 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCloud to Edge: Benchmarking LLM Inference On Hardware-Accelerated Single-Board Computers
Apr 24, 2026Large language models (LLMs) are becoming increasingly capable at small parameter scales. At the same time, conventional cloud-centric deployment introduces challenges around data privacy, latency, and cost that are acute in operational technology and defence environments. Advances in model distillation, quantisation, and affordable edge accelerators now make local LLM inference on single-board computers feasible, but the high dimensionality of the configuration space makes identifying optimal deployments difficult without structured evaluation. Existing LLM-specific edge benchmarking efforts rely on CPU-only inference, poor coverage of genuine single-board computers, and generic evaluation tasks that lack multi-dimensional assessment of hardware effectiveness. This paper proposes a multi-dimensional benchmarking methodology that jointly evaluates inference performance and hardware efficiency across four IoT-suitable edge platform configurations testing single-board computers with the latest available hardware accelerators. Our results reveal the benefits of using hardware accelerators such as NPUs and GPUs, along with multi-dimensional evaluations quantifying the trade-offs between power efficiency, physical device size and token throughput; offering practical guidance for deploying generative AI in privacy-sensitive and connectivity-limited environments such as unmanned vehicles and portable, ruggedised operations.
Detecting Quishing Attacks with Machine Learning Techniques Through QR Code Analysis
May 06, 2025



The rise of QR code based phishing ("Quishing") poses a growing cybersecurity threat, as attackers increasingly exploit QR codes to bypass traditional phishing defenses. Existing detection methods predominantly focus on URL analysis, which requires the extraction of the QR code payload, and may inadvertently expose users to malicious content. Moreover, QR codes can encode various types of data beyond URLs, such as Wi-Fi credentials and payment information, making URL-based detection insufficient for broader security concerns. To address these gaps, we propose the first framework for quishing detection that directly analyzes QR code structure and pixel patterns without extracting the embedded content. We generated a dataset of phishing and benign QR codes and we used it to train and evaluate multiple machine learning models, including Logistic Regression, Decision Trees, Random Forest, Naive Bayes, LightGBM, and XGBoost. Our best-performing model (XGBoost) achieves an AUC of 0.9106, demonstrating the feasibility of QR-centric detection. Through feature importance analysis, we identify key visual indicators of malicious intent and refine our feature set by removing non-informative pixels, improving performance to an AUC of 0.9133 with a reduced feature space. Our findings reveal that the structural features of QR code correlate strongly with phishing risk. This work establishes a foundation for quishing mitigation and highlights the potential of direct QR analysis as a critical layer in modern phishing defenses.
Streamlining Systematic Reviews: A Novel Application of Large Language Models
Dec 14, 2024Systematic reviews (SRs) are essential for evidence-based guidelines but are often limited by the time-consuming nature of literature screening. We propose and evaluate an in-house system based on Large Language Models (LLMs) for automating both title/abstract and full-text screening, addressing a critical gap in the literature. Using a completed SR on Vitamin D and falls (14,439 articles), the LLM-based system employed prompt engineering for title/abstract screening and Retrieval-Augmented Generation (RAG) for full-text screening. The system achieved an article exclusion rate (AER) of 99.5%, specificity of 99.6%, a false negative rate (FNR) of 0%, and a negative predictive value (NPV) of 100%. After screening, only 78 articles required manual review, including all 20 identified by traditional methods, reducing manual screening time by 95.5%. For comparison, Rayyan, a commercial tool for title/abstract screening, achieved an AER of 72.1% and FNR of 5% when including articles Rayyan considered as undecided or likely to include. Lowering Rayyan's inclusion thresholds improved FNR to 0% but increased screening time. By addressing both screening phases, the LLM-based system significantly outperformed Rayyan and traditional methods, reducing total screening time to 25.5 hours while maintaining high accuracy. These findings highlight the transformative potential of LLMs in SR workflows by offering a scalable, efficient, and accurate solution, particularly for the full-text screening phase, which has lacked automation tools.
