 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Physics-based Greenhouse Simulation
Nov 21, 2022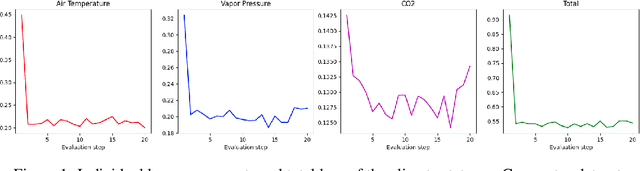
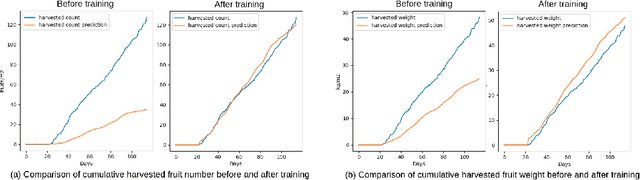
We present a differentiable greenhouse simulation model based on physical processes whose parameters can be obtained by training from real data. The physics-based simulation model is fully interpretable and is able to do state prediction for both climate and crop dynamics in the greenhouse over very a long time horizon. The model works by constructing a system of linear differential equations and solving them to obtain the next state. We propose a procedure to solve the differential equations, handle the problem of missing unobservable states in the data, and train the model efficiently. Our experiment shows the procedure is effective. The model improves significantly after training and can simulate a greenhouse that grows cucumbers accurately.
Learning robust driving policies without online exploration
Mar 15, 2021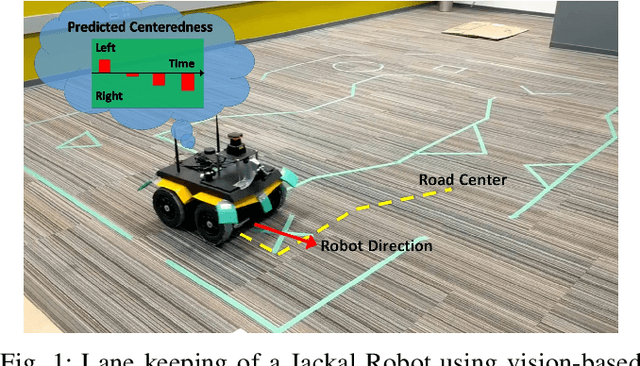
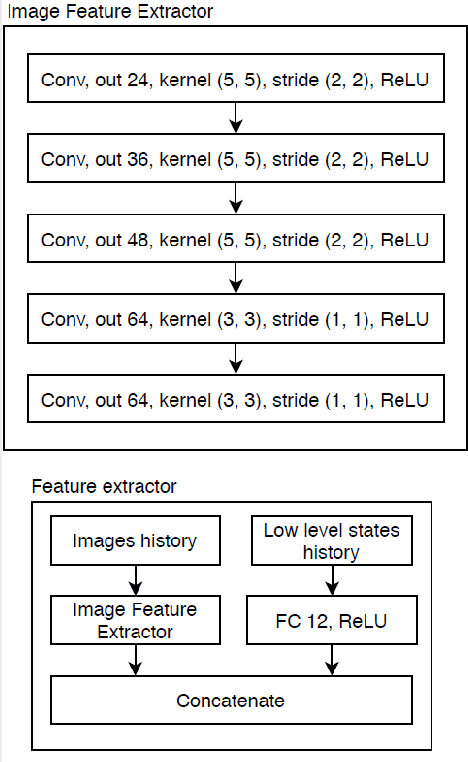
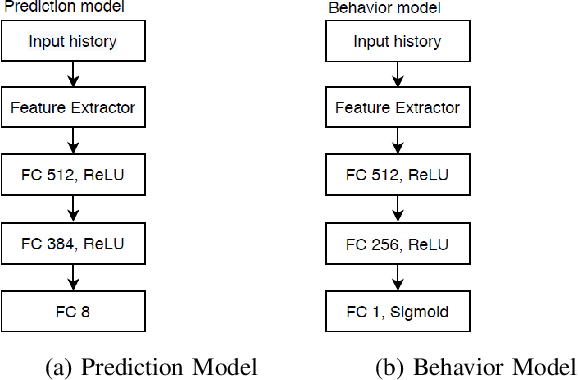
We propose a multi-time-scale predictive representation learning method to efficiently learn robust driving policies in an offline manner that generalize well to novel road geometries, and damaged and distracting lane conditions which are not covered in the offline training data. We show that our proposed representation learning method can be applied easily in an offline (batch) reinforcement learning setting demonstrating the ability to generalize well and efficiently under novel conditions compared to standard batch RL methods. Our proposed method utilizes training data collected entirely offline in the real-world which removes the need of intensive online explorations that impede applying deep reinforcement learning on real-world robot training. Various experiments were conducted in both simulator and real-world scenarios for the purpose of evaluation and analysis of our proposed claims.
