 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Adversarial Networks using Adaptive Convolution
Paper and Code
Jan 25, 2018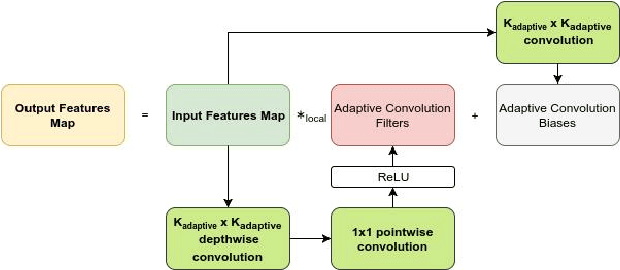



Most existing GANs architectures that generate images use transposed convolution or resize-convolution as their upsampling algorithm from lower to higher resolution feature maps in the generator. We argue that this kind of fixed operation is problematic for GANs to model objects that have very different visual appearances. We propose a novel adaptive convolution method that learns the upsampling algorithm based on the local context at each location to address this problem. We modify a baseline GANs architecture by replacing normal convolutions with adaptive convolutions in the generator. Experiments on CIFAR-10 dataset show that our modified models improve the baseline model by a large margin. Furthermore, our models achieve state-of-the-art performance on CIFAR-10 and STL-10 datasets in the unsupervised setting.