 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTactile Genesis: Exploring Tactile Sensors at Scale for Learning Dexterous Tasks
Jun 21, 2026Tactile sensing is critical for contact-rich dexterous manipulation, yet it remains unclear which tactile abstractions a policy needs and when richer tactile fields justify their hardware cost. This is hard to study empirically: each sensor effectively defines a new robot, and no lab can replicate the same learning experiment across all of them. We present Tactile Genesis, a GPU-parallel tactile sensor simulation platform that exposes binary contact, contact depth, per-taxel kinematic force/torque, elastomer marker displacement, geometry-aware proximity, contact audio, and a voxelized temperature field (the first of its kind in robot learning physics simulation platforms) under a common interface, with configurable placement, resolution, and a realistic noise model (drift, hysteresis, dead taxels, crosstalk). It scales past 20,000 parallel environments and 1,000 taxels on a single GPU, improving throughput by 3 to 20 times over previous tactile simulators. We train teacher-student policies on three dexterous tasks, ablating sensor type, placement, resolution, and noise, and verify transfer to the real XHand1. Proprioception alone is insufficient on every task. Sensor placement dominates sensor type: fingertip-only coverage trails whole-hand coverage by a wide margin, while adding the palm and proximal phalanges closes most of the gap to the privileged teacher. Resolution matters far less than coverage: placing 200 taxels across the whole hand suffices across tasks. We find that force/torque per taxel is consistently the most useful sensor type. These results give concrete guidance for both future tactile hardware design for improving robot hands and policy-side observation choice in dexterous manipulation. https://neuroagents-lab.github.io/2026-tactile-genesis/
EgoVerse: An Egocentric Human Dataset for Robot Learning from Around the World
Apr 08, 2026Robot learning increasingly depends on large and diverse data, yet robot data collection remains expensive and difficult to scale. Egocentric human data offer a promising alternative by capturing rich manipulation behavior across everyday environments. However, existing human datasets are often limited in scope, difficult to extend, and fragmented across institutions. We introduce EgoVerse, a collaborative platform for human data-driven robot learning that unifies data collection, processing, and access under a shared framework, enabling contributions from individual researchers, academic labs, and industry partners. The current release includes 1,362 hours (80k episodes) of human demonstrations spanning 1,965 tasks, 240 scenes, and 2,087 unique demonstrators, with standardized formats, manipulation-relevant annotations, and tooling for downstream learning. Beyond the dataset, we conduct a large-scale study of human-to-robot transfer with experiments replicated across multiple labs, tasks, and robot embodiments under shared protocols. We find that policy performance generally improves with increased human data, but that effective scaling depends on alignment between human data and robot learning objectives. Together, the dataset, platform, and study establish a foundation for reproducible progress in human data-driven robot learning. Videos and additional information can be found at https://egoverse.ai/
EMMA: Scaling Mobile Manipulation via Egocentric Human Data
Sep 04, 2025Scaling mobile manipulation imitation learning is bottlenecked by expensive mobile robot teleoperation. We present Egocentric Mobile MAnipulation (EMMA), an end-to-end framework training mobile manipulation policies from human mobile manipulation data with static robot data, sidestepping mobile teleoperation. To accomplish this, we co-train human full-body motion data with static robot data. In our experiments across three real-world tasks, EMMA demonstrates comparable performance to baselines trained on teleoperated mobile robot data (Mobile ALOHA), achieving higher or equivalent task performance in full task success. We find that EMMA is able to generalize to new spatial configurations and scenes, and we observe positive performance scaling as we increase the hours of human data, opening new avenues for scalable robotic learning in real-world environments. Details of this project can be found at https://ego-moma.github.io/.
Benchmarking Active Learning for NILM
Nov 24, 2024



Non-intrusive load monitoring (NILM) focuses on disaggregating total household power consumption into appliance-specific usage. Many advanced NILM methods are based on neural networks that typically require substantial amounts of labeled appliance data, which can be challenging and costly to collect in real-world settings. We hypothesize that appliance data from all households does not uniformly contribute to NILM model improvements. Thus, we propose an active learning approach to selectively install appliance monitors in a limited number of houses. This work is the first to benchmark the use of active learning for strategically selecting appliance-level data to optimize NILM performance. We first develop uncertainty-aware neural networks for NILM and then install sensors in homes where disaggregation uncertainty is highest. Benchmarking our method on the publicly available Pecan Street Dataport dataset, we demonstrate that our approach significantly outperforms a standard random baseline and achieves performance comparable to models trained on the entire dataset. Using this approach, we achieve comparable NILM accuracy with approximately 30% of the data, and for a fixed number of sensors, we observe up to a 2x reduction in disaggregation errors compared to random sampling.
