 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Transformer-Based Monocular SLAM via Geometric Utility Scoring
Apr 13, 2026Geometric Foundation Models (GFMs) have recently advanced monocular SLAM by providing robust, calibration-free 3D priors. However, deploying these models on dense video streams introduces significant computational redundancy. Current GFM-based SLAM systems typically rely on post hoc keyframe selection. Because of this, they must perform expensive dense geometric decoding simply to determine whether a frame contains novel geometry, resulting in late rejection and wasted computation. To mitigate this inefficiency, we propose LeanGate, a lightweight feed-forward frame-gating network. LeanGate predicts a geometric utility score to assess a frame's mapping value prior to the heavy GFM feature extraction and matching stages. As a predictive plug-and-play module, our approach bypasses over 90% of redundant frames. Evaluations on standard SLAM benchmarks demonstrate that LeanGate reduces tracking FLOPs by more than 85% and achieves a 5x end-to-end throughput speedup. Furthermore, it maintains the tracking and mapping accuracy of dense baselines. Project page: https://lean-gate.github.io/
EgoTL: Egocentric Think-Aloud Chains for Long-Horizon Tasks
Apr 10, 2026Large foundation models have made significant advances in embodied intelligence, enabling synthesis and reasoning over egocentric input for household tasks. However, VLM-based auto-labeling is often noisy because the primary data sources lack accurate human action labels, chain-of-thought (CoT), and spatial annotations; these errors are amplified during long-horizon spatial instruction following. These issues stem from insufficient coverage of minute-long, daily household planning tasks and from inaccurate spatial grounding. As a result, VLM reasoning chains and world-model synthesis can hallucinate objects, skip steps, or fail to respect real-world physical attributes. To address these gaps, we introduce EgoTL. EgoTL builds a think-aloud capture pipeline for egocentric data. It uses a say-before-act protocol to record step-by-step goals and spoken reasoning with word-level timestamps, then calibrates physical properties with metric-scale spatial estimators, a memory-bank walkthrough for scene context, and clip-level tags for navigation instructions and detailed manipulation actions. With EgoTL, we are able to benchmark VLMs and World Models on six task dimensions from three layers and long-horizon generation over minute-long sequences across over 100 daily household tasks. We find that foundation models still fall short as egocentric assistants or open-world simulators. Finally, we finetune foundation models with human CoT aligned with metric labels on the training split of EgoTL, which improves long-horizon planning and reasoning, step-wise reasoning, instruction following, and spatial grounding.
Learning Actionable Manipulation Recovery via Counterfactual Failure Synthesis
Mar 13, 2026While recent foundation models have significantly advanced robotic manipulation, these systems still struggle to autonomously recover from execution errors. Current failure-learning paradigms rely on either costly and unsafe real-world data collection or simulator-based perturbations, which introduce a severe sim-to-real gap. Furthermore, existing visual analyzers predominantly output coarse, binary diagnoses rather than the executable, trajectory-level corrections required for actual recovery. To bridge the gap between failure diagnosis and actionable recovery, we introduce Dream2Fix, a framework that synthesizes photorealistic, counterfactual failure rollouts directly from successful real-world demonstrations. By perturbing actions within a generative world model, Dream2Fix creates paired failure-correction data without relying on simulators. To ensure the generated data is physically viable for robot learning, we implement a structured verification mechanism that strictly filters rollouts for task validity, visual coherence, and kinematic safety. This engine produces a high-fidelity dataset of over 120k paired samples. Using this dataset, we fine-tune a vision-language model to jointly predict failure types and precise recovery trajectories, mapping visual anomalies directly to corrective actions. Extensive real-world robotic experiments show our approach achieves state-of-the-art correction accuracy, improving from 19.7% to 81.3% over prior baselines, and successfully enables zero-shot closed-loop failure recovery in physical deployments.
