 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchScene: Patch-based Voxel Diffusion for Large-Scale Scene Completion
Jun 02, 2026We propose PatchScene, a novel diffusion-based framework for large-scale LiDAR scene completion. Unlike existing methods that rely on global latent representations or dense voxel grids, PatchScene adopts a patch-based voxel diffusion paradigm that explicitly generates fine-grained geometry within localized 3D regions. To ensure coherent reconstruction at both spatial and temporal scales, we introduce a confidence-guided spatio-temporal fusion mechanism that integrates overlapping patches and adjacent frames in a unified generative process. Furthermore, we design an Annular-Flow diffusion strategy that leverages the radial density pattern of LiDAR scans to progressively propagate high-fidelity information from near-range to far-range regions, enabling spatially unbounded scene completion. Extensive experiments on the SemanticKITTI benchmark demonstrate that PatchScene achieves state-of-the-art performance across all standard metrics, surpassing previous approaches in both geometric accuracy and temporal consistency. Remarkably, the model trained on 20 m LiDAR ranges generalizes effectively to 50 m scenes without retraining, highlighting its strong scalability and generalization capability for real-world autonomous driving applications.
Cosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
Photon-Driven Neural Path Guiding
Oct 05, 2020
Although Monte Carlo path tracing is a simple and effective algorithm to synthesize photo-realistic images, it is often very slow to converge to noise-free results when involving complex global illumination. One of the most successful variance-reduction techniques is path guiding, which can learn better distributions for importance sampling to reduce pixel noise. However, previous methods require a large number of path samples to achieve reliable path guiding. We present a novel neural path guiding approach that can reconstruct high-quality sampling distributions for path guiding from a sparse set of samples, using an offline trained neural network. We leverage photons traced from light sources as the input for sampling density reconstruction, which is highly effective for challenging scenes with strong global illumination. To fully make use of our deep neural network, we partition the scene space into an adaptive hierarchical grid, in which we apply our network to reconstruct high-quality sampling distributions for any local region in the scene. This allows for highly efficient path guiding for any path bounce at any location in path tracing. We demonstrate that our photon-driven neural path guiding method can generalize well on diverse challenging testing scenes that are not seen in training. Our approach achieves significantly better rendering results of testing scenes than previous state-of-the-art path guiding methods.
Survey: Machine Learning in Production Rendering
May 26, 2020In the past few years, machine learning-based approaches have had some great success for rendering animated feature films. This survey summarizes several of the most dramatic improvements in using deep neural networks over traditional rendering methods, such as better image quality and lower computational overhead. More specifically, this survey covers the fundamental principles of machine learning and its applications, such as denoising, path guiding, rendering participating media, and other notoriously difficult light transport situations. Some of these techniques have already been used in the latest released animations while others are still in the continuing development by researchers in both academia and movie studios. Although learning-based rendering methods still have some open issues, they have already demonstrated promising performance in multiple parts of the rendering pipeline, and people are continuously making new attempts.
Deep Photon Mapping
Apr 25, 2020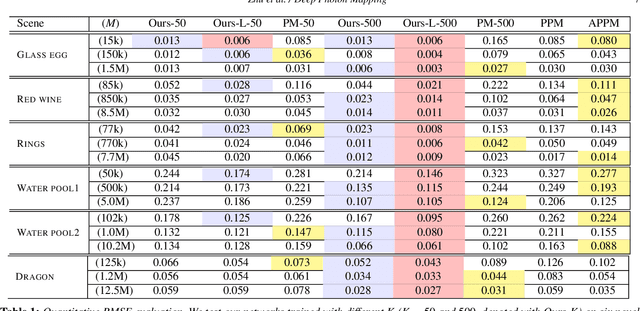
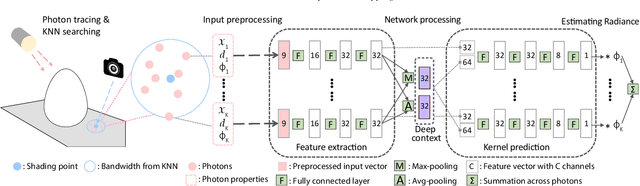