EgoMimic: Scaling Imitation Learning via Egocentric Video
Oct 31, 2024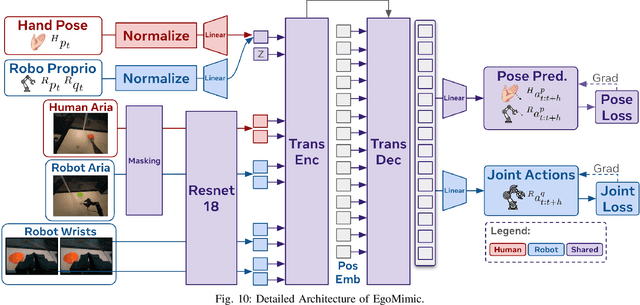


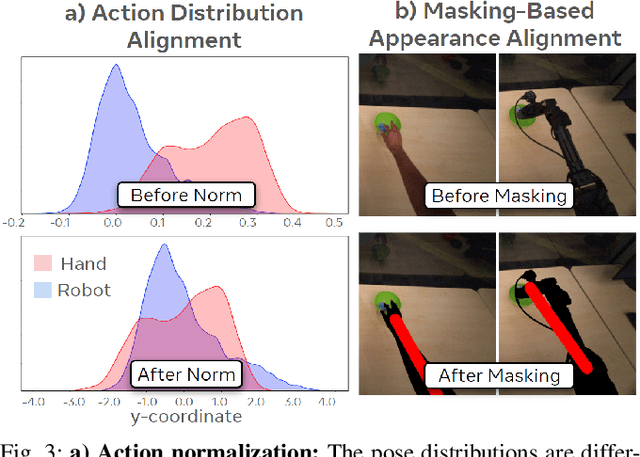
The scale and diversity of demonstration data required for imitation learning is a significant challenge. We present EgoMimic, a full-stack framework which scales manipulation via human embodiment data, specifically egocentric human videos paired with 3D hand tracking. EgoMimic achieves this through: (1) a system to capture human embodiment data using the ergonomic Project Aria glasses, (2) a low-cost bimanual manipulator that minimizes the kinematic gap to human data, (3) cross-domain data alignment techniques, and (4) an imitation learning architecture that co-trains on human and robot data. Compared to prior works that only extract high-level intent from human videos, our approach treats human and robot data equally as embodied demonstration data and learns a unified policy from both data sources. EgoMimic achieves significant improvement on a diverse set of long-horizon, single-arm and bimanual manipulation tasks over state-of-the-art imitation learning methods and enables generalization to entirely new scenes. Finally, we show a favorable scaling trend for EgoMimic, where adding 1 hour of additional hand data is significantly more valuable than 1 hour of additional robot data. Videos and additional information can be found at https://egomimic.github.io/
Automated Detection and Counting of Windows using UAV Imagery based Remote Sensing
Nov 24, 2023Despite the technological advancements in the construction and surveying sector, the inspection of salient features like windows in an under-construction or existing building is predominantly a manual process. Moreover, the number of windows present in a building is directly related to the magnitude of deformation it suffers under earthquakes. In this research, a method to accurately detect and count the number of windows of a building by deploying an Unmanned Aerial Vehicle (UAV) based remote sensing system is proposed. The proposed two-stage method automates the identification and counting of windows by developing computer vision pipelines that utilize data from UAV's onboard camera and other sensors. Quantitative and Qualitative results show the effectiveness of our proposed approach in accurately detecting and counting the windows compared to the existing method.
