 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel2Mesh++: 3D Mesh Generation and Refinement from Multi-View Images
Apr 21, 2022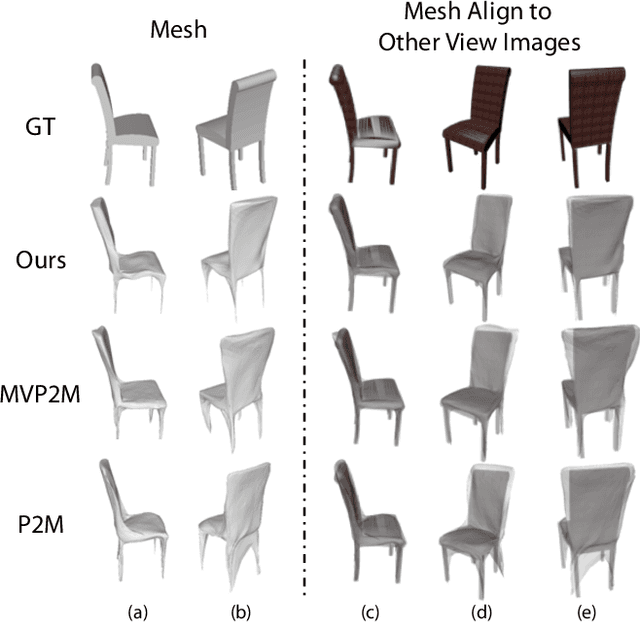
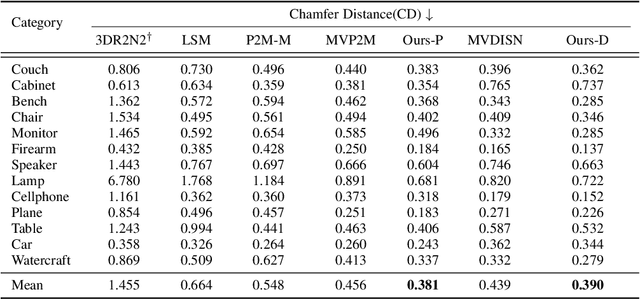
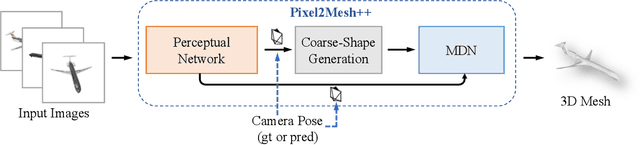
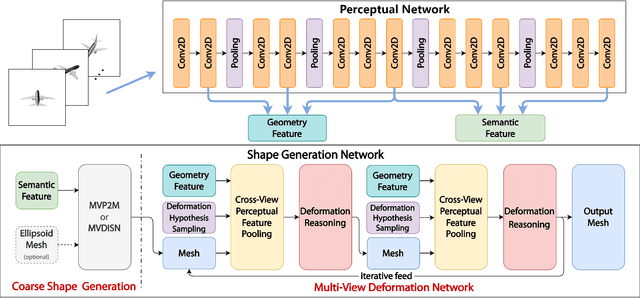
We study the problem of shape generation in 3D mesh representation from a small number of color images with or without camera poses. While many previous works learn to hallucinate the shape directly from priors, we adopt to further improve the shape quality by leveraging cross-view information with a graph convolution network. Instead of building a direct mapping function from images to 3D shape, our model learns to predict series of deformations to improve a coarse shape iteratively. Inspired by traditional multiple view geometry methods, our network samples nearby area around the initial mesh's vertex locations and reasons an optimal deformation using perceptual feature statistics built from multiple input images. Extensive experiments show that our model produces accurate 3D shapes that are not only visually plausible from the input perspectives, but also well aligned to arbitrary viewpoints. With the help of physically driven architecture, our model also exhibits generalization capability across different semantic categories, and the number of input images. Model analysis experiments show that our model is robust to the quality of the initial mesh and the error of camera pose, and can be combined with a differentiable renderer for test-time optimization.
