 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiLo-VLA: Compositional Long-Horizon Manipulation via Linked Object-Centric Policies
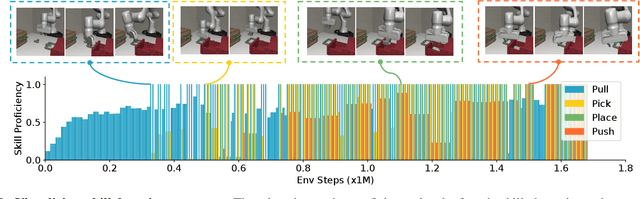
Feb 25, 2026General-purpose robots must master long-horizon manipulation, defined as tasks involving multiple kinematic structure changes (e.g., attaching or detaching objects) in unstructured environments. While Vision-Language-Action (VLA) models offer the potential to master diverse atomic skills, they struggle with the combinatorial complexity of sequencing them and are prone to cascading failures due to environmental sensitivity. To address these challenges, we propose LiLo-VLA (Linked Local VLA), a modular framework capable of zero-shot generalization to novel long-horizon tasks without ever being trained on them. Our approach decouples transport from interaction: a Reaching Module handles global motion, while an Interaction Module employs an object-centric VLA to process isolated objects of interest, ensuring robustness against irrelevant visual features and invariance to spatial configurations. Crucially, this modularity facilitates robust failure recovery through dynamic replanning and skill reuse, effectively mitigating the cascading errors common in end-to-end approaches. We introduce a 21-task simulation benchmark consisting of two challenging suites: LIBERO-Long++ and Ultra-Long. In these simulations, LiLo-VLA achieves a 69% average success rate, outperforming Pi0.5 by 41% and OpenVLA-OFT by 67%. Furthermore, real-world evaluations across 8 long-horizon tasks demonstrate an average success rate of 85%. Project page: https://yy-gx.github.io/LiLo-VLA/.
C2TE: Coordinated Constrained Task Execution Design for Ordering-Flexible Multi-Vehicle Platoon Merging
Jun 16, 2025In this paper, we propose a distributed coordinated constrained task execution (C2TE) algorithm that enables a team of vehicles from different lanes to cooperatively merge into an {\it ordering-flexible platoon} maneuvering on the desired lane. Therein, the platoon is flexible in the sense that no specific spatial ordering sequences of vehicles are predetermined. To attain such a flexible platoon, we first separate the multi-vehicle platoon (MVP) merging mission into two stages, namely, pre-merging regulation and {\it ordering-flexible platoon} merging, and then formulate them into distributed constraint-based optimization problems. Particularly, by encoding longitudinal-distance regulation and same-lane collision avoidance subtasks into the corresponding control barrier function (CBF) constraints, the proposed algorithm in Stage 1 can safely enlarge sufficient longitudinal distances among adjacent vehicles. Then, by encoding lateral convergence, longitudinal-target attraction, and neighboring collision avoidance subtasks into CBF constraints, the proposed algorithm in Stage~2 can efficiently achieve the {\it ordering-flexible platoon}. Note that the {\it ordering-flexible platoon} is realized through the interaction of the longitudinal-target attraction and time-varying neighboring collision avoidance constraints simultaneously. Feasibility guarantee and rigorous convergence analysis are both provided under strong nonlinear couplings induced by flexible orderings. Finally, experiments using three autonomous mobile vehicles (AMVs) are conducted to verify the effectiveness and flexibility of the proposed algorithm, and extensive simulations are performed to demonstrate its robustness, adaptability, and scalability when tackling vehicles' sudden breakdown, new appearing, different number of lanes, mixed autonomy, and large-scale scenarios, respectively.
