 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Manipulation Potential and Haptic Estimation for Tool-Mediated Interaction
Mar 11, 2026Achieving human-level dexterity in contact-rich, tool-mediated manipulation remains a significant challenge due to visual occlusion and the underdetermined nature of haptic sensing. This paper introduces a parameterized Equilibrium Manifold (EM) as a unified representation for tool-mediated interaction, and develops a closed-loop framework that integrates haptic estimation, online planning, and adaptive stiffness control. We establish a physical-geometric duality using an adaptive manipulation potential incorporating a differentiable contact model, which induces the manifold's geometric structure and ensures that complex physical interactions are encapsulated as continuous operations on the EM. Within this framework, we reformulate haptic estimation as a manifold parameter estimation problem. Specifically, a hybrid inference strategy (haptic SLAM) is employed in which discrete object shapes are classified via particle filtering, while the continuous object pose is estimated using analytical gradients for efficient optimization. By continuously updating the parameters of the manipulation potential, the framework dynamically reshapes the induced EM to guide online trajectory replanning and implement uncertainty-aware impedance control, thereby closing the perception-action loop. The system is validated through simulation and over 260 real-world screw-loosening trials. Experimental results demonstrate robust identification and manipulation success in standard scenarios while maintaining accurate tracking. Furthermore, ablation studies confirm that haptic SLAM and uncertainty-aware stiffness modulation outperform fixed impedance baselines, effectively preventing jamming during tight tolerance interactions.
C2TE: Coordinated Constrained Task Execution Design for Ordering-Flexible Multi-Vehicle Platoon Merging
Jun 16, 2025In this paper, we propose a distributed coordinated constrained task execution (C2TE) algorithm that enables a team of vehicles from different lanes to cooperatively merge into an {\it ordering-flexible platoon} maneuvering on the desired lane. Therein, the platoon is flexible in the sense that no specific spatial ordering sequences of vehicles are predetermined. To attain such a flexible platoon, we first separate the multi-vehicle platoon (MVP) merging mission into two stages, namely, pre-merging regulation and {\it ordering-flexible platoon} merging, and then formulate them into distributed constraint-based optimization problems. Particularly, by encoding longitudinal-distance regulation and same-lane collision avoidance subtasks into the corresponding control barrier function (CBF) constraints, the proposed algorithm in Stage 1 can safely enlarge sufficient longitudinal distances among adjacent vehicles. Then, by encoding lateral convergence, longitudinal-target attraction, and neighboring collision avoidance subtasks into CBF constraints, the proposed algorithm in Stage~2 can efficiently achieve the {\it ordering-flexible platoon}. Note that the {\it ordering-flexible platoon} is realized through the interaction of the longitudinal-target attraction and time-varying neighboring collision avoidance constraints simultaneously. Feasibility guarantee and rigorous convergence analysis are both provided under strong nonlinear couplings induced by flexible orderings. Finally, experiments using three autonomous mobile vehicles (AMVs) are conducted to verify the effectiveness and flexibility of the proposed algorithm, and extensive simulations are performed to demonstrate its robustness, adaptability, and scalability when tackling vehicles' sudden breakdown, new appearing, different number of lanes, mixed autonomy, and large-scale scenarios, respectively.