Video Depth Estimation by Fusing Flow-to-Depth Proposals
Dec 30, 2019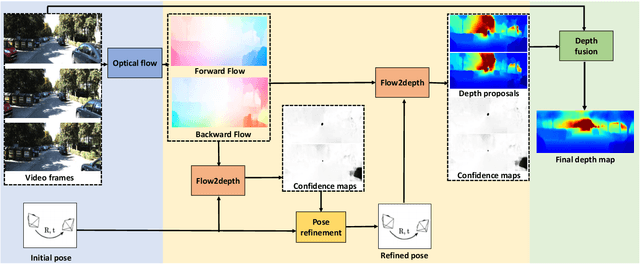
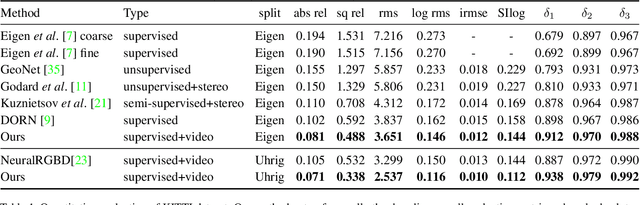
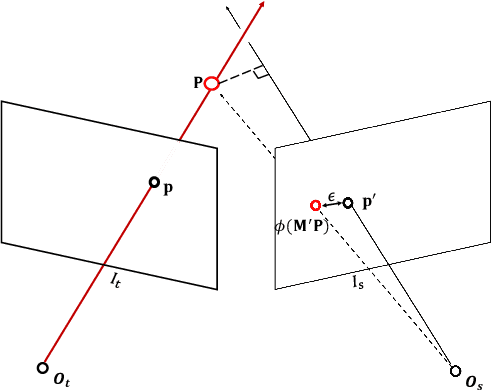

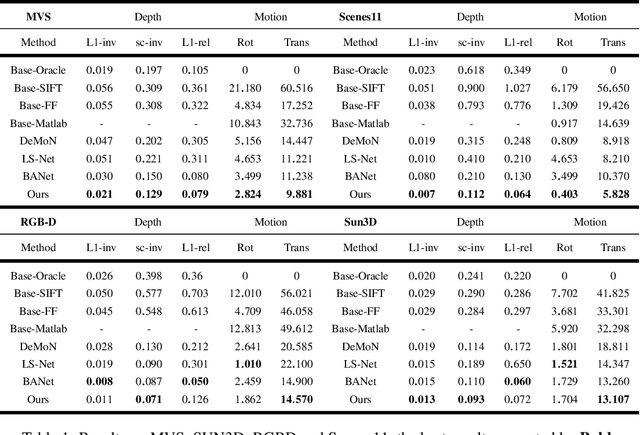
We present an approach with a novel differentiable flow-to-depth layer for video depth estimation. The model consists of a flow-to-depth layer, a camera pose refinement module, and a depth fusion network. Given optical flow and camera pose, our flow-to-depth layer generates depth proposals and the corresponding confidence maps by explicitly solving an epipolar geometry optimization problem. Unlike other methods, our flow-to-depth layer is differentiable, and thus we can refine camera poses by maximizing the aggregated confidence in camera pose refinement module. Our depth fusion network can utilize depth proposals and their confidence maps inferred from different adjacent frames to produce the final depth map. Furthermore, the depth fusion network can additionally take the depth proposals generated by other methods to improve the results further. The experiments on three public datasets show that our approach outperforms state-of-the-art depth estimation methods, and has strong generalization capability: our model trained on KITTI performs well on the unseen Waymo dataset while other methods degenerate a lot.