Egocentric World Model for Photorealistic Hand-Object Interaction Synthesis
Mar 13, 2026To serve as a scalable data source for embodied AI, world models should act as true simulators that infer interaction dynamics strictly from user actions, rather than mere conditional video generators relying on privileged future object states. In this context, egocentric Human-Object Interaction (HOI) world models are critical for predicting physically grounded first-person rollouts. However, building such models is profoundly challenging due to rapid head motions, severe occlusions, and high-DoF hand articulations that abruptly alter contact topologies. Consequently, existing approaches often circumvent these physics challenges by resorting to conditional video generation with access to known future object trajectories. We introduce EgoHOI, an egocentric HOI world model that breaks away from this shortcut to simulate photorealistic, contact-consistent interactions from action signals alone. To ensure physical accuracy without future-state inputs, EgoHOI distills geometric and kinematic priors from 3D estimates into physics-informed embeddings. These embeddings regularize the egocentric rollouts toward physically valid dynamics. Experiments on the HOT3D dataset demonstrate consistent gains over strong baselines, and ablations validate the effectiveness of our physics-informed design.
Meta-reasoning Using Attention Maps and Its Applications in Cloud Robotics
May 06, 2025Metareasoning, a branch of AI, focuses on reasoning about reasons. It has the potential to enhance robots' decision-making processes in unexpected situations. However, the concept has largely been confined to theoretical discussions and case-by-case investigations, lacking general and practical solutions when the Value of Computation (VoC) is undefined, which is common in unexpected situations. In this work, we propose a revised meta-reasoning framework that significantly improves the scalability of the original approach in unexpected situations. This is achieved by incorporating semantic attention maps and unsupervised 'attention' updates into the metareasoning processes. To accommodate environmental dynamics, 'lines of thought' are used to bridge context-specific objects with abstracted attentions, while meta-information is monitored and controlled at the meta-level for effective reasoning. The practicality of the proposed approach is demonstrated through cloud robots deployed in real-world scenarios, showing improved performance and robustness.
Learning Instruction-Guided Manipulation Affordance via Large Models for Embodied Robotic Tasks
Aug 20, 2024



We study the task of language instruction-guided robotic manipulation, in which an embodied robot is supposed to manipulate the target objects based on the language instructions. In previous studies, the predicted manipulation regions of the target object typically do not change with specification from the language instructions, which means that the language perception and manipulation prediction are separate. However, in human behavioral patterns, the manipulation regions of the same object will change for different language instructions. In this paper, we propose Instruction-Guided Affordance Net (IGANet) for predicting affordance maps of instruction-guided robotic manipulation tasks by utilizing powerful priors from vision and language encoders pre-trained on large-scale datasets. We develop a Vison-Language-Models(VLMs)-based data augmentation pipeline, which can generate a large amount of data automatically for model training. Besides, with the help of Large-Language-Models(LLMs), actions can be effectively executed to finish the tasks defined by instructions. A series of real-world experiments revealed that our method can achieve better performance with generated data. Moreover, our model can generalize better to scenarios with unseen objects and language instructions.
MPGNet: Learning Move-Push-Grasping Synergy for Target-Oriented Grasping in Occluded Scenes
Aug 20, 2024
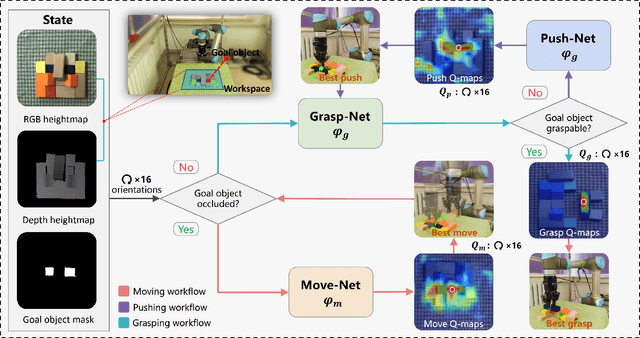
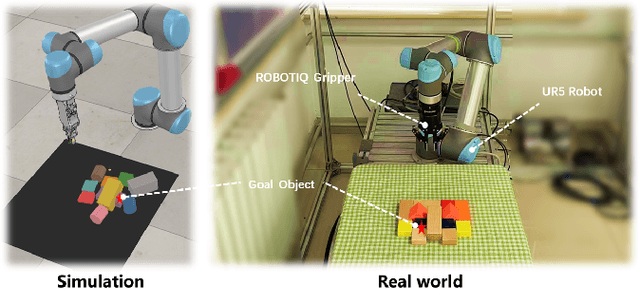
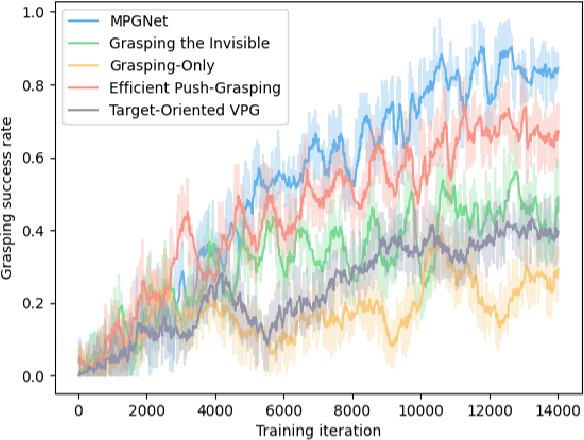
This paper focuses on target-oriented grasping in occluded scenes, where the target object is specified by a binary mask and the goal is to grasp the target object with as few robotic manipulations as possible. Most existing methods rely on a push-grasping synergy to complete this task. To deliver a more powerful target-oriented grasping pipeline, we present MPGNet, a three-branch network for learning a synergy between moving, pushing, and grasping actions. We also propose a multi-stage training strategy to train the MPGNet which contains three policy networks corresponding to the three actions. The effectiveness of our method is demonstrated via both simulated and real-world experiments.