Concurrent-Allocation Task Execution for Multi-Robot Path-Crossing-Minimal Navigation in Obstacle Environments
Apr 12, 2025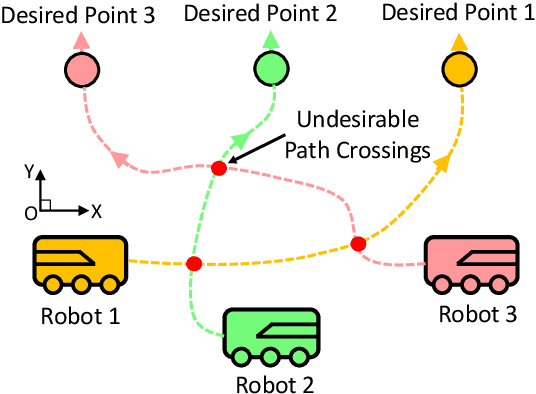
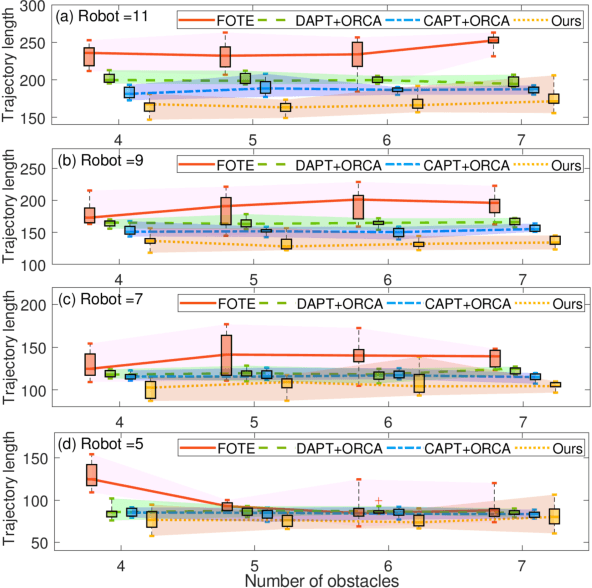
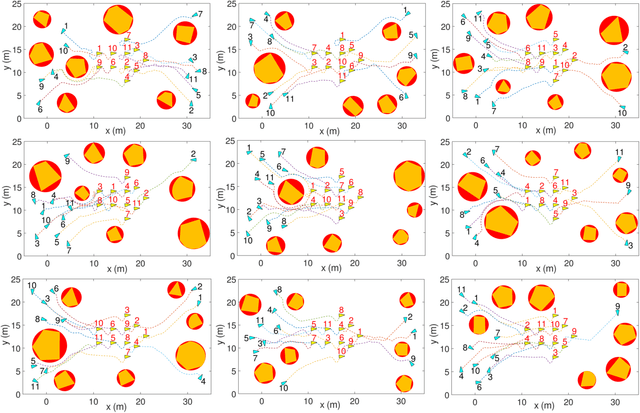
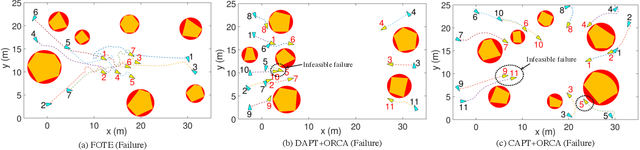
Reducing undesirable path crossings among trajectories of different robots is vital in multi-robot navigation missions, which not only reduces detours and conflict scenarios, but also enhances navigation efficiency and boosts productivity. Despite recent progress in multi-robot path-crossing-minimal (MPCM) navigation, the majority of approaches depend on the minimal squared-distance reassignment of suitable desired points to robots directly. However, if obstacles occupy the passing space, calculating the actual robot-point distances becomes complex or intractable, which may render the MPCM navigation in obstacle environments inefficient or even infeasible. In this paper, the concurrent-allocation task execution (CATE) algorithm is presented to address this problem (i.e., MPCM navigation in obstacle environments). First, the path-crossing-related elements in terms of (i) robot allocation, (ii) desired-point convergence, and (iii) collision and obstacle avoidance are encoded into integer and control barrier function (CBF) constraints. Then, the proposed constraints are used in an online constrained optimization framework, which implicitly yet effectively minimizes the possible path crossings and trajectory length in obstacle environments by minimizing the desired point allocation cost and slack variables in CBF constraints simultaneously. In this way, the MPCM navigation in obstacle environments can be achieved with flexible spatial orderings. Note that the feasibility of solutions and the asymptotic convergence property of the proposed CATE algorithm in obstacle environments are both guaranteed, and the calculation burden is also reduced by concurrently calculating the optimal allocation and the control input directly without the path planning process.