DeepSFM: Structure From Motion Via Deep Bundle Adjustment
Dec 20, 2019


Structure from motion (SfM) is an essential computer vision problem which has not been well handled by deep learning. One of the promising trends is to apply explicit structural constraint, e.g. 3D cost volume, into the network.In this work, we design a physical driven architecture, namely DeepSFM, inspired by traditional Bundle Adjustment (BA), which consists of two cost volume based architectures for depth and pose estimation respectively, iteratively running to improve both.In each cost volume, we encode not only photo-metric consistency across multiple input images, but also geometric consistency to ensure that depths from multiple views agree with each other.The explicit constraints on both depth (structure) and pose (motion), when combined with the learning components, bring the merit from both traditional BA and emerging deep learning technology.Extensive experiments on various datasets show that our model achieves the state-of-the-art performance on both depth and pose estimation with superior robustness against less number of inputs and the noise in initialization.
Neural Point Cloud Rendering via Multi-Plane Projection
Dec 10, 2019
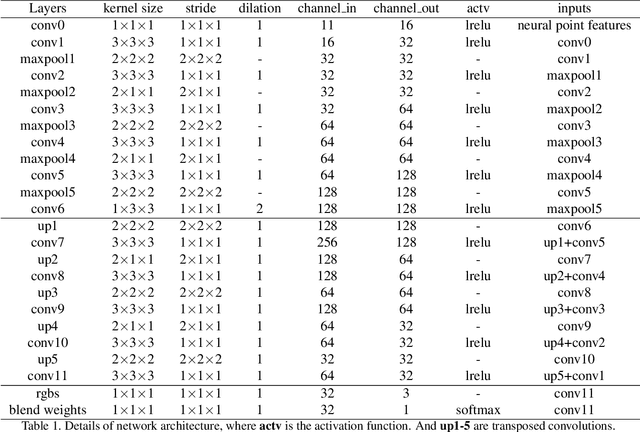

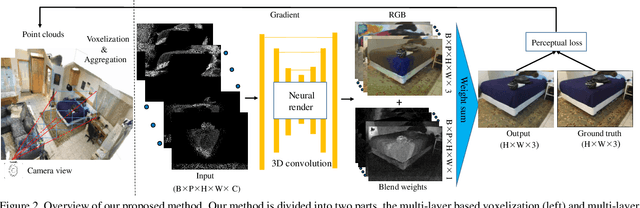
We present a new deep point cloud rendering pipeline through multi-plane projections. The input to the network is the raw point cloud of a scene and the output are image or image sequences from a novel view or along a novel camera trajectory. Unlike previous approaches that directly project features from 3D points onto 2D image domain, we propose to project these features into a layered volume of camera frustum. In this way, the visibility of 3D points can be automatically learnt by the network, such that ghosting effects due to false visibility check as well as occlusions caused by noise interferences are both avoided successfully. Next, the 3D feature volume is fed into a 3D CNN to produce multiple layers of images w.r.t. the space division in the depth directions. The layered images are then blended based on learned weights to produce the final rendering results. Experiments show that our network produces more stable renderings compared to previous methods, especially near the object boundaries. Moreover, our pipeline is robust to noisy and relatively sparse point cloud for a variety of challenging scenes.
