the so-called layers S1, C1, and S2 of the HMAX model are proposed. At layer S1, all unimportant information such as illumination and expression variations are eliminated from the images. Each image is then convolved with 64 separable Gabor filters in the spatial domain. At layer C1, the minimum scales values are exploited to be embedded into the maximum ones using the additive embedding space. At layer S2, the prototypes are generated in a more efficient way using Partitioning Around Medoid (PAM) clustering algorithm. The impact of these optimizations in terms of accuracy and computational complexity was evaluated on the Caltech101 database, and compared with the baseline performance using support vector machine (SVM) and nearest neighbor (NN) classifiers. The results show that our model provides significant improvement in accuracy at the S1 layer by more than 10% where the computational complexity is also reduced. The accuracy is slightly increased for both approximations at the C1 and S2 layers.
* 10 pages