EgoMimic: Scaling Imitation Learning via Egocentric Video
Oct 31, 2024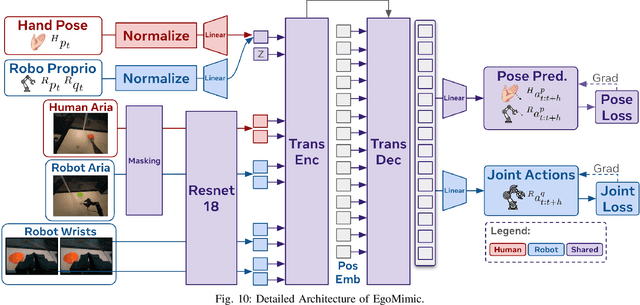


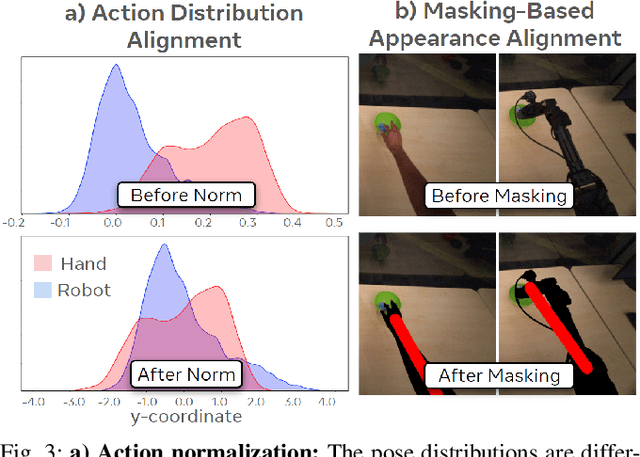
The scale and diversity of demonstration data required for imitation learning is a significant challenge. We present EgoMimic, a full-stack framework which scales manipulation via human embodiment data, specifically egocentric human videos paired with 3D hand tracking. EgoMimic achieves this through: (1) a system to capture human embodiment data using the ergonomic Project Aria glasses, (2) a low-cost bimanual manipulator that minimizes the kinematic gap to human data, (3) cross-domain data alignment techniques, and (4) an imitation learning architecture that co-trains on human and robot data. Compared to prior works that only extract high-level intent from human videos, our approach treats human and robot data equally as embodied demonstration data and learns a unified policy from both data sources. EgoMimic achieves significant improvement on a diverse set of long-horizon, single-arm and bimanual manipulation tasks over state-of-the-art imitation learning methods and enables generalization to entirely new scenes. Finally, we show a favorable scaling trend for EgoMimic, where adding 1 hour of additional hand data is significantly more valuable than 1 hour of additional robot data. Videos and additional information can be found at https://egomimic.github.io/
Coarse-to-Fine Detection of Multiple Seams for Robotic Welding
Aug 20, 2024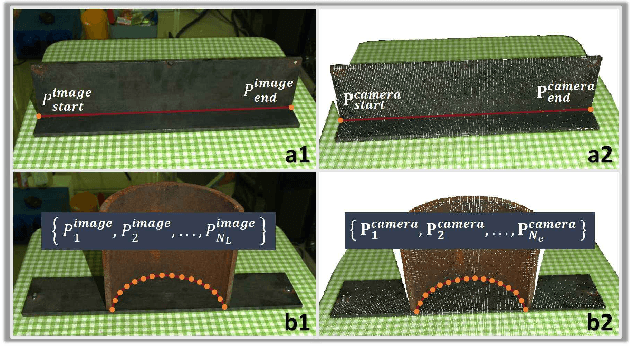
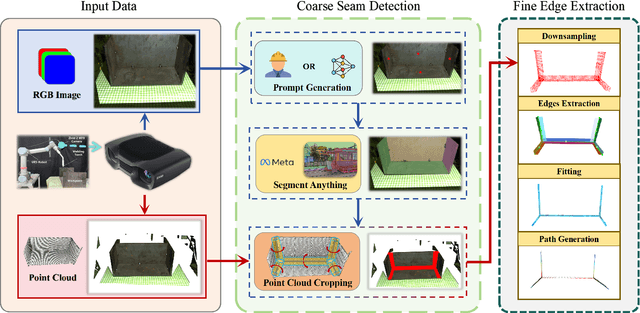

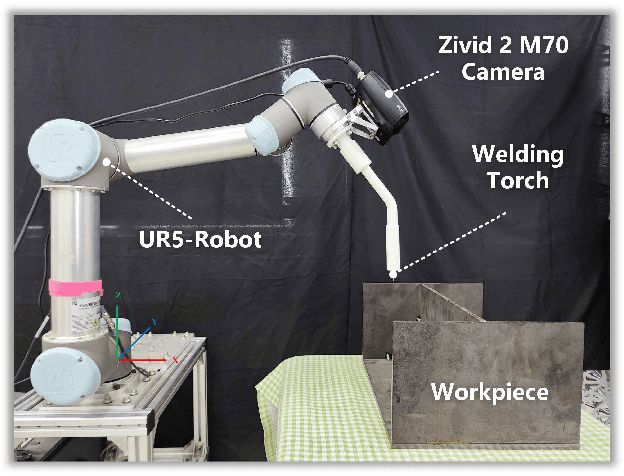
Efficiently detecting target weld seams while ensuring sub-millimeter accuracy has always been an important challenge in autonomous welding, which has significant application in industrial practice. Previous works mostly focused on recognizing and localizing welding seams one by one, leading to inferior efficiency in modeling the workpiece. This paper proposes a novel framework capable of multiple weld seams extraction using both RGB images and 3D point clouds. The RGB image is used to obtain the region of interest by approximately localizing the weld seams, and the point cloud is used to achieve the fine-edge extraction of the weld seams within the region of interest using region growth. Our method is further accelerated by using a pre-trained deep learning model to ensure both efficiency and generalization ability. The performance of the proposed method has been comprehensively tested on various workpieces featuring both linear and curved weld seams and in physical experiment systems. The results showcase considerable potential for real-world industrial applications, emphasizing the method's efficiency and effectiveness. Videos of the real-world experiments can be found at https://youtu.be/pq162HSP2D4.