PointPWC-Net: A Coarse-to-Fine Network for Supervised and Self-Supervised Scene Flow Estimation on 3D Point Clouds
Nov 27, 2019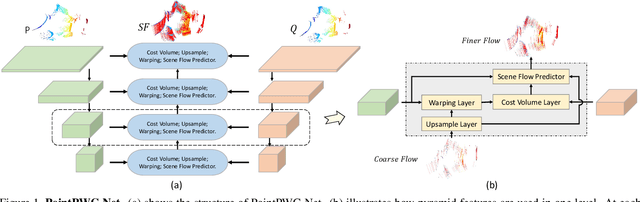
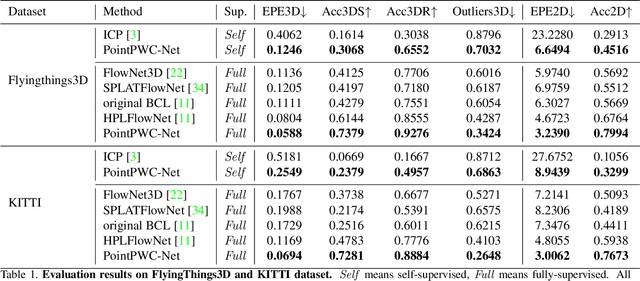
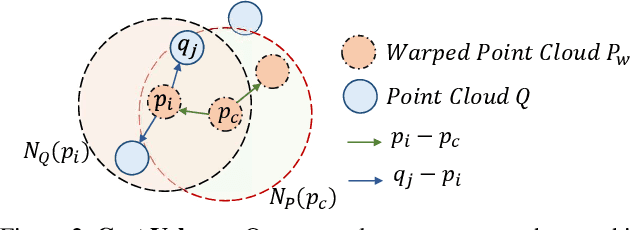
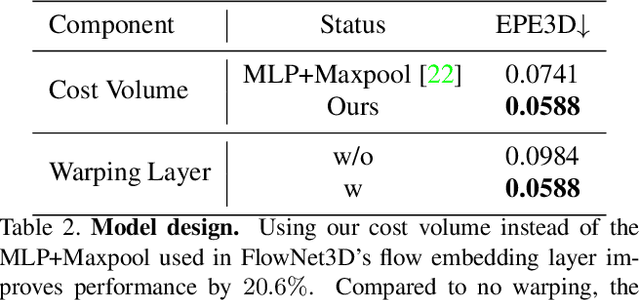
We propose a novel end-to-end deep scene flow model, called PointPWC-Net, on 3D point clouds in a coarse-to-fine fashion. Flow computed at the coarse level is upsampled and warped to a finer level, enabling the algorithm to accommodate for large motion without a prohibitive search space. We introduce novel cost volume, upsampling, and warping layers to efficiently handle 3D point cloud data. Unlike traditional cost volumes that require exhaustively computing all the cost values on a high-dimensional grid, our point-based formulation discretizes the cost volume onto input 3D points, and a PointConv operation efficiently computes convolutions on the cost volume. Experiment results on FlyingThings3D outperform the state-of-the-art by a large margin. We further explore novel self-supervised losses to train our model and achieve comparable results to state-of-the-art trained with supervised loss. Without any fine-tuning, our method also shows great generalization ability on KITTI Scene Flow 2015 dataset, outperforming all previous methods.
Deep Stereo using Adaptive Thin Volume Representation with Uncertainty Awareness
Nov 27, 2019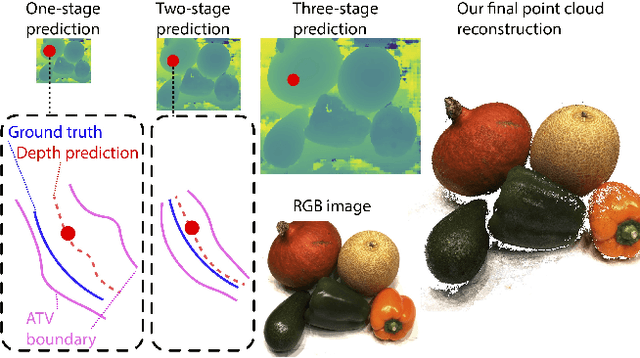
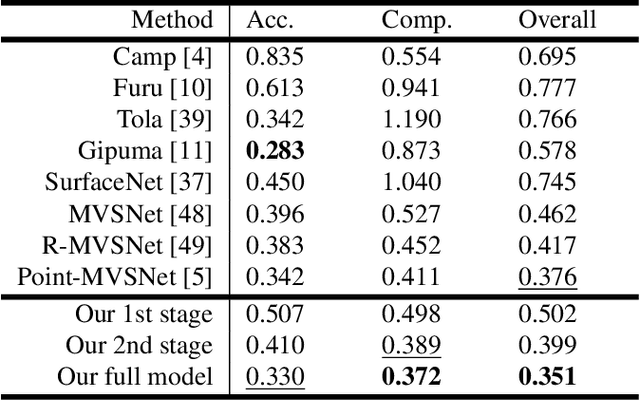
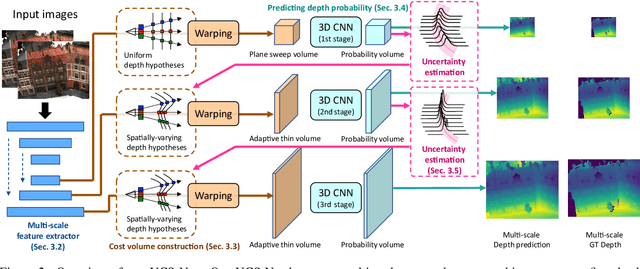

