 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDC-ShadowNet: Single-Image Hard and Soft Shadow Removal Using Unsupervised Domain-Classifier Guided Network
Jul 21, 2022
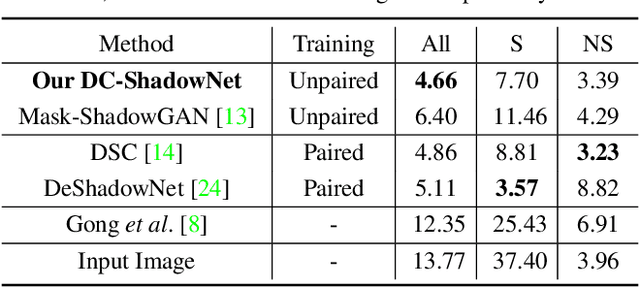
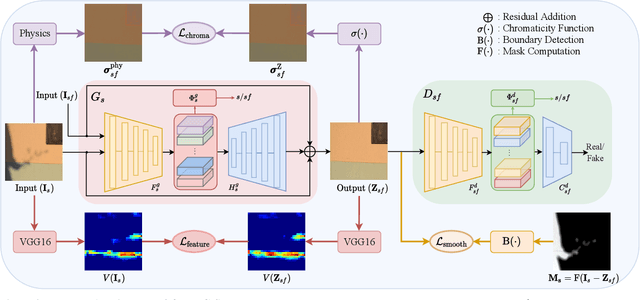
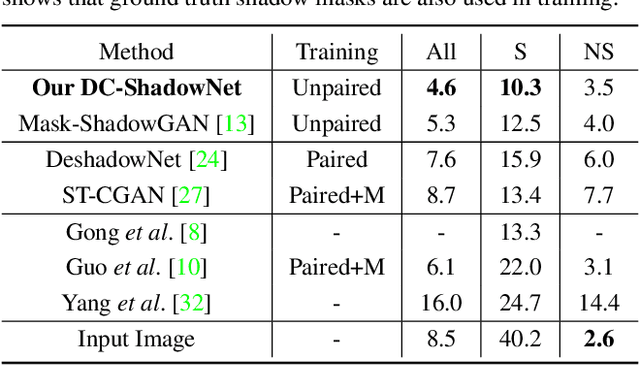
Shadow removal from a single image is generally still an open problem. Most existing learning-based methods use supervised learning and require a large number of paired images (shadow and corresponding non-shadow images) for training. A recent unsupervised method, Mask-ShadowGAN, addresses this limitation. However, it requires a binary mask to represent shadow regions, making it inapplicable to soft shadows. To address the problem, in this paper, we propose an unsupervised domain-classifier guided shadow removal network, DC-ShadowNet. Specifically, we propose to integrate a shadow/shadow-free domain classifier into a generator and its discriminator, enabling them to focus on shadow regions. To train our network, we introduce novel losses based on physics-based shadow-free chromaticity, shadow-robust perceptual features, and boundary smoothness. Moreover, we show that our unsupervised network can be used for test-time training that further improves the results. Our experiments show that all these novel components allow our method to handle soft shadows, and also to perform better on hard shadows both quantitatively and qualitatively than the existing state-of-the-art shadow removal methods.
* Accepted to ICCV2021, https://github.com/jinyeying/DC-ShadowNet-Hard-and-Soft-Shadow-Removal
Single-Image Camera Response Function Using Prediction Consistency and Gradual Refinement
Oct 08, 2020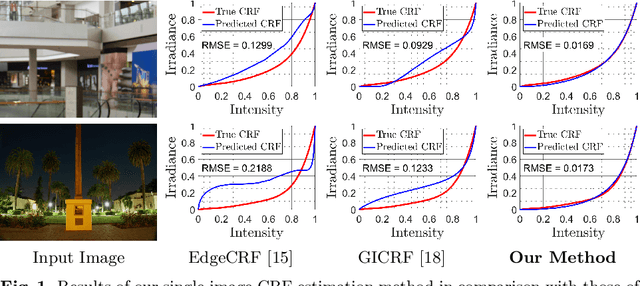
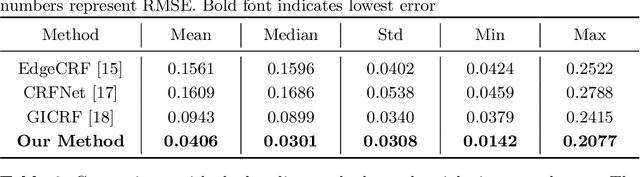
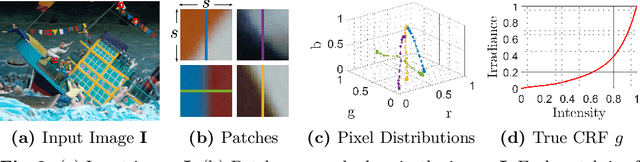
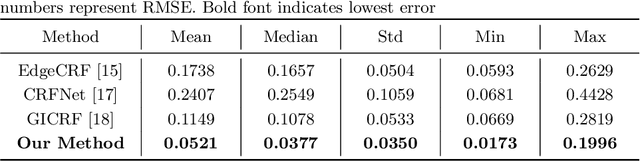
A few methods have been proposed to estimate the CRF from a single image, however most of them tend to fail in handling general real images. For instance, EdgeCRF based on patches extracted from colour edges works effectively only when the presence of noise is insignificant, which is not the case for many real images; and, CRFNet, a recent method based on fully supervised deep learning works only for the CRFs that are in the training data, and hence fail to deal with other possible CRFs beyond the training data. To address these problems, we introduce a non-deep-learning method using prediction consistency and gradual refinement. First, we rely more on the patches of the input image that provide more consistent predictions. If the predictions from a patch are more consistent, it means that the patch is likely to be less affected by noise or any inferior colour combinations, and hence, it can be more reliable for CRF estimation. Second, we employ a gradual refinement scheme in which we start from a simple CRF model to generate a result which is more robust to noise but less accurate, and then we gradually increase the model's complexity to improve the estimation. This is because a simple model, while being less accurate, overfits less to noise than a complex model does. Our experiments confirm that our method outperforms the existing single-image methods for both daytime and nighttime real images.
