 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompoSE: Compositional Synthesis and Editing of 3D Shapes via Part-Aware Control
May 19, 2026Creating and editing high-quality 3D content remains a central challenge in computer graphics. We address this challenge by introducing CompoSE, a novel method for Compositional Synthesis and Editing of 3D shapes via part-aware control. Our method takes as input a set of coarse geometric primitives (e.g., bounding boxes) that represent distinct object parts arranged in a particular spatial configuration, and synthesizes as output part-separated 3D objects that support localized granular (i.e., compositional) editing of individual parts. The key insight that enables our method is our use of a diffusion transformer architecture that alternates between processing each part locally and aggregating contextual information across parts globally, and features a novel conditioning technique that ensures strong adherence to the user's input. Importantly, our method learns to infer part semantics and symmetries directly from the user's coarse layout guidance, and does not require part-level text prompts. We demonstrate that our method enables powerful part-level editing capabilities, including context-aware substitution, addition, deletion, and style-preserving resizing operations. We show through extensive experiments that our method significantly outperforms existing approaches on guided synthesis, as measured by objective metrics and LLM-based evaluations.
PatchRefiner V2: Fast and Lightweight Real-Domain High-Resolution Metric Depth Estimation
Jan 02, 2025While current high-resolution depth estimation methods achieve strong results, they often suffer from computational inefficiencies due to reliance on heavyweight models and multiple inference steps, increasing inference time. To address this, we introduce PatchRefiner V2 (PRV2), which replaces heavy refiner models with lightweight encoders. This reduces model size and inference time but introduces noisy features. To overcome this, we propose a Coarse-to-Fine (C2F) module with a Guided Denoising Unit for refining and denoising the refiner features and a Noisy Pretraining strategy to pretrain the refiner branch to fully exploit the potential of the lightweight refiner branch. Additionally, we introduce a Scale-and-Shift Invariant Gradient Matching (SSIGM) loss to enhance synthetic-to-real domain transfer. PRV2 outperforms state-of-the-art depth estimation methods on UnrealStereo4K in both accuracy and speed, using fewer parameters and faster inference. It also shows improved depth boundary delineation on real-world datasets like CityScape, ScanNet++, and KITTI, demonstrating its versatility across domains.
Amodal Depth Anything: Amodal Depth Estimation in the Wild
Dec 03, 2024Amodal depth estimation aims to predict the depth of occluded (invisible) parts of objects in a scene. This task addresses the question of whether models can effectively perceive the geometry of occluded regions based on visible cues. Prior methods primarily rely on synthetic datasets and focus on metric depth estimation, limiting their generalization to real-world settings due to domain shifts and scalability challenges. In this paper, we propose a novel formulation of amodal depth estimation in the wild, focusing on relative depth prediction to improve model generalization across diverse natural images. We introduce a new large-scale dataset, Amodal Depth In the Wild (ADIW), created using a scalable pipeline that leverages segmentation datasets and compositing techniques. Depth maps are generated using large pre-trained depth models, and a scale-and-shift alignment strategy is employed to refine and blend depth predictions, ensuring consistency in ground-truth annotations. To tackle the amodal depth task, we present two complementary frameworks: Amodal-DAV2, a deterministic model based on Depth Anything V2, and Amodal-DepthFM, a generative model that integrates conditional flow matching principles. Our proposed frameworks effectively leverage the capabilities of large pre-trained models with minimal modifications to achieve high-quality amodal depth predictions. Experiments validate our design choices, demonstrating the flexibility of our models in generating diverse, plausible depth structures for occluded regions. Our method achieves a 69.5% improvement in accuracy over the previous SoTA on the ADIW dataset.
PatchRefiner: Leveraging Synthetic Data for Real-Domain High-Resolution Monocular Metric Depth Estimation
Jun 10, 2024



This paper introduces PatchRefiner, an advanced framework for metric single image depth estimation aimed at high-resolution real-domain inputs. While depth estimation is crucial for applications such as autonomous driving, 3D generative modeling, and 3D reconstruction, achieving accurate high-resolution depth in real-world scenarios is challenging due to the constraints of existing architectures and the scarcity of detailed real-world depth data. PatchRefiner adopts a tile-based methodology, reconceptualizing high-resolution depth estimation as a refinement process, which results in notable performance enhancements. Utilizing a pseudo-labeling strategy that leverages synthetic data, PatchRefiner incorporates a Detail and Scale Disentangling (DSD) loss to enhance detail capture while maintaining scale accuracy, thus facilitating the effective transfer of knowledge from synthetic to real-world data. Our extensive evaluations demonstrate PatchRefiner's superior performance, significantly outperforming existing benchmarks on the Unreal4KStereo dataset by 18.1% in terms of the root mean squared error (RMSE) and showing marked improvements in detail accuracy and consistent scale estimation on diverse real-world datasets like CityScape, ScanNet++, and ETH3D.
EVP: Enhanced Visual Perception using Inverse Multi-Attentive Feature Refinement and Regularized Image-Text Alignment
Dec 13, 2023