We present Uncertainty-aware Cascaded Stereo Network (UCS-Net) for 3D reconstruction from multiple RGB images. Multi-view stereo (MVS) aims to reconstruct fine-grained scene geometry from multi-view images. Previous learning-based MVS methods estimate per-view depth using plane sweep volumes with a fixed depth hypothesis at each plane; this generally requires densely sampled planes for desired accuracy, and it is very hard to achieve high-resolution depth. In contrast, we propose adaptive thin volumes (ATVs); in an ATV, the depth hypothesis of each plane is spatially varying, which adapts to the uncertainties of previous per-pixel depth predictions. Our UCS-Net has three stages: the first stage processes a small standard plane sweep volume to predict low-resolution depth; two ATVs are then used in the following stages to refine the depth with higher resolution and higher accuracy. Our ATV consists of only a small number of planes; yet, it efficiently partitions local depth ranges within learned small intervals. In particular, we propose to use variance-based uncertainty estimates to adaptively construct ATVs; this differentiable process introduces reasonable and fine-grained spatial partitioning. Our multi-stage framework progressively subdivides the vast scene space with increasing depth resolution and precision, which enables scene reconstruction with high completeness and accuracy in a coarse-to-fine fashion. We demonstrate that our method achieves superior performance compared with state-of-the-art benchmarks on various challenging datasets.