Recently, deep learning-based denoising approaches have led to dramatic improvements in low sample-count Monte Carlo rendering. These approaches are aimed at path tracing, which is not ideal for simulating challenging light transport effects like caustics, where photon mapping is the method of choice. However, photon mapping requires very large numbers of traced photons to achieve high-quality reconstructions. In this paper, we develop the first deep learning-based method for particle-based rendering, and specifically focus on photon density estimation, the core of all particle-based methods. We train a novel deep neural network to predict a kernel function to aggregate photon contributions at shading points. Our network encodes individual photons into per-photon features, aggregates them in the neighborhood of a shading point to construct a photon local context vector, and infers a kernel function from the per-photon and photon local context features. This network is easy to incorporate in many previous photon mapping methods (by simply swapping the kernel density estimator) and can produce high-quality reconstructions of complex global illumination effects like caustics with an order of magnitude fewer photons compared to previous photon mapping methods.
Deep Stereo using Adaptive Thin Volume Representation with Uncertainty Awareness
Nov 27, 2019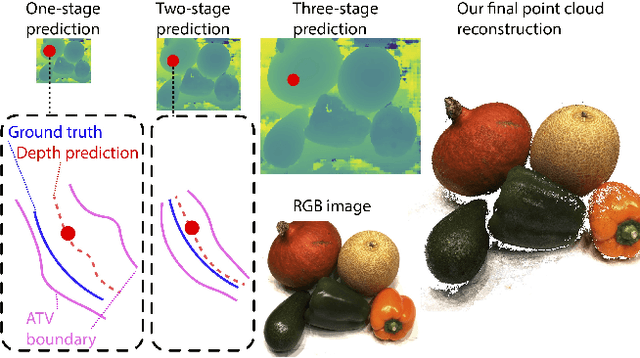
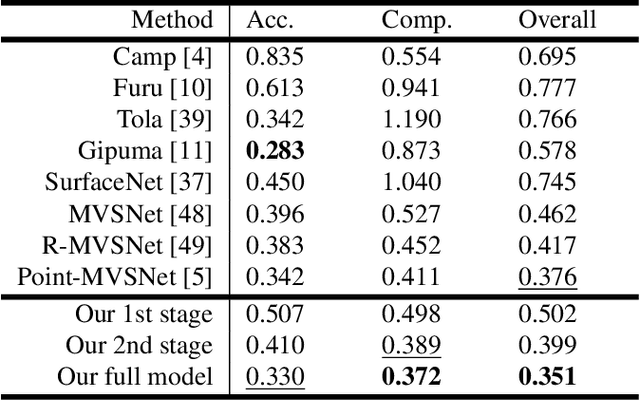
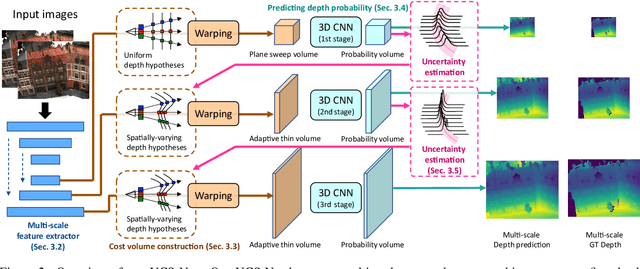