A Survey of Optimization-based Task and Motion Planning: From Classical To Learning Approaches
Apr 05, 2024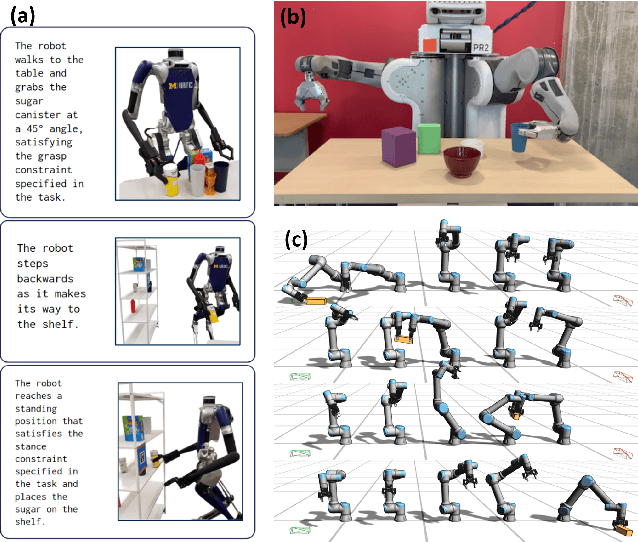
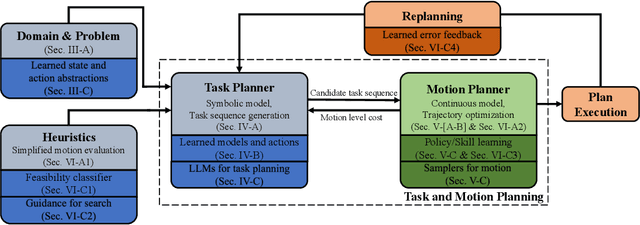
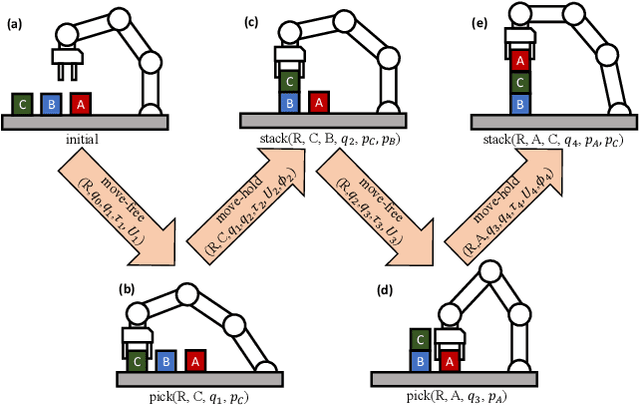
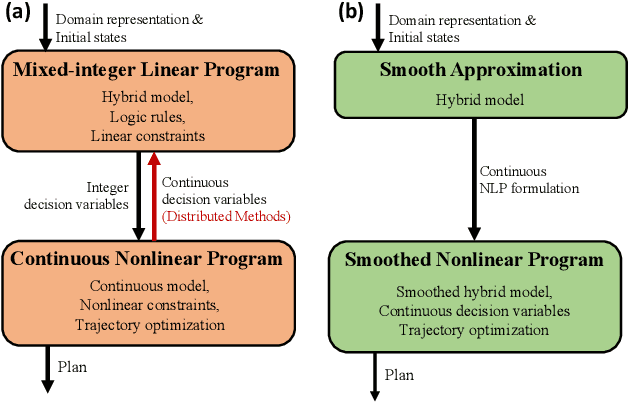
Task and Motion Planning (TAMP) integrates high-level task planning and low-level motion planning to equip robots with the autonomy to effectively reason over long-horizon, dynamic tasks. Optimization-based TAMP focuses on hybrid optimization approaches that define goal conditions via objective functions and are capable of handling open-ended goals, robotic dynamics, and physical interaction between the robot and the environment. Therefore, optimization-based TAMP is particularly suited to solve highly complex, contact-rich locomotion and manipulation problems. This survey provides a comprehensive review on optimization-based TAMP, covering (i) planning domain representations, including action description languages and temporal logic, (ii) individual solution strategies for components of TAMP, including AI planning and trajectory optimization (TO), and (iii) the dynamic interplay between logic-based task planning and model-based TO. A particular focus of this survey is to highlight the algorithm structures to efficiently solve TAMP, especially hierarchical and distributed approaches. Additionally, the survey emphasizes the synergy between the classical methods and contemporary learning-based innovations such as large language models. Furthermore, the future research directions for TAMP is discussed in this survey, highlighting both algorithmic and application-specific challenges.
