 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerahertz-Band MIMO-NOMA: Adaptive Superposition Coding and Subspace Detection
Mar 03, 2021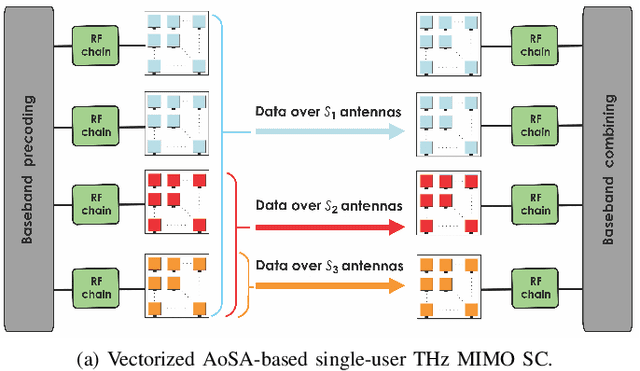
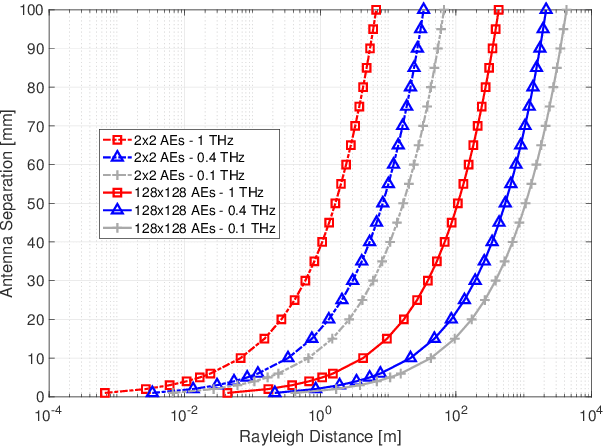
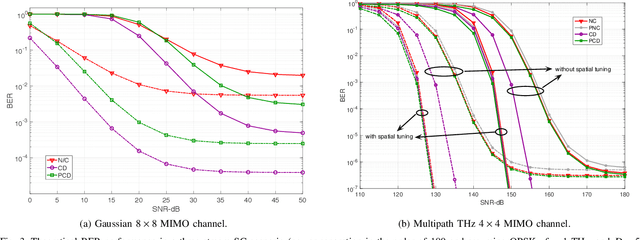
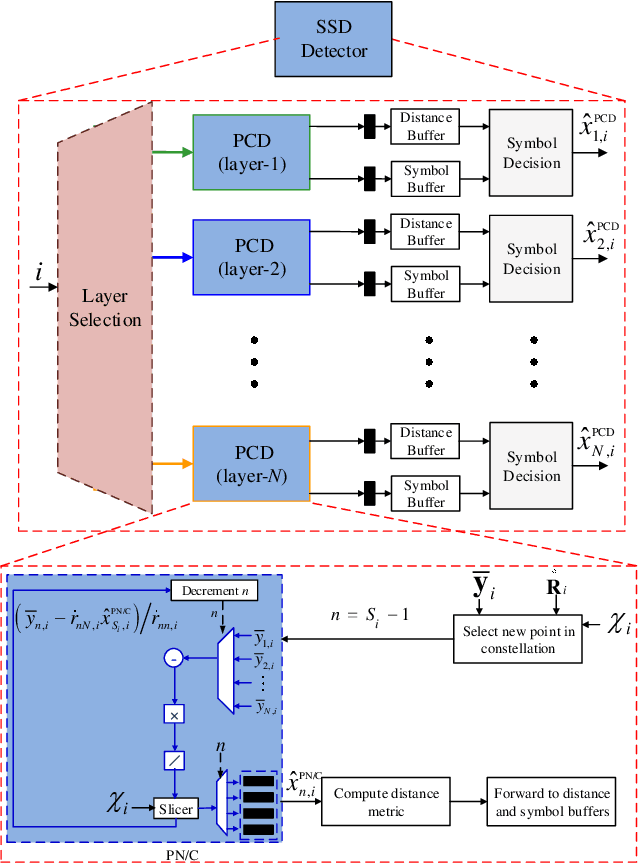
We consider the problem of efficient ultra-massive multiple-input multiple-output (UM-MIMO) data detection in terahertz (THz)-band non-orthogonal multiple access (NOMA) systems. We argue that the most common THz NOMA configuration is power-domain superposition coding over quasi-optical doubly-massive MIMO channels. We propose spatial tuning techniques that modify antenna subarray arrangements to enhance channel conditions. Towards recovering the superposed data at the receiver side, we propose a family of data detectors based on low-complexity channel matrix puncturing, in which higher-order detectors are dynamically formed from lower-order component detectors. We first detail the proposed solutions for the case of superposition coding of multiple streams in point-to-point THz MIMO links. We then extend the study to multi-user NOMA, in which randomly distributed users get grouped into narrow cell sectors and are allocated different power levels depending on their proximity to the base station. We show that successive interference cancellation is carried with minimal performance and complexity costs under spatial tuning. We derive approximate bit error rate (BER) equations, and we propose an architectural design to illustrate complexity reductions. Under typical THz conditions, channel puncturing introduces more than an order of magnitude reduction in BER at high signal-to-noise ratios while reducing complexity by approximately 90%.
Efficient Attitude Estimators: A Tutorial and Survey
Dec 07, 2020



Inertial sensors based on micro-electromechanical systems (MEMS) technology, such as accelerometers and angular rate sensors, are cost-effective solutions used in inertial navigation systems in a broad spectrum of applications that estimate position, velocity and orientation of a system with respect to an inertial reference frame. The task of an orientation filter is to compute an optimal solution for the attitude state, consisting of roll, pitch and yaw, through the fusion of angular rate, accelerometer, and magnetometer measurements. The aim of this paper is threefold: first, it serves researchers and practitioners in the signal processing