Learning predictive representations in autonomous driving to improve deep reinforcement learning
Jun 26, 2020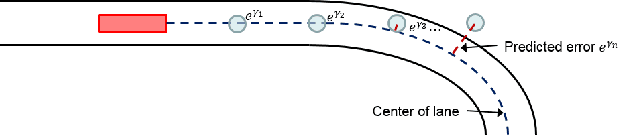
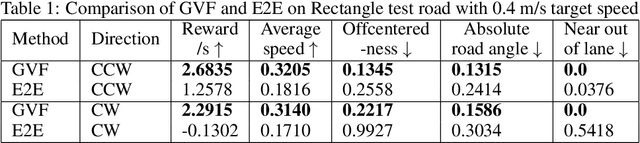

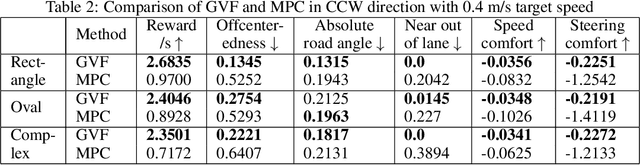
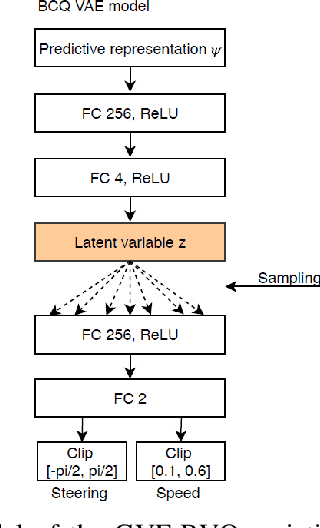
Reinforcement learning using a novel predictive representation is applied to autonomous driving to accomplish the task of driving between lane markings where substantial benefits in performance and generalization are observed on unseen test roads in both simulation and on a real Jackal robot. The novel predictive representation is learned by general value functions (GVFs) to provide out-of-policy, or counter-factual, predictions of future lane centeredness and road angle that form a compact representation of the state of the agent improving learning in both online and offline reinforcement learning to learn to drive an autonomous vehicle with methods that generalizes well to roads not in the training data. Experiments in both simulation and the real-world demonstrate that predictive representations in reinforcement learning improve learning efficiency, smoothness of control and generalization to roads that the agent was never shown during training, including damaged lane markings. It was found that learning a predictive representation that consists of several predictions over different time scales, or discount factors, improves the performance and smoothness of the control substantially. The Jackal robot was trained in a two step process where the predictive representation is learned first followed by a batch reinforcement learning algorithm (BCQ) from data collected through both automated and human-guided exploration in the environment. We conclude that out-of-policy predictive representations with GVFs offer reinforcement learning many benefits in real-world problems.
Mapless Navigation among Dynamics with Social-safety-awareness: a reinforcement learning approach from 2D laser scans
Nov 08, 2019
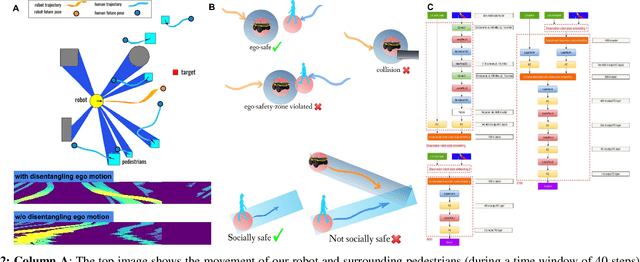
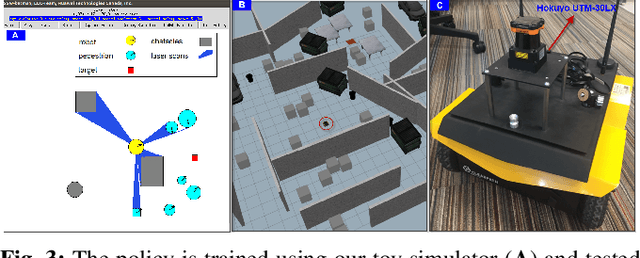
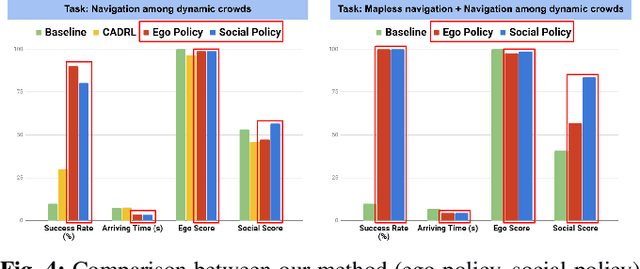
We propose a method to tackle the problem of mapless collision-avoidance navigation where humans are present using 2D laser scans. Our proposed method uses ego-safety to measure collision from the robot's perspective while social-safety to measure the impact of our robot's actions on surrounding pedestrians. Specifically, the social-safety part predicts the intrusion impact of our robot's action into the interaction area with surrounding humans. We