NOD-TAMP: Multi-Step Manipulation Planning with Neural Object Descriptors
Nov 02, 2023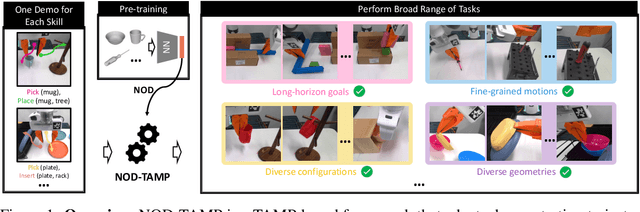
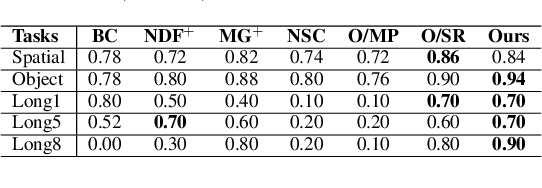
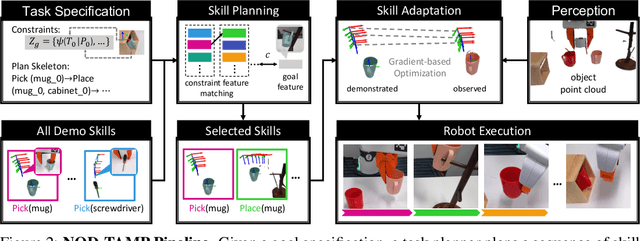
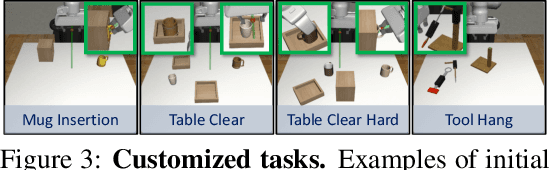
Developing intelligent robots for complex manipulation tasks in household and factory settings remains challenging due to long-horizon tasks, contact-rich manipulation, and the need to generalize across a wide variety of object shapes and scene layouts. While Task and Motion Planning (TAMP) offers a promising solution, its assumptions such as kinodynamic models limit applicability in novel contexts. Neural object descriptors (NODs) have shown promise in object and scene generalization but face limitations in addressing broader tasks. Our proposed TAMP-based framework, NOD-TAMP, extracts short manipulation trajectories from a handful of human demonstrations, adapts these trajectories using NOD features, and composes them to solve broad long-horizon tasks. Validated in a simulation environment, NOD-TAMP effectively tackles varied challenges and outperforms existing methods, establishing a cohesive framework for manipulation planning. For videos and other supplemental material, see the project website: https://sites.google.com/view/nod-tamp/.
Neural Field Dynamics Model for Granular Object Piles Manipulation
Nov 01, 2023We present a learning-based dynamics model for granular material manipulation. Inspired by the Eulerian approach commonly used in fluid dynamics, our method adopts a fully convolutional neural network that operates on a density field-based representation of object piles and pushers, allowing it to exploit the spatial locality of inter-object interactions as well as the translation equivariance through convolution operations. Furthermore, our differentiable action rendering module makes the model fully differentiable and can be directly integrated with a gradient-based trajectory optimization algorithm. We evaluate our model with a wide array of piles manipulation tasks both in simulation and real-world experiments and demonstrate that it significantly exceeds existing latent or particle-based methods in both accuracy and computation efficiency, and exhibits zero-shot generalization capabilities across various environments and tasks.