Optical Flow in Dense Foggy Scenes using Semi-Supervised Learning
Apr 04, 2020
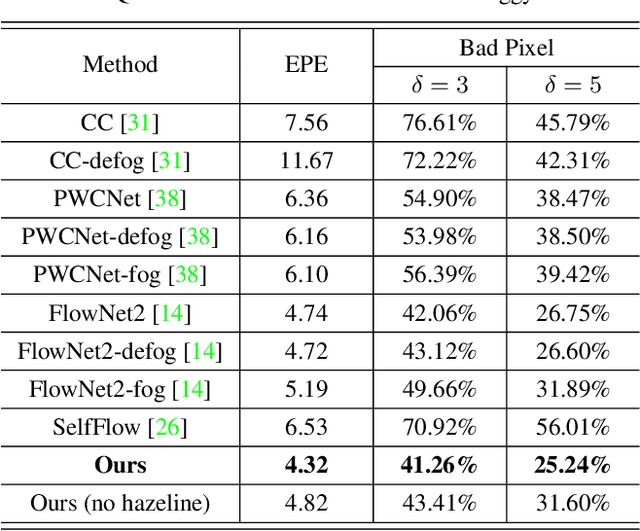
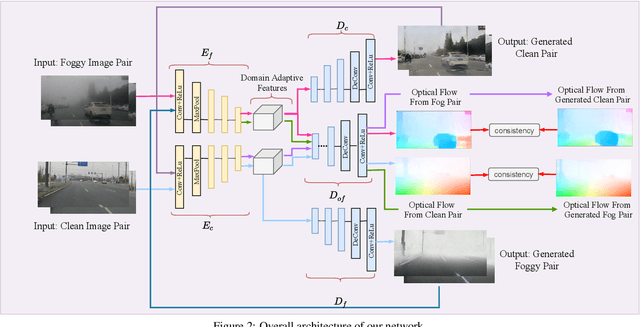
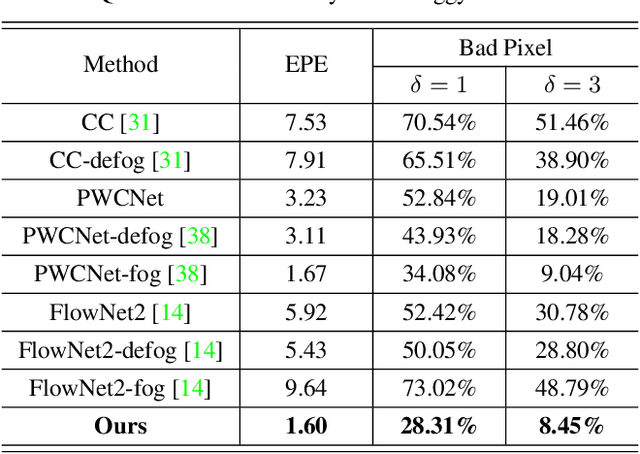
In dense foggy scenes, existing optical flow methods are erroneous. This is due to the degradation caused by dense fog particles that break the optical flow basic assumptions such as brightness and gradient constancy. To address the problem, we introduce a semi-supervised deep learning technique that employs real fog images without optical flow ground-truths in the training process. Our network integrates the domain transformation and optical flow networks in one framework. Initially, given a pair of synthetic fog images, its corresponding clean images and optical flow ground-truths, in one training batch we train our network in a supervised manner. Subsequently, given a pair of real fog images and a pair of clean images that are not corresponding to each other (unpaired), in the next training batch, we train our network in an unsupervised manner. We then alternate the training of synthetic and real data iteratively. We use real data without ground-truths, since to have ground-truths in such conditions is intractable, and also to avoid the overfitting problem of synthetic data training, where the knowledge learned on synthetic data cannot be generalized to real data testing. Together with the network architecture design, we propose a new training strategy that combines supervised synthetic-data training and unsupervised real-data training. Experimental results show that our method is effective and outperforms the state-of-the-art methods in estimating optical flow in dense foggy scenes.