Pixel2Mesh++: Multi-View 3D Mesh Generation via Deformation
Aug 16, 2019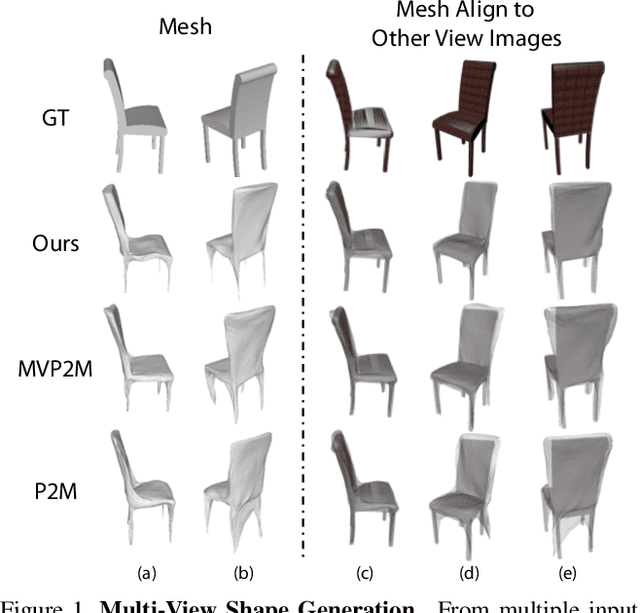
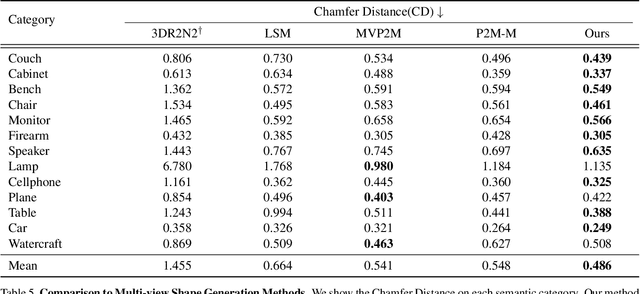
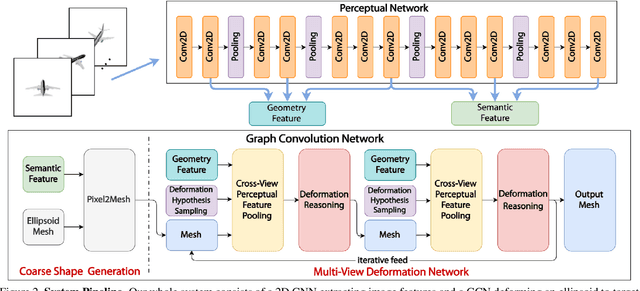
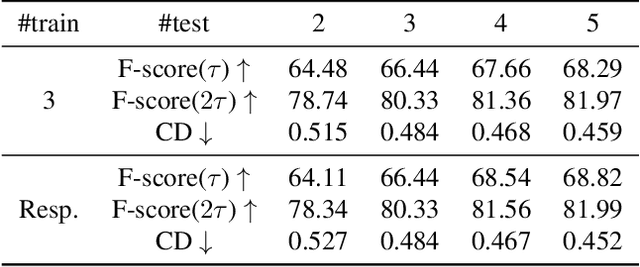
We study the problem of shape generation in 3D mesh representation from a few color images with known camera poses. While many previous works learn to hallucinate the shape directly from priors, we resort to further improving the shape quality by leveraging cross-view information with a graph convolutional network. Instead of building a direct mapping function from images to 3D shape, our model learns to predict series of deformations to improve a coarse shape iteratively. Inspired by traditional multiple view geometry methods, our network samples nearby area around the initial mesh's vertex locations and reasons an optimal deformation using perceptual feature statistics built from multiple input images. Extensive experiments show that our model produces accurate 3D shape that are not only visually plausible from the input perspectives, but also well aligned to arbitrary viewpoints. With the help of physically driven architecture, our model also exhibits generalization capability across different semantic categories, number of input images, and quality of mesh initialization.
3D Rigid Motion Segmentation with Mixed and Unknown Number of Models
Aug 16, 2019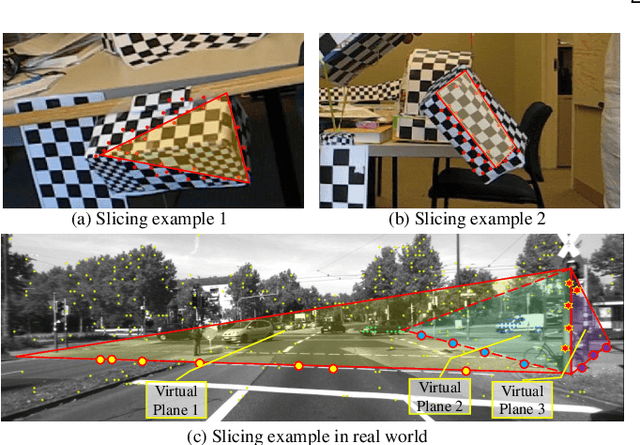
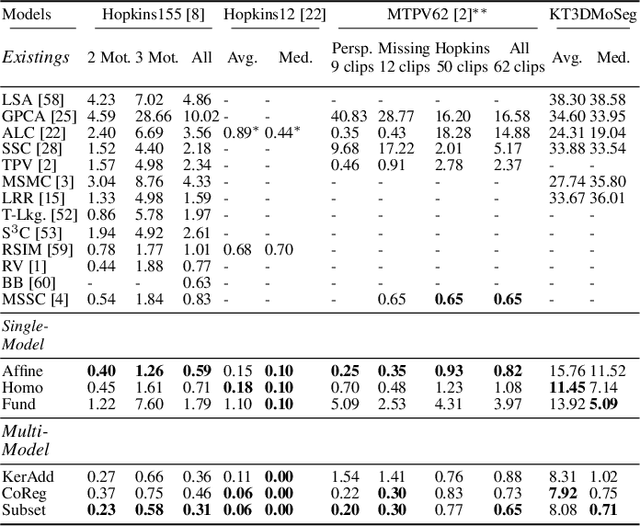

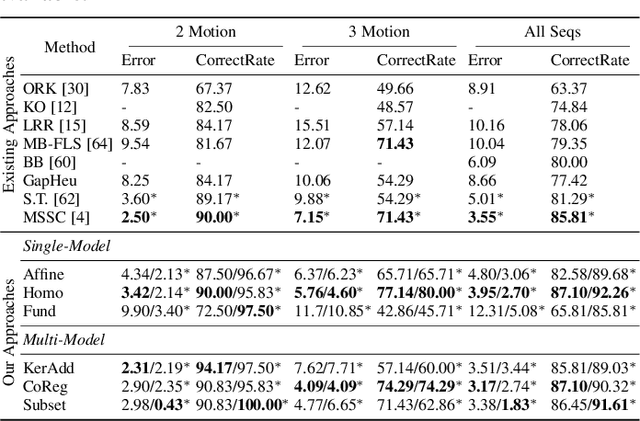
Many real-world video sequences cannot be conveniently categorized as general or degenerate; in such cases, imposing a false dichotomy in using the fundamental matrix or homography model for motion segmentation on video sequences would lead to difficulty. Even when we are confronted with a general scene-motion, the fundamental matrix approach as a model for motion segmentation still suffers from several defects, which we discuss in this paper. The full potential of the fundamental matrix approach could only be realized if we judiciously harness information from the simpler homography model. From these considerations, we propose a multi-model spectral clustering framework that synergistically combines multiple models (homography and fundamental matrix) together. We show that the performance can be substantially improved in this way. For general motion segmentation tasks, the number of independently moving objects is often unknown a priori and needs to be estimated from the observations. This is referred to as model selection and it is essentially still an open research problem. In this work, we propose a set of model selection criteria balancing data fidelity and model complexity. We perform extensive testing on existing motion segmentation datasets with both segmentation and model selection tasks, achieving state-of-the-art performance on all of them; we also put forth a more realistic and challenging dataset adapted from the KITTI benchmark, containing real-world effects such as strong perspectives and strong forward translations not seen in the traditional datasets.
What Do Single-view 3D Reconstruction Networks Learn?