AquilaMoE: Efficient Training for MoE Models with Scale-Up and Scale-Out Strategies
Aug 13, 2024In recent years, with the rapid application of large language models across various fields, the scale of these models has gradually increased, and the resources required for their pre-training have grown exponentially. Training an LLM from scratch will cost a lot of computation resources while scaling up from a smaller model is a more efficient approach and has thus attracted significant attention. In this paper, we present AquilaMoE, a cutting-edge bilingual 8*16B Mixture of Experts (MoE) language model that has 8 experts with 16 billion parameters each and is developed using an innovative training methodology called EfficientScale. This approach optimizes performance while minimizing data requirements through a two-stage process. The first stage, termed Scale-Up, initializes the larger model with weights from a pre-trained smaller model, enabling substantial knowledge transfer and continuous pretraining with significantly less data. The second stage, Scale-Out, uses a pre-trained dense model to initialize the MoE experts, further enhancing knowledge transfer and performance. Extensive validation experiments on 1.8B and 7B models compared various initialization schemes, achieving models that maintain and reduce loss during continuous pretraining. Utilizing the optimal scheme, we successfully trained a 16B model and subsequently the 8*16B AquilaMoE model, demonstrating significant improvements in performance and training efficiency.
Ordering-Flexible Multi-Robot Coordination for MovingTarget Convoying Using Long-TermTask Execution
Jan 12, 2024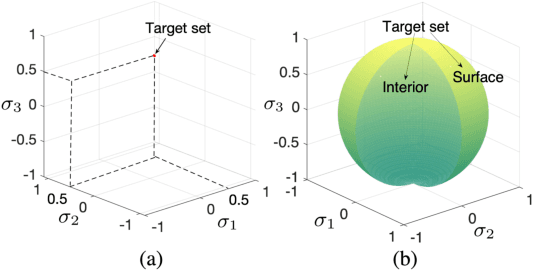
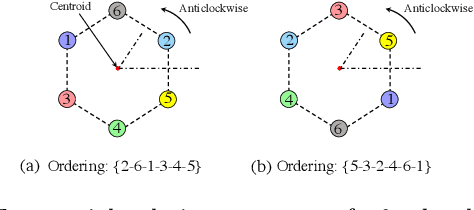
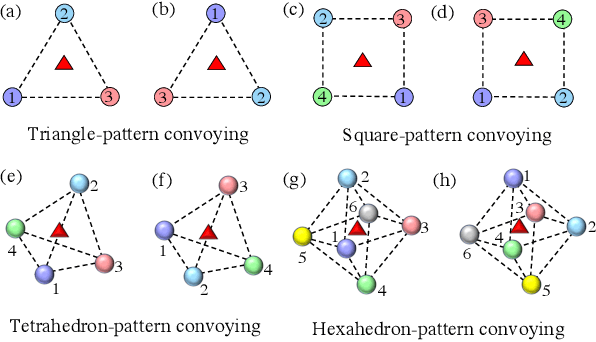
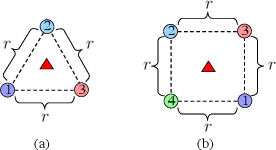
In this paper, we propose a cooperative long-term task execution (LTTE) algorithm for protecting a moving target into the interior of an ordering-flexible convex hull by a team of robots resiliently in the changing environments. Particularly, by designing target-approaching and sensing-neighbor collision-free subtasks, and incorporating these subtasks into the constraints rather than the traditional cost function in an online constraint-based optimization framework, the proposed LTTE can systematically guarantee long-term target convoying under changing environments in the n-dimensional Euclidean space. Then, the introduction of slack variables allow for the constraint violation of different subtasks; i.e., the attraction from target-approaching constraints and the repulsion from time-varying collision-avoidance constraints, which results in the desired formation with arbitrary spatial ordering sequences. Rigorous analysis is provided to guarantee asymptotical convergence with challenging nonlinear couplings induced by time-varying collision-free constraints. Finally, 2D experiments using three autonomous mobile robots (AMRs) are conducted to validate the effectiveness of the proposed algorithm, and 3D simulations tackling changing environmental elements, such as different initial positions, some robots suddenly breakdown and static obstacles are presented to demonstrate the multi-dimensional adaptability, robustness and the ability of obstacle avoidance of the proposed method.