community seeking the most appropriate attitude estimators that fulfills their needs, shedding light on the drawbacks and the advantages of a wide variety of designs. Second, it serves as a survey and tutorial for existing estimator designs in the literature, assessing their design aspects and components, and dissecting their hidden details for the benefit of researchers. Third, a comprehensive list of algorithms is discussed for a fully functional inertial navigation system, starting from the navigation equations and ending with the filter equations, keeping in mind their suitability for power limited embedded processors. The source code of all algorithms is published, with the aim of it being an out-of-box solution for researchers in the field. The reader will take away the following concepts from this article: understand the key concepts of an inertial navigation system; be able to implement and test a complete stand alone solution; be able to evaluate and understand different algorithms; understand the trade-offs between different filter architectures and techniques; and understand efficient embedded processing techniques, trends and opportunities.
Efficient Implementation of a Recognition System Using the Cortex Ventral Stream Model
Nov 21, 2017



In this paper, an efficient implementation for a recognition system based on the original HMAX model of the visual cortex is proposed. Various optimizations targeted to increase accuracy at the so-called layers S1, C1, and S2 of the HMAX model are proposed. At layer S1, all unimportant information such as illumination and expression variations are eliminated from the images. Each image is then convolved with 64 separable Gabor filters in the spatial domain. At layer C1, the minimum scales values are exploited to be embedded into the maximum ones using the additive embedding space. At layer S2, the prototypes are generated in a more efficient way using Partitioning Around Medoid (PAM) clustering algorithm. The impact of these optimizations in terms of accuracy and computational complexity was evaluated on the Caltech101 database, and compared with the baseline performance using support vector machine (SVM) and nearest neighbor (NN) classifiers. The results show that our model provides significant improvement in accuracy at the S1 layer by more than 10% where the computational complexity is also reduced. The accuracy is slightly increased for both approximations at the C1 and S2 layers.
* 10 pages