 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Feature Abstraction for Translating Video to Text
Paper and Code
Nov 17, 2017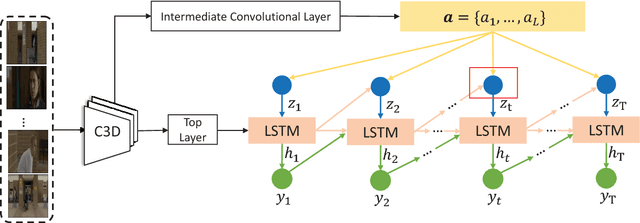
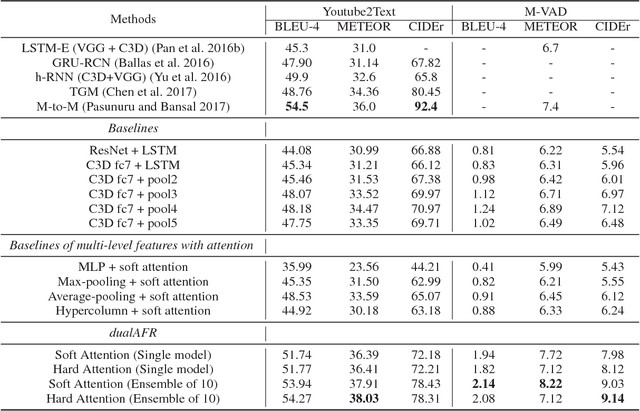
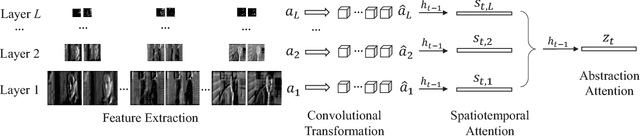

Previous models for video captioning often use the output from a specific layer of a Convolutional Neural Network (CNN) as video features. However, the variable context-dependent semantics in the video may make it more appropriate to adaptively select features from the multiple CNN layers. We propose a new approach for generating adaptive spatiotemporal representations of videos for the captioning task. A novel attention mechanism is developed, that adaptively and sequentially focuses on different layers of CNN features (levels of feature "abstraction"), as well as local spatiotemporal regions of the feature maps at each layer. The proposed approach is evaluated on three benchmark datasets: YouTube2Text, M-VAD and MSR-VTT. Along with visualizing the results and how the model works, these experiments quantitatively demonstrate the effectiveness of the proposed adaptive spatiotemporal feature abstraction for translating videos to sentences with rich semantics.