Goal-guided Transformer-enabled Reinforcement Learning for Efficient Autonomous Navigation
Jan 01, 2023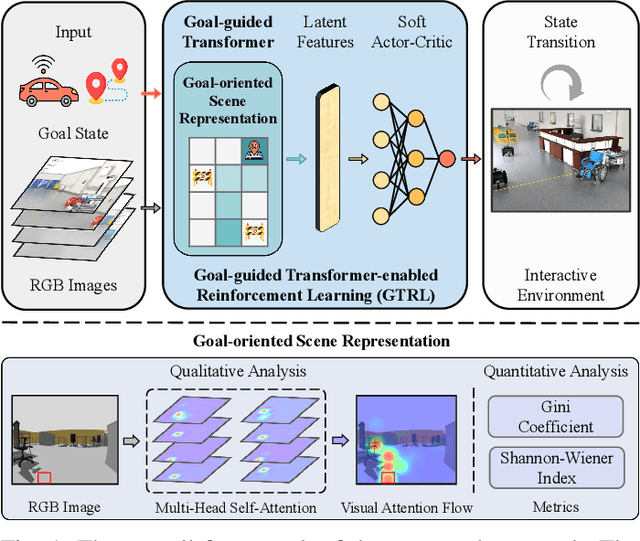

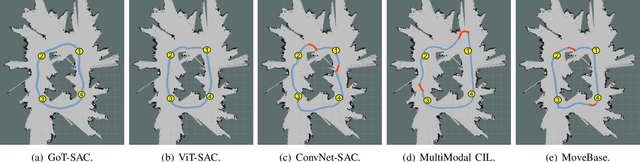
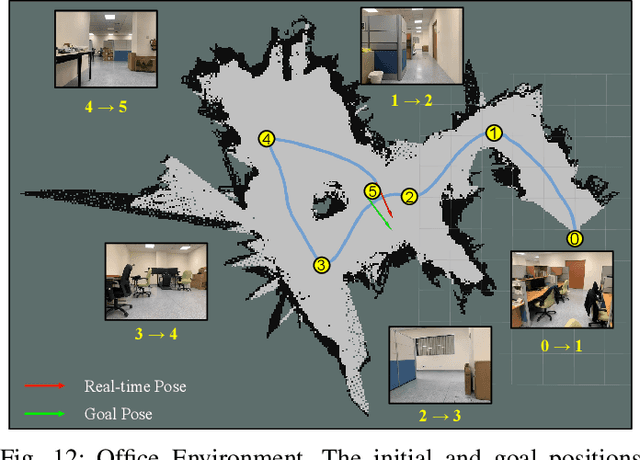
Despite some successful applications of goal-driven navigation, existing deep reinforcement learning-based approaches notoriously suffers from poor data efficiency issue. One of the reasons is that the goal information is decoupled from the perception module and directly introduced as a condition of decision-making, resulting in the goal-irrelevant features of the scene representation playing an adversary role during the learning process. In light of this, we present a novel Goal-guided Transformer-enabled reinforcement learning (GTRL) approach by considering the physical goal states as an input of the scene encoder for guiding the scene representation to couple with the goal information and realizing efficient autonomous navigation. More specifically, we propose a novel variant of the Vision Transformer as the backbone of the perception system, namely Goal-guided Transformer (GoT), and pre-train it with expert priors to boost the data efficiency. Subsequently, a reinforcement learning algorithm is instantiated for the decision-making system, taking the goal-oriented scene representation from the GoT as the input and generating decision commands. As a result, our approach motivates the scene representation to concentrate mainly on goal-relevant features, which substantially enhances the data efficiency of the DRL learning process, leading to superior navigation performance. Both simulation and real-world experimental results manifest the superiority of our approach in terms of data efficiency, performance, robustness, and sim-to-real generalization, compared with other state-of-art baselines. Demonstration videos are available at \colorb{https://youtu.be/93LGlGvaN0c.
