 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSigned Binarization: Unlocking Efficiency Through Repetition-Sparsity Trade-Off
Dec 04, 2023



Efficient inference of Deep Neural Networks (DNNs) on resource-constrained edge devices is essential. Quantization and sparsity are key algorithmic techniques that translate to repetition and sparsity within tensors at the hardware-software interface. This paper introduces the concept of repetition-sparsity trade-off that helps explain computational efficiency during inference. We propose Signed Binarization, a unified co-design framework that synergistically integrates hardware-software systems, quantization functions, and representation learning techniques to address this trade-off. Our results demonstrate that Signed Binarization is more accurate than binarization with the same number of non-zero weights. Detailed analysis indicates that signed binarization generates a smaller distribution of effectual (non-zero) parameters nested within a larger distribution of total parameters, both of the same type, for a DNN block. Finally, our approach achieves a 26% speedup on real hardware, doubles energy efficiency, and reduces density by 2.8x compared to binary methods for ResNet 18, presenting an alternative solution for deploying efficient models in resource-limited environments.
Learning to Discern: Imitating Heterogeneous Human Demonstrations with Preference and Representation Learning
Oct 22, 2023



Practical Imitation Learning (IL) systems rely on large human demonstration datasets for successful policy learning. However, challenges lie in maintaining the quality of collected data and addressing the suboptimal nature of some demonstrations, which can compromise the overall dataset quality and hence the learning outcome. Furthermore, the intrinsic heterogeneity in human behavior can produce equally successful but disparate demonstrations, further exacerbating the challenge of discerning demonstration quality. To address these challenges, this paper introduces Learning to Discern (L2D), an offline imitation learning framework for learning from demonstrations with diverse quality and style. Given a small batch of demonstrations with sparse quality labels, we learn a latent representation for temporally embedded trajectory segments. Preference learning in this latent space trains a quality evaluator that generalizes to new demonstrators exhibiting different styles. Empirically, we show that L2D can effectively assess and learn from varying demonstrations, thereby leading to improved policy performance across a range of tasks in both simulations and on a physical robot.
Signed Binary Weight Networks: Improving Efficiency of Binary Weight Networks by Exploiting Sparsity
Nov 25, 2022Efficient inference of Deep Neural Networks (DNNs) is essential to making AI ubiquitous. Two important algorithmic techniques have shown promise for enabling efficient inference - sparsity and binarization. These techniques translate into weight sparsity and weight repetition at the hardware-software level allowing the deployment of DNNs with critically low power and latency requirements. We propose a new method called signed-binary networks to improve further efficiency (by exploiting both weight sparsity and weight repetition) while maintaining similar accuracy. Our method achieves comparable accuracy on ImageNet and CIFAR10 datasets with binary and can lead to $>69\%$ sparsity. We observe real speedup when deploying these models on general-purpose devices. We show that this high percentage of unstructured sparsity can lead to a further ~2x reduction in energy consumption on ASICs with respect to binary.
Offline Visual Representation Learning for Embodied Navigation
Apr 27, 2022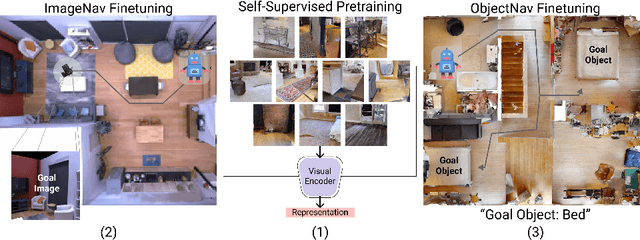
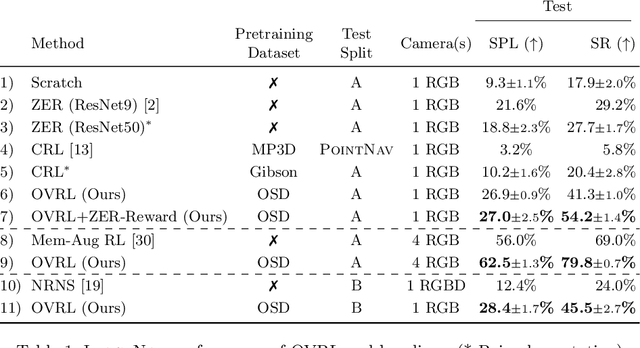
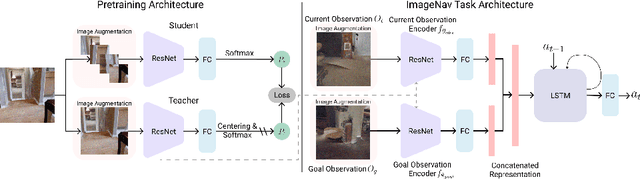
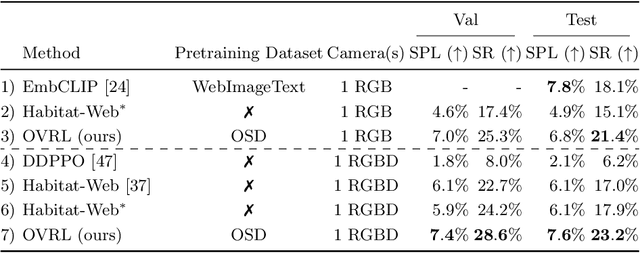
How should we learn visual representations for embodied agents that must see and move? The status quo is tabula rasa in vivo, i.e. learning visual representations from scratch while also learning to move, potentially augmented with auxiliary tasks (e.g. predicting the action taken between two successive observations). In this paper, we show that an alternative 2-stage strategy is far more effective: (1) offline pretraining of visual representations with self-supervised learning (SSL) using large-scale pre-rendered images of indoor environments (Omnidata), and (2) online finetuning of visuomotor representations on specific tasks with image augmentations under long learning schedules. We call this method Offline Visual Representation Learning (OVRL). We conduct large-scale experiments - on 3 different 3D datasets (Gibson, HM3D, MP3D), 2 tasks (ImageNav, ObjectNav), and 2 policy learning algorithms (RL, IL) - and find that the OVRL representations lead to significant across-the-board improvements in state of art, on ImageNav from 29.2% to 54.2% (+25% absolute, 86% relative) and on ObjectNav from 18.1% to 23.2% (+5.1% absolute, 28% relative). Importantly, both results were achieved by the same visual encoder generalizing to datasets that were not seen during pretraining. While the benefits of pretraining sometimes diminish (or entirely disappear) with long finetuning schedules, we find that OVRL's performance gains continue to increase (not decrease) as the agent is trained for 2 billion frames of experience.