Coarse-to-Fine Detection of Multiple Seams for Robotic Welding
Aug 20, 2024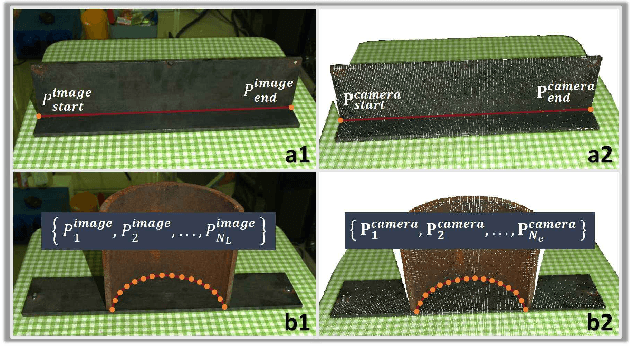
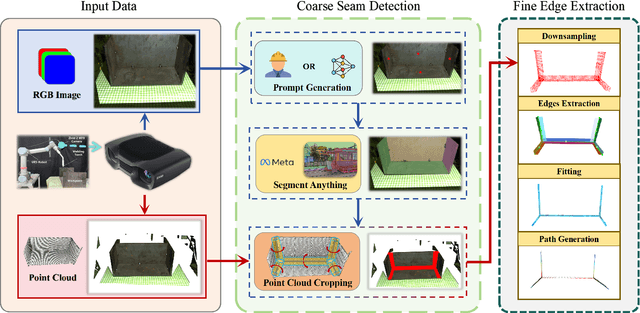

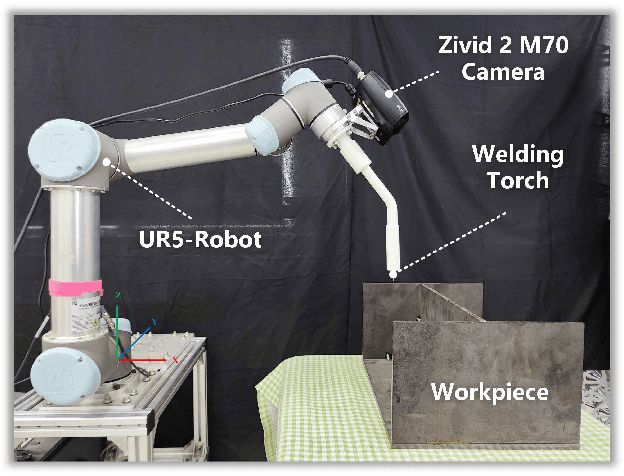
Efficiently detecting target weld seams while ensuring sub-millimeter accuracy has always been an important challenge in autonomous welding, which has significant application in industrial practice. Previous works mostly focused on recognizing and localizing welding seams one by one, leading to inferior efficiency in modeling the workpiece. This paper proposes a novel framework capable of multiple weld seams extraction using both RGB images and 3D point clouds. The RGB image is used to obtain the region of interest by approximately localizing the weld seams, and the point cloud is used to achieve the fine-edge extraction of the weld seams within the region of interest using region growth. Our method is further accelerated by using a pre-trained deep learning model to ensure both efficiency and generalization ability. The performance of the proposed method has been comprehensively tested on various workpieces featuring both linear and curved weld seams and in physical experiment systems. The results showcase considerable potential for real-world industrial applications, emphasizing the method's efficiency and effectiveness. Videos of the real-world experiments can be found at https://youtu.be/pq162HSP2D4.