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification
Nov 23, 2021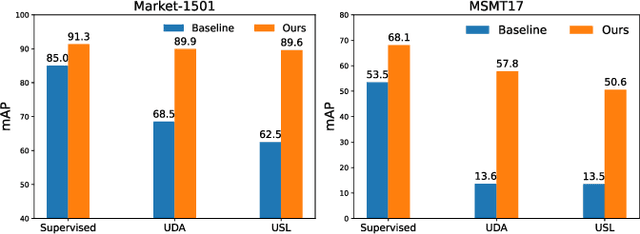



Transformer-based supervised pre-training achieves great performance in person re-identification (ReID). However, due to the domain gap between ImageNet and ReID datasets, it usually needs a larger pre-training dataset (e.g. ImageNet-21K) to boost the performance because of the strong data fitting ability of the transformer. To address this challenge, this work targets to mitigate the gap between the pre-training and ReID datasets from the perspective of data and model structure, respectively. We first investigate self-supervised learning (SSL) methods with Vision Transformer (ViT) pretrained on unlabelled person images (the LUPerson dataset), and empirically find it significantly surpasses ImageNet supervised pre-training models on ReID tasks. To further reduce the domain gap and accelerate the pre-training, the Catastrophic Forgetting Score (CFS) is proposed to evaluate the gap between pre-training and fine-tuning data. Based on CFS, a subset is selected via sampling relevant data close to the down-stream ReID data and filtering irrelevant data from the pre-training dataset. For the model structure, a ReID-specific module named IBN-based convolution stem (ICS) is proposed to bridge the domain gap by learning more invariant features. Extensive experiments have been conducted to fine-tune the pre-training models under supervised learning, unsupervised domain adaptation (UDA), and unsupervised learning (USL) settings. We successfully downscale the LUPerson dataset to 50% with no performance degradation. Finally, we achieve state-of-the-art performance on Market-1501 and MSMT17. For example, our ViT-S/16 achieves 91.3%/89.9%/89.6% mAP accuracy on Market1501 for supervised/UDA/USL ReID. Codes and models will be released to https://github.com/michuanhaohao/TransReID-SSL.
A Marker-free Head Tracker Using Vision-based Head Pose Estimation with Adaptive Kalman Filter
Mar 24, 2021


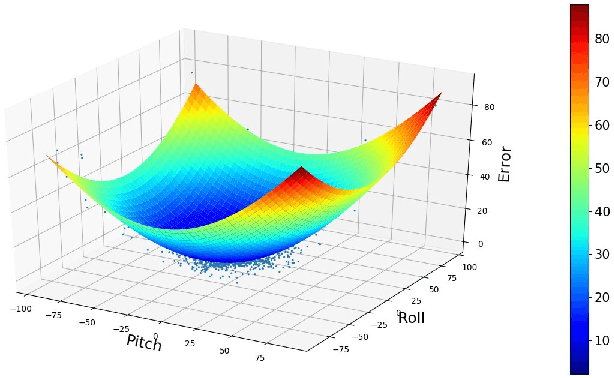
The immersion and the interaction are the important features of the driving simulator. To improve these characteristics, this paper proposes a low-cost and mark-less driver head tracking framework based on the head pose estimation model, which makes the view of the simulator can automatically align with the driver's head pose. The proposed method only uses the RGB camera without the other hardware or marker. To handle the error of the head pose estimation model, this paper proposes an adaptive Kalman Filter. By analyzing the error distribution of the estimation model and user experience, the proposed Kalman Filter includes the adaptive observation noise coefficient and loop closure module, which can adaptive moderate the smoothness of the curve and keep the curve stable near the initial position. The experiments show that the proposed method is feasible, and it can be used with different head pose estimation models.