Depth Estimation in Nighttime using Stereo-Consistent Cyclic Translations
Sep 30, 2019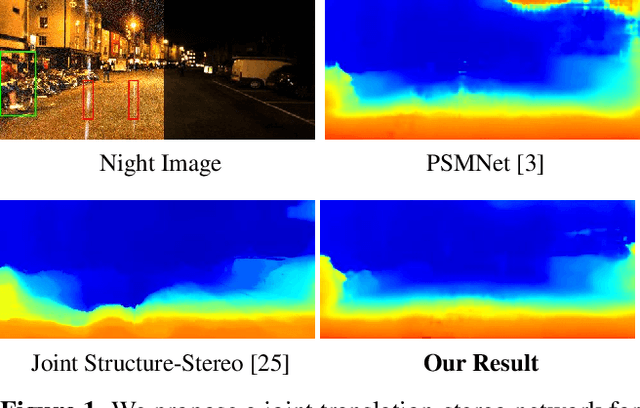
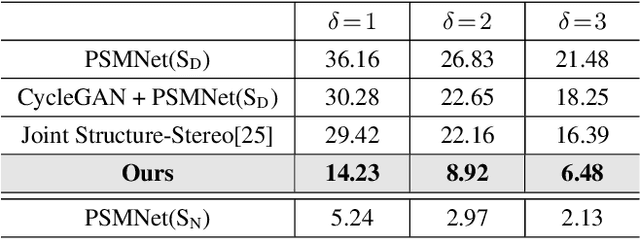
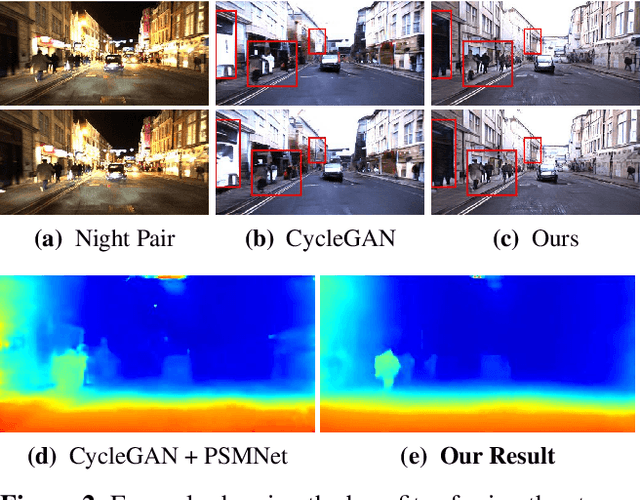
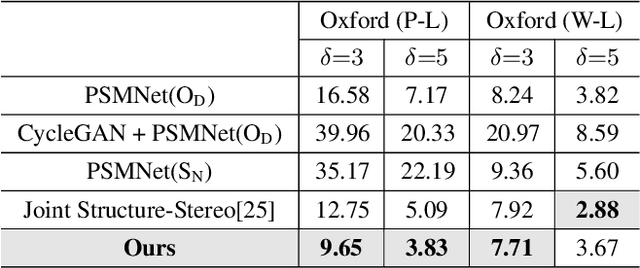
Most existing methods of depth from stereo are designed for daytime scenes, where the lighting can be assumed to be sufficiently bright and more or less uniform. Unfortunately, this assumption does not hold for nighttime scenes, causing the existing methods to be erroneous when deployed in nighttime. Nighttime is not only about low light, but also about glow, glare, non-uniform distribution of light, etc. One of the possible solutions is to train a network on nighttime images in a fully supervised manner. However, to obtain proper disparity ground-truths that are dense, independent from glare/glow, and can have sufficiently far depth ranges is extremely intractable. In this paper, to address the problem of depth from stereo in nighttime, we introduce a joint translation and stereo network that is robust to nighttime conditions. Our method uses no direct supervision and does not require ground-truth disparities of the nighttime training images. First, we utilize a translation network that can render realistic nighttime stereo images from given daytime stereo images. Second, we train a stereo network on the rendered nighttime images using the available disparity supervision from the daytime images, and simultaneously also train the translation network to gradually improve the rendered nighttime images. We introduce a stereo-consistency constraint into our translation network to ensure that the translated pairs are stereo-consistent. Our experiments show that our joint translation-stereo network outperforms the state-of-the-art methods.