 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Visual Representation Learning for Embodied Navigation
Paper and Code
Apr 27, 2022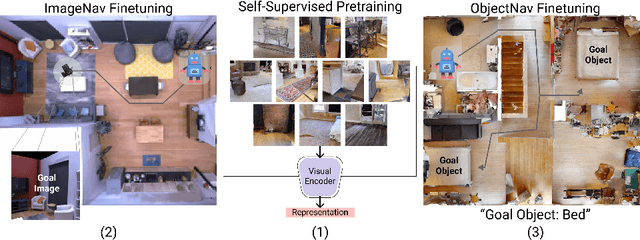
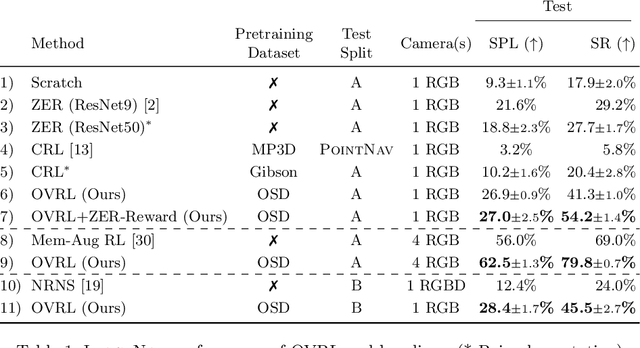
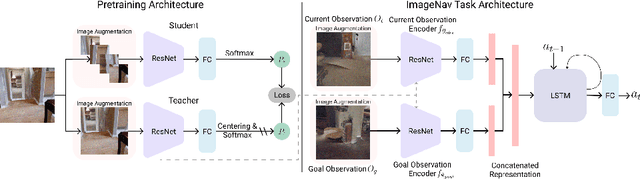
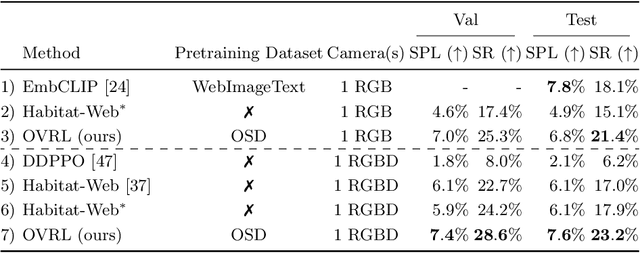
How should we learn visual representations for embodied agents that must see and move? The status quo is tabula rasa in vivo, i.e. learning visual representations from scratch while also learning to move, potentially augmented with auxiliary tasks (e.g. predicting the action taken between two successive observations). In this paper, we show that an alternative 2-stage strategy is far more effective: (1) offline pretraining of visual representations with self-supervised learning (SSL) using large-scale pre-rendered images of indoor environments (Omnidata), and (2) online finetuning of visuomotor representations on specific tasks with image augmentations under long learning schedules. We call this method Offline Visual Representation Learning (OVRL). We conduct large-scale experiments - on 3 different 3D datasets (Gibson, HM3D, MP3D), 2 tasks (ImageNav, ObjectNav), and 2 policy learning algorithms (RL, IL) - and find that the OVRL representations lead to significant across-the-board improvements in state of art, on ImageNav from 29.2% to 54.2% (+25% absolute, 86% relative) and on ObjectNav from 18.1% to 23.2% (+5.1% absolute, 28% relative). Importantly, both results were achieved by the same visual encoder generalizing to datasets that were not seen during pretraining. While the benefits of pretraining sometimes diminish (or entirely disappear) with long finetuning schedules, we find that OVRL's performance gains continue to increase (not decrease) as the agent is trained for 2 billion frames of experience.