Where to Fetch: Extracting Visual Scene Representation from Large Pre-Trained Models for Robotic Goal Navigation
Aug 20, 2024To complete a complex task where a robot navigates to a goal object and fetches it, the robot needs to have a good understanding of the instructions and the surrounding environment. Large pre-trained models have shown capabilities to interpret tasks defined via language descriptions. However, previous methods attempting to integrate large pre-trained models with daily tasks are not competent in many robotic goal navigation tasks due to poor understanding of the environment. In this work, we present a visual scene representation built with large-scale visual language models to form a feature representation of the environment capable of handling natural language queries. Combined with large language models, this method can parse language instructions into action sequences for a robot to follow, and accomplish goal navigation with querying the scene representation. Experiments demonstrate that our method enables the robot to follow a wide range of instructions and complete complex goal navigation tasks.
An Evolutionary-Based Approach to Learning Multiple Decision Models from Underrepresented Data
May 24, 2008
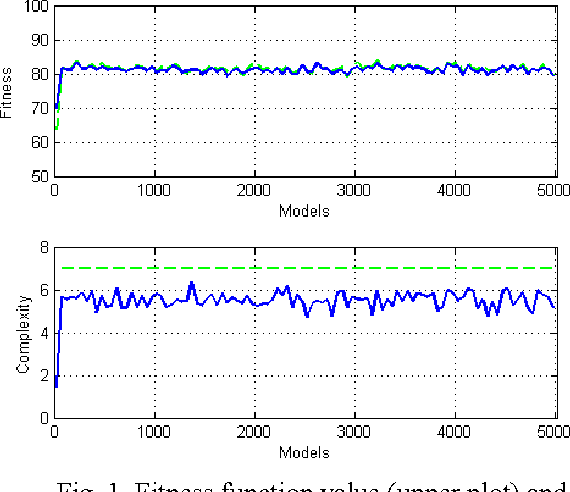
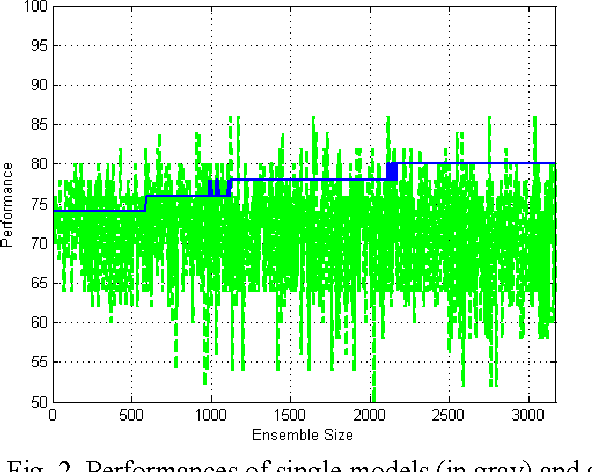
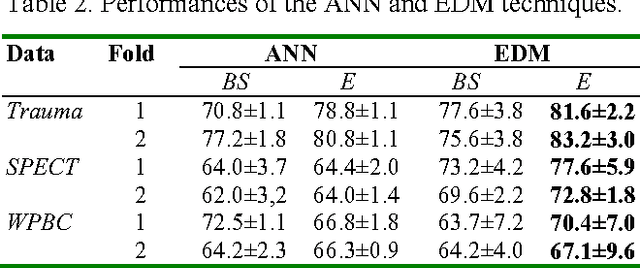
The use of multiple Decision Models (DMs) enables to enhance the accuracy in decisions and at the same time allows users to evaluate the confidence in decision making. In this paper we explore the ability of multiple DMs to learn from a small amount of verified data. This becomes important when data samples are difficult to collect and verify. We propose an evolutionary-based approach to solving this problem. The proposed technique is examined on a few clinical problems presented by a small amount of data.