Consistency of Lloyd's Algorithm Under Perturbations
Sep 01, 2023
In the context of unsupervised learning, Lloyd's algorithm is one of the most widely used clustering algorithms. It has inspired a plethora of work investigating the correctness of the algorithm under various settings with ground truth clusters. In particular, in 2016, Lu and Zhou have shown that the mis-clustering rate of Lloyd's algorithm on $n$ independent samples from a sub-Gaussian mixture is exponentially bounded after $O(\log(n))$ iterations, assuming proper initialization of the algorithm. However, in many applications, the true samples are unobserved and need to be learned from the data via pre-processing pipelines such as spectral methods on appropriate data matrices. We show that the mis-clustering rate of Lloyd's algorithm on perturbed samples from a sub-Gaussian mixture is also exponentially bounded after $O(\log(n))$ iterations under the assumptions of proper initialization and that the perturbation is small relative to the sub-Gaussian noise. In canonical settings with ground truth clusters, we derive bounds for algorithms such as $k$-means$++$ to find good initializations and thus leading to the correctness of clustering via the main result. We show the implications of the results for pipelines measuring the statistical significance of derived clusters from data such as SigClust. We use these general results to derive implications in providing theoretical guarantees on the misclustering rate for Lloyd's algorithm in a host of applications, including high-dimensional time series, multi-dimensional scaling, and community detection for sparse networks via spectral clustering.
Product Review Image Ranking for Fashion E-commerce
Aug 10, 2023


In a fashion e-commerce platform where customers can't physically examine the products on their own, being able to see other customers' text and image reviews of the product is critical while making purchase decisions. Given the high reliance on these reviews, over the years we have observed customers proactively sharing their reviews. With an increase in the coverage of User Generated Content (UGC), there has been a corresponding increase in the number of customer images. It is thus imperative to display the most relevant images on top as it may influence users' online shopping choices and behavior. In this paper, we propose a simple yet effective training procedure for ranking customer images. We created a dataset consisting of Myntra (A Major Indian Fashion e-commerce company) studio posts and highly engaged (upvotes/downvotes) UGC images as our starting point and used selected distortion techniques on the images of the above dataset to bring their quality at par with those of bad UGC images. We train our network to rank bad-quality images lower than high-quality ones. Our proposed method outperforms the baseline models on two metrics, namely correlation coefficient, and accuracy, by substantial margins.
Multi-class Brain Tumor Segmentation using Graph Attention Network
Feb 11, 2023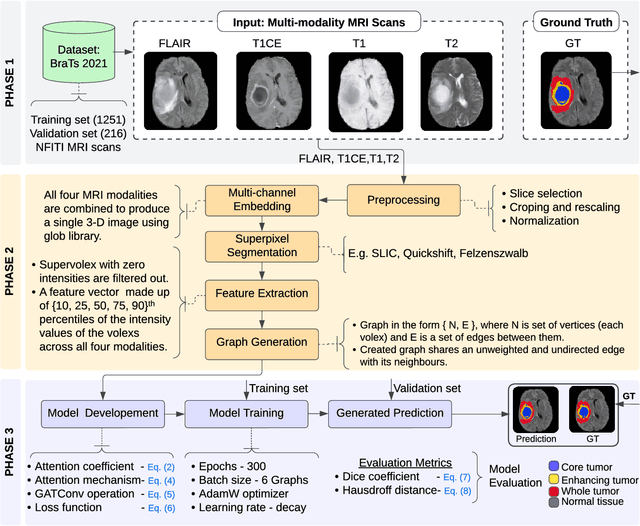
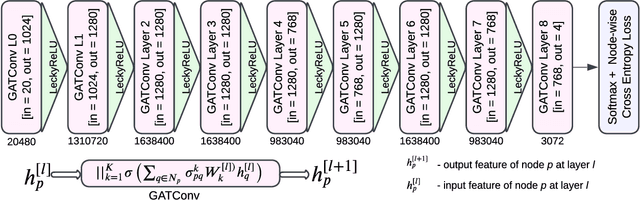

Brain tumor segmentation from magnetic resonance imaging (MRI) plays an important role in diagnostic radiology. To overcome the practical issues in manual approaches, there is a huge demand for building automatic tumor segmentation algorithms. This work introduces an efficient brain tumor summation model by exploiting the advancement in MRI and graph neural networks (GNNs). The model represents the volumetric MRI as a region adjacency graph (RAG) and learns to identify the type of tumors through a graph attention network (GAT) -- a variant of GNNs. The ablation analysis conducted on two benchmark datasets proves that the proposed model can produce competitive results compared to the leading-edge solutions. It achieves mean dice scores of 0.91, 0.86, 0.79, and mean Hausdorff distances in the 95th percentile (HD95) of 5.91, 6.08, and 9.52 mm, respectively, for whole tumor, core tumor, and enhancing tumor segmentation on BraTS2021 validation dataset. On average, these performances are >6\% and >50%, compared to a GNN-based baseline model, respectively, on dice score and HD95 evaluation metrics.