Learning to Discern: Imitating Heterogeneous Human Demonstrations with Preference and Representation Learning
Oct 22, 2023



Practical Imitation Learning (IL) systems rely on large human demonstration datasets for successful policy learning. However, challenges lie in maintaining the quality of collected data and addressing the suboptimal nature of some demonstrations, which can compromise the overall dataset quality and hence the learning outcome. Furthermore, the intrinsic heterogeneity in human behavior can produce equally successful but disparate demonstrations, further exacerbating the challenge of discerning demonstration quality. To address these challenges, this paper introduces Learning to Discern (L2D), an offline imitation learning framework for learning from demonstrations with diverse quality and style. Given a small batch of demonstrations with sparse quality labels, we learn a latent representation for temporally embedded trajectory segments. Preference learning in this latent space trains a quality evaluator that generalizes to new demonstrators exhibiting different styles. Empirically, we show that L2D can effectively assess and learn from varying demonstrations, thereby leading to improved policy performance across a range of tasks in both simulations and on a physical robot.
Zero-Shot Object Searching Using Large-scale Object Relationship Prior
Mar 10, 2023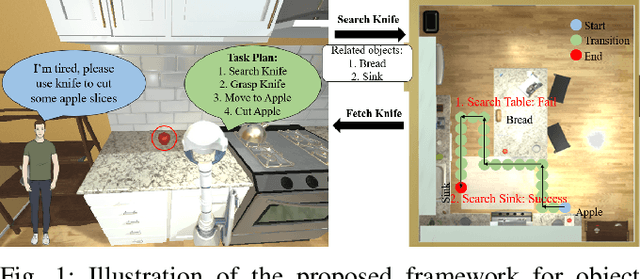
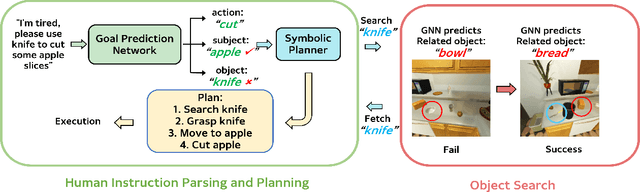
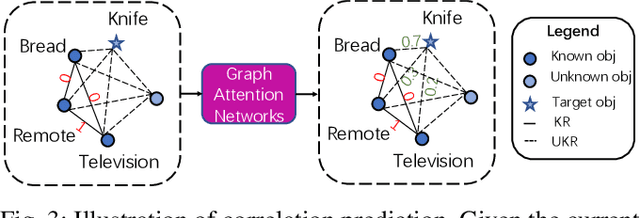

Home-assistant robots have been a long-standing research topic, and one of the biggest challenges is searching for required objects in housing environments. Previous object-goal navigation requires the robot to search for a target object category in an unexplored environment, which may not be suitable for home-assistant robots that typically have some level of semantic knowledge of the environment, such as the location of static furniture. In our approach, we leverage this knowledge and the fact that a target object may be located close to its related objects for efficient navigation. To achieve this, we train a graph neural network using the Visual Genome dataset to learn the object co-occurrence relationships and formulate the searching process as iteratively predicting the possible areas where the target object may be located. This approach is entirely zero-shot, meaning it doesn't require new accurate object correlation in the test environment. We empirically show that our method outperforms prior correlational object search algorithms. As our ultimate goal is to build fully autonomous assistant robots for everyday use, we further integrate the task planner for parsing natural language and generating task-completing plans with object navigation to execute human instructions. We demonstrate the effectiveness of our proposed pipeline in both the AI2-THOR simulator and a Stretch robot in a real-world environment.
Guided Skill Learning and Abstraction for Long-Horizon Manipulation
Oct 23, 2022


To assist with everyday human activities, robots must solve complex long-horizon tasks and generalize to new settings. Recent deep reinforcement learning (RL) methods show promises in fully autonomous learning, but they struggle to reach long-term goals in large environments. On the other hand, Task and Motion Planning (TAMP) approaches excel at solving and generalizing across long-horizon tasks, thanks to their powerful state and action abstractions. But they assume predefined skill sets, which limits their real-world applications. In this work, we combine the benefits of these two paradigms and propose an integrated task planning and skill learning framework named LEAGUE (Learning and Abstraction with Guidance). LEAGUE leverages symbolic interface of a task planner to guide RL-based skill learning and creates abstract state space to enable skill reuse. More importantly, LEAGUE learns manipulation skills in-situ of the task planning system, continuously growing its capability and the set of tasks that it can solve. We demonstrate LEAGUE on three challenging simulated task domains and show that LEAGUE outperforms baselines by a large margin, and that the learned skills can be reused to accelerate learning in new tasks and domains. Additional resource is available at https://bit.ly/3eUOx4N.