Large Multimodal Agents for Accurate Phishing Detection with Enhanced Token Optimization and Cost Reduction
Dec 03, 2024With the rise of sophisticated phishing attacks, there is a growing need for effective and economical detection solutions. This paper explores the use of large multimodal agents, specifically Gemini 1.5 Flash and GPT-4o mini, to analyze both URLs and webpage screenshots via APIs, thus avoiding the complexities of training and maintaining AI systems. Our findings indicate that integrating these two data types substantially enhances detection performance over using either type alone. However, API usage incurs costs per query that depend on the number of input and output tokens. To address this, we propose a two-tiered agentic approach: initially, one agent assesses the URL, and if inconclusive, a second agent evaluates both the URL and the screenshot. This method not only maintains robust detection performance but also significantly reduces API costs by minimizing unnecessary multi-input queries. Cost analysis shows that with the agentic approach, GPT-4o mini can process about 4.2 times as many websites per $100 compared to the multimodal approach (107,440 vs. 25,626), and Gemini 1.5 Flash can process about 2.6 times more websites (2,232,142 vs. 862,068). These findings underscore the significant economic benefits of the agentic approach over the multimodal method, providing a viable solution for organizations aiming to leverage advanced AI for phishing detection while controlling expenses.
To Ensemble or Not: Assessing Majority Voting Strategies for Phishing Detection with Large Language Models
Nov 29, 2024The effectiveness of Large Language Models (LLMs) significantly relies on the quality of the prompts they receive. However, even when processing identical prompts, LLMs can yield varying outcomes due to differences in their training processes. To leverage the collective intelligence of multiple LLMs and enhance their performance, this study investigates three majority voting strategies for text classification, focusing on phishing URL detection. The strategies are: (1) a prompt-based ensemble, which utilizes majority voting across the responses generated by a single LLM to various prompts; (2) a model-based ensemble, which entails aggregating responses from multiple LLMs to a single prompt; and (3) a hybrid ensemble, which combines the two methods by sending different prompts to multiple LLMs and then aggregating their responses. Our analysis shows that ensemble strategies are most suited in cases where individual components exhibit equivalent performance levels. However, when there is a significant discrepancy in individual performance, the effectiveness of the ensemble method may not exceed that of the highest-performing single LLM or prompt. In such instances, opting for ensemble techniques is not recommended.
Evaluating the Efficacy of Prompt-Engineered Large Multimodal Models Versus Fine-Tuned Vision Transformers in Image-Based Security Applications
Mar 26, 2024The success of Large Language Models (LLMs) has led to a parallel rise in the development of Large Multimodal Models (LMMs), such as Gemini-pro, which have begun to transform a variety of applications. These sophisticated multimodal models are designed to interpret and analyze complex data, integrating both textual and visual information on a scale previously unattainable, opening new avenues for a range of applications. This paper investigates the applicability and effectiveness of prompt-engineered Gemini-pro LMMs versus fine-tuned Vision Transformer (ViT) models in addressing critical security challenges. We focus on two distinct tasks: a visually evident task of detecting simple triggers, such as small squares in images, indicative of potential backdoors, and a non-visually evident task of malware classification through visual representations. Our results highlight a significant divergence in performance, with Gemini-pro falling short in accuracy and reliability when compared to fine-tuned ViT models. The ViT models, on the other hand, demonstrate exceptional accuracy, achieving near-perfect performance on both tasks. This study not only showcases the strengths and limitations of prompt-engineered LMMs in cybersecurity applications but also emphasizes the unmatched efficacy of fine-tuned ViT models for precise and dependable tasks.