train the policy using reinforcement learning on a simple simulator and directly evaluate the learned policy in Gazebo and real robot tests. Experiments show the learned policy can be smoothly transferred without any fine tuning. We observe that our method demonstrates time-efficient path planning behavior with high success rate in mapless navigation tasks. Furthermore, we test our method in a navigation among dynamic crowds task considering both low and high volume traffic. Our learned policy demonstrates cooperative behavior that actively drives our robot into traffic flows while showing respect to nearby pedestrians. Evaluation videos are at https://sites.google.com/view/ssw-batman
End-to-end Learning of Convolutional Neural Net and Dynamic Programming for Left Ventricle Segmentation
Dec 02, 2018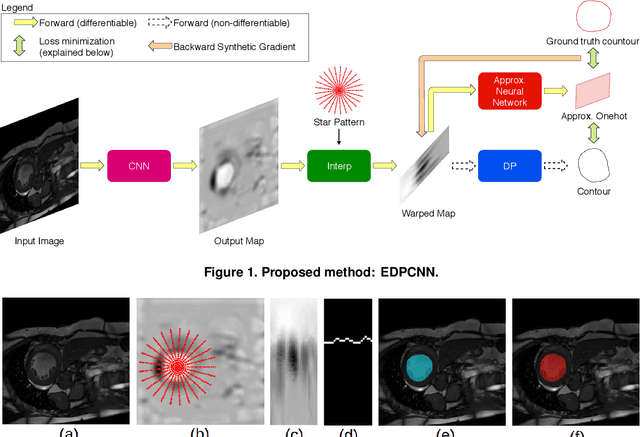


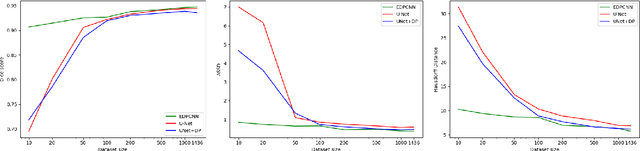
Differentiable programming is able to combine different functions or programs in a processing pipeline with the goal of applying end-to-end learning or optimization. A significant impediment is the non-differentiable nature of some algorithms. We propose to use synthetic gradients (SG) to overcome this difficulty. SG uses the universal function approximation property of neural networks. We apply SG to combine convolutional neural network (CNN) with dynamic programming (DP) in end-to-end learning for segmenting left ventricle from short axis view of heart MRI. Our experiments show that end-to-end combination of CNN and DP requires fewer labeled images to achieve a significantly better segmentation accuracy than using only CNN.
Generative Adversarial Networks using Adaptive Convolution
Jan 25, 2018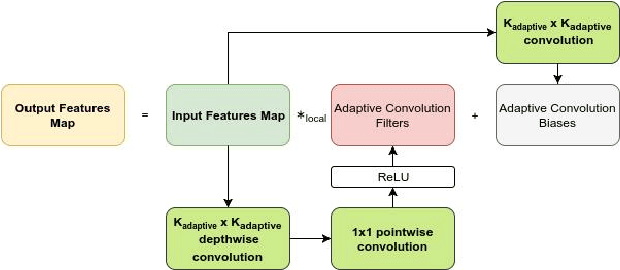



Most existing GANs architectures that generate images use transposed convolution or resize-convolution as their upsampling algorithm from lower to higher resolution feature maps in the generator. We argue that this kind of fixed operation is problematic for GANs to model objects that have very different visual appearances. We propose a novel adaptive convolution method that learns the upsampling algorithm based on the local context at each location to address this problem. We modify a baseline GANs architecture by replacing normal convolutions with adaptive convolutions in the generator. Experiments on CIFAR-10 dataset show that our modified models improve the baseline model by a large margin. Furthermore, our models achieve state-of-the-art performance on CIFAR-10 and STL-10 datasets in the unsupervised setting.