We present Uncertainty-aware Cascaded Stereo Network (UCS-Net) for 3D reconstruction from multiple RGB images. Multi-view stereo (MVS) aims to reconstruct fine-grained scene geometry from multi-view images. Previous learning-based MVS methods estimate per-view depth using plane sweep volumes with a fixed depth hypothesis at each plane; this generally requires densely sampled planes for desired accuracy, and it is very hard to achieve high-resolution depth. In contrast, we propose adaptive thin volumes (ATVs); in an ATV, the depth hypothesis of each plane is spatially varying, which adapts to the uncertainties of previous per-pixel depth predictions. Our UCS-Net has three stages: the first stage processes a small standard plane sweep volume to predict low-resolution depth; two ATVs are then used in the following stages to refine the depth with higher resolution and higher accuracy. Our ATV consists of only a small number of planes; yet, it efficiently partitions local depth ranges within learned small intervals. In particular, we propose to use variance-based uncertainty estimates to adaptively construct ATVs; this differentiable process introduces reasonable and fine-grained spatial partitioning. Our multi-stage framework progressively subdivides the vast scene space with increasing depth resolution and precision, which enables scene reconstruction with high completeness and accuracy in a coarse-to-fine fashion. We demonstrate that our method achieves superior performance compared with state-of-the-art benchmarks on various challenging datasets.
PartNet: A Large-scale Benchmark for Fine-grained and Hierarchical Part-level 3D Object Understanding
Dec 06, 2018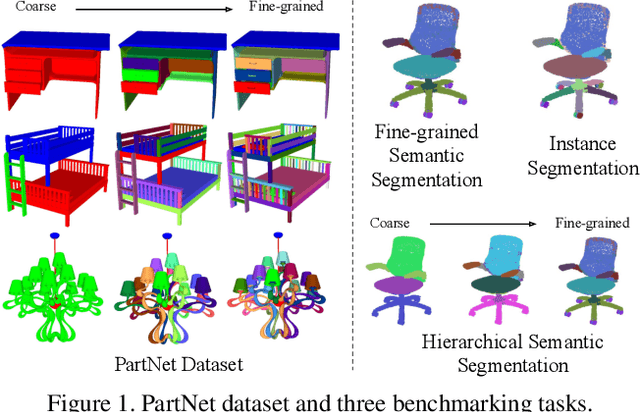


We present PartNet: a consistent, large-scale dataset of 3D objects annotated with fine-grained, instance-level, and hierarchical 3D part information. Our dataset consists of 573,585 part instances over 26,671 3D models covering 24 object categories. This dataset enables and serves as a catalyst for many tasks such as shape analysis, dynamic 3D scene modeling and simulation, affordance analysis, and others. Using our dataset, we establish three benchmarking tasks for evaluating 3D part recognition: fine-grained semantic segmentation, hierarchical semantic segmentation, and instance segmentation. We benchmark four state-of-the-art 3D deep learning algorithms for fine-grained semantic segmentation and three baseline methods for hierarchical semantic segmentation. We also propose a novel method for part instance segmentation and demonstrate its superior performance over existing methods.
Binary Ensemble Neural Network: More Bits per Network or More Networks per Bit?
Jun 20, 2018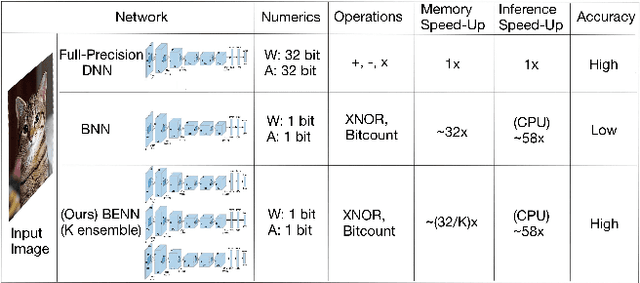

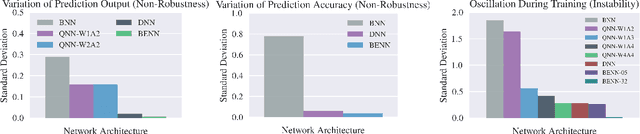

Binary neural networks (BNN) have been studied extensively since they run dramatically faster at lower memory and power consumption than floating-point networks, thanks to the efficiency of bit operations. However, contemporary BNNs whose weights and activations are both single bits suffer from severe accuracy degradation. To understand why, we investigate the representation ability, speed and bias/variance of BNNs through extensive experiments. We conclude that the error of BNNs is predominantly caused by the intrinsic instability (training time) and non-robustness (train \& test time). Inspired by this investigation, we propose the Binary Ensemble Neural Network (BENN) which leverages ensemble methods to improve the performance of BNNs with limited efficiency cost. While ensemble techniques have been broadly believed to be only marginally helpful for strong classifiers such as deep neural networks, our analyses and experiments show that they are naturally a perfect fit to boost BNNs. We find that our BENN, which is faster and much more robust than state-of-the-art binary networks, can even surpass the accuracy of the full-precision floating number network with the same architecture.