Forecast Analysis of the COVID-19 Incidence in Lebanon: Prediction of Future Epidemiological Trends to Plan More Effective Control Programs
May 11, 2021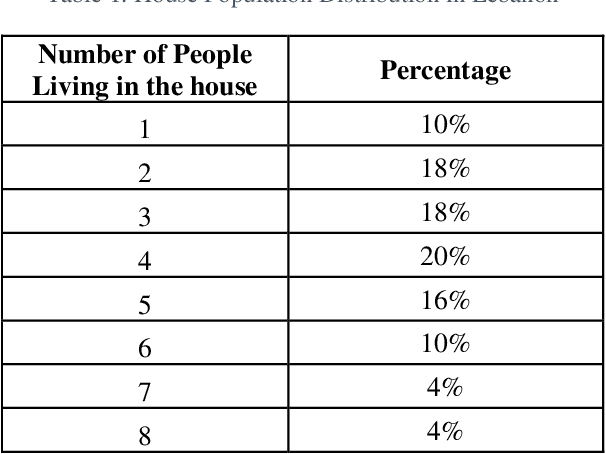
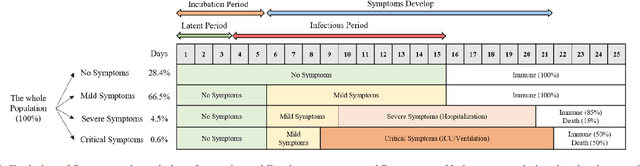
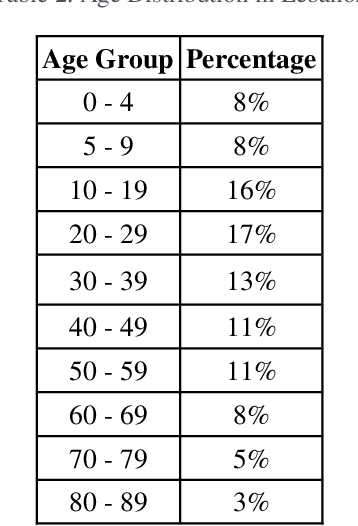
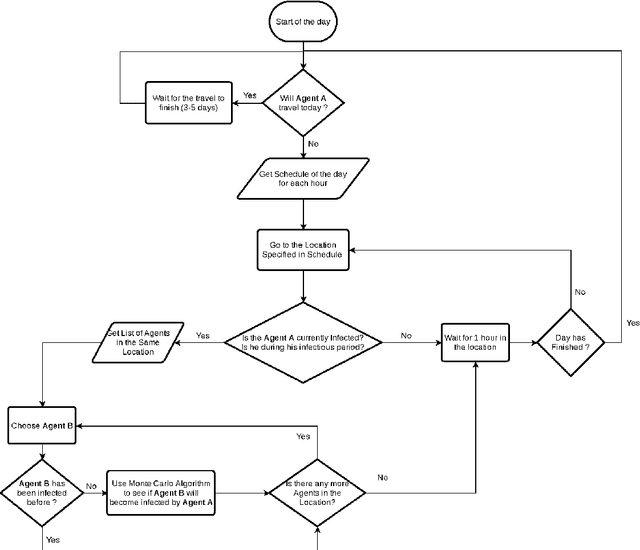
Ever since the COVID-19 pandemic started, all the governments have been trying to limit its effects on their citizens and countries. This pandemic was harsh on different levels for almost all populations worldwide and this is what drove researchers and scientists to get involved and work on several kinds of simulations to get a better insight into this virus and be able to stop it the earliest possible. In this study, we simulate the spread of COVID-19 in Lebanon using an Agent-Based Model where people are modeled as agents that have specific characteristics and behaviors determined from statistical distributions using Monte Carlo Algorithm. These agents can go into the world, interact with each other, and thus, infect each other. This is how the virus spreads. During the simulation, we can introduce different Non-Pharmaceutical Interventions - or more commonly NPIs - that aim to limit the spread of the virus (wearing a mask, closing locations, etc). Our Simulator was first validated on concepts (e.g. Flattening the Curve and Second Wave scenario), and then it was applied on the case of Lebanon. We studied the effect of opening schools and universities on the pandemic situation in the country since the Lebanese Ministry of Education is planning to do so progressively, starting from 21 April 2021. Based on the results we obtained, we conclude that it would be better to delay the school openings while the vaccination campaign is still slow in the country.