May 09, 2019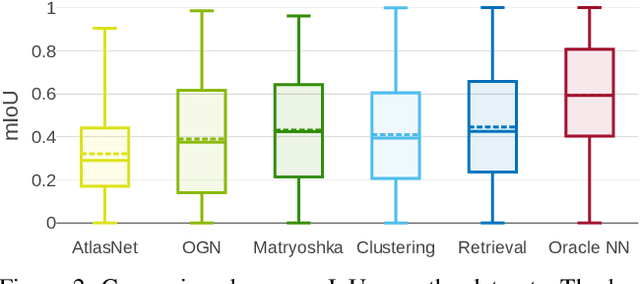
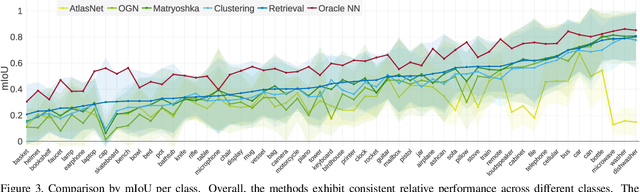
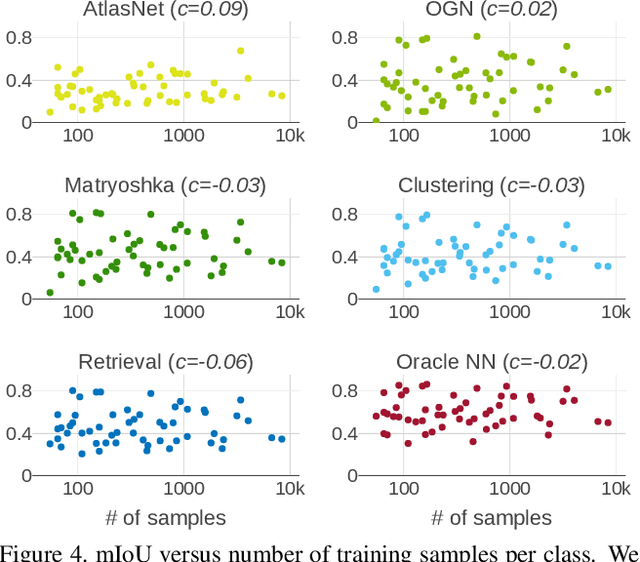

Convolutional networks for single-view object reconstruction have shown impressive performance and have become a popular subject of research. All existing techniques are united by the idea of having an encoder-decoder network that performs non-trivial reasoning about the 3D structure of the output space. In this work, we set up two alternative approaches that perform image classification and retrieval respectively. These simple baselines yield better results than state-of-the-art methods, both qualitatively and quantitatively. We show that encoder-decoder methods are statistically indistinguishable from these baselines, thus indicating that the current state of the art in single-view object reconstruction does not actually perform reconstruction but image classification. We identify aspects of popular experimental procedures that elicit this behavior and discuss ways to improve the current state of research.
Learning for Multi-Type Subspace Clustering
Apr 03, 2019

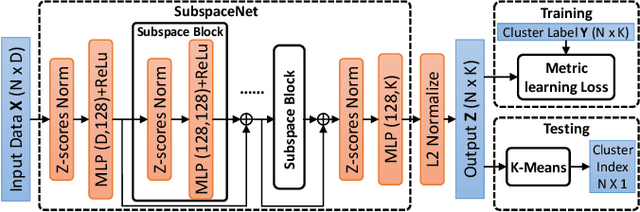
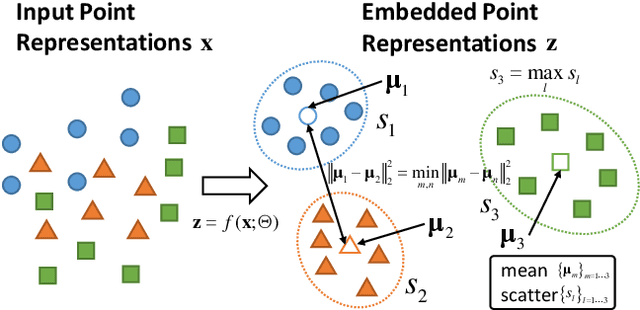
Subspace clustering has been extensively studied from the hypothesis-and-test, algebraic, and spectral clustering based perspectives. Most assume that only a single type/class of subspace is present. Generalizations to multiple types are non-trivial, plagued by challenges such as choice of types and numbers of models, sampling imbalance and parameter tuning. In this work, we formulate the multi-type subspace clustering problem as one of learning non-linear subspace filters via deep multi-layer perceptrons (mlps). The response to the learnt subspace filters serve as the feature embedding that is clustering-friendly, i.e., points of the same clusters will be embedded closer together through the network. For inference, we apply K-means to the network output to cluster the data. Experiments are carried out on both synthetic and real world multi-type fitting problems, producing state-of-the-art results.