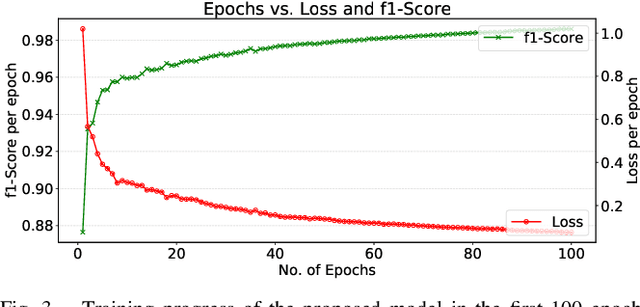
Design of an Autonomous Agriculture Robot for Real Time Weed Detection using CNN
Nov 22, 2022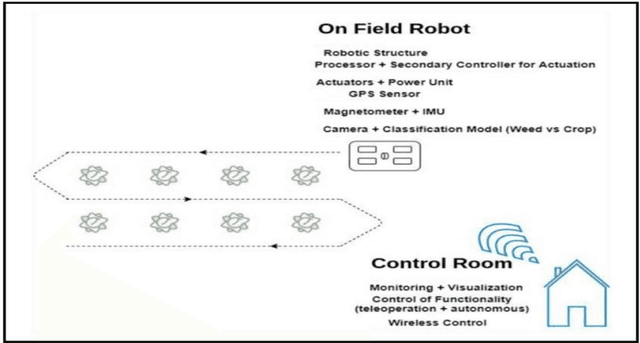
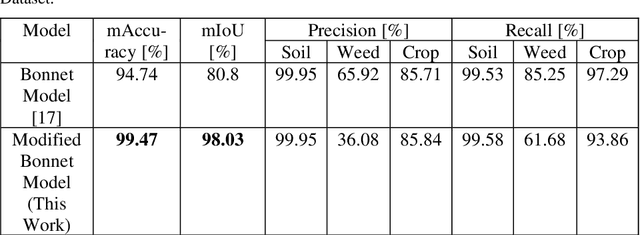
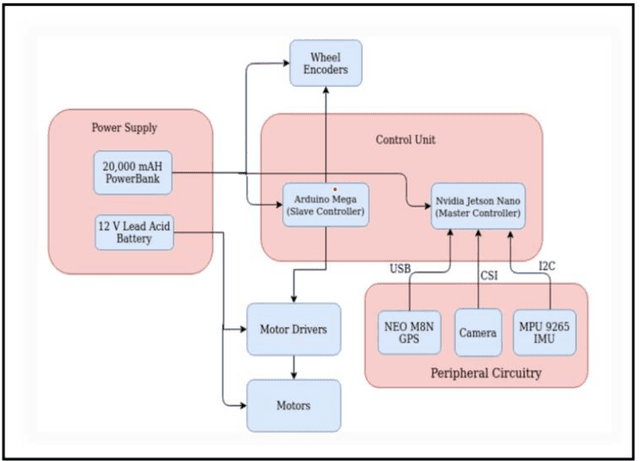

Agriculture has always remained an integral part of the world. As the human population keeps on rising, the demand for food also increases, and so is the dependency on the agriculture industry. But in today's scenario, because of low yield, less rainfall, etc., a dearth of manpower is created in this agricultural sector, and people are moving to live in the cities, and villages are becoming more and more urbanized. On the other hand, the field of robotics has seen tremendous development in the past few years. The concepts like Deep Learning (DL), Artificial Intelligence (AI), and Machine Learning (ML) are being incorporated with robotics to create autonomous systems for various sectors like automotive, agriculture, assembly line management, etc. Deploying such autonomous systems in the agricultural sector help in many aspects like reducing manpower, better yield, and nutritional quality of crops. So, in this paper, the system design of an autonomous agricultural robot which primarily focuses on weed detection is described. A modified deep-learning model for the purpose of weed detection is also proposed. The primary objective of this robot is the detection of weed on a real-time basis without any human involvement, but it can also be extended to design robots in various other applications involved in farming like weed removal, plowing, harvesting, etc., in turn making the farming industry more efficient. Source code and other details can be found at https://github.com/Dhruv2012/Autonomous-Farm-Robot