This work presents the network architecture EVP (Enhanced Visual Perception). EVP builds on the previous work VPD which paved the way to use the Stable Diffusion network for computer vision tasks. We propose two major enhancements. First, we develop the Inverse Multi-Attentive Feature Refinement (IMAFR) module which enhances feature learning capabilities by aggregating spatial information from higher pyramid levels. Second, we propose a novel image-text alignment module for improved feature extraction of the Stable Diffusion backbone. The resulting architecture is suitable for a wide variety of tasks and we demonstrate its performance in the context of single-image depth estimation with a specialized decoder using classification-based bins and referring segmentation with an off-the-shelf decoder. Comprehensive experiments conducted on established datasets show that EVP achieves state-of-the-art results in single-image depth estimation for indoor (NYU Depth v2, 11.8% RMSE improvement over VPD) and outdoor (KITTI) environments, as well as referring segmentation (RefCOCO, 2.53 IoU improvement over ReLA). The code and pre-trained models are publicly available at https://github.com/Lavreniuk/EVP.
LooseControl: Lifting ControlNet for Generalized Depth Conditioning
Dec 05, 2023



We present LooseControl to allow generalized depth conditioning for diffusion-based image generation. ControlNet, the SOTA for depth-conditioned image generation, produces remarkable results but relies on having access to detailed depth maps for guidance. Creating such exact depth maps, in many scenarios, is challenging. This paper introduces a generalized version of depth conditioning that enables many new content-creation workflows. Specifically, we allow (C1) scene boundary control for loosely specifying scenes with only boundary conditions, and (C2) 3D box control for specifying layout locations of the target objects rather than the exact shape and appearance of the objects. Using LooseControl, along with text guidance, users can create complex environments (e.g., rooms, street views, etc.) by specifying only scene boundaries and locations of primary objects. Further, we provide two editing mechanisms to refine the results: (E1) 3D box editing enables the user to refine images by changing, adding, or removing boxes while freezing the style of the image. This yields minimal changes apart from changes induced by the edited boxes. (E2) Attribute editing proposes possible editing directions to change one particular aspect of the scene, such as the overall object density or a particular object. Extensive tests and comparisons with baselines demonstrate the generality of our method. We believe that LooseControl can become an important design tool for easily creating complex environments and be extended to other forms of guidance channels. Code and more information are available at https://shariqfarooq123.github.io/loose-control/ .
PatchFusion: An End-to-End Tile-Based Framework for High-Resolution Monocular Metric Depth Estimation
Dec 04, 2023



Single image depth estimation is a foundational task in computer vision and generative modeling. However, prevailing depth estimation models grapple with accommodating the increasing resolutions commonplace in today's consumer cameras and devices. Existing high-resolution strategies show promise, but they often face limitations, ranging from error propagation to the loss of high-frequency details. We present PatchFusion, a novel tile-based framework with three key components to improve the current state of the art: (1) A patch-wise fusion network that fuses a globally-consistent coarse prediction with finer, inconsistent tiled predictions via high-level feature guidance, (2) A Global-to-Local (G2L) module that adds vital context to the fusion network, discarding the need for patch selection heuristics, and (3) A Consistency-Aware Training (CAT) and Inference (CAI) approach, emphasizing patch overlap consistency and thereby eradicating the necessity for post-processing. Experiments on UnrealStereo4K, MVS-Synth, and Middleburry 2014 demonstrate that our framework can generate high-resolution depth maps with intricate details. PatchFusion is independent of the base model for depth estimation. Notably, our framework built on top of SOTA ZoeDepth brings improvements for a total of 17.3% and 29.4% in terms of the root mean squared error (RMSE) on UnrealStereo4K and MVS-Synth, respectively.
LLM Blueprint: Enabling Text-to-Image Generation with Complex and Detailed Prompts
Oct 16, 2023



Diffusion-based generative models have significantly advanced text-to-image generation but encounter challenges when processing lengthy and intricate text prompts describing complex scenes with multiple objects. While excelling in generating images from short, single-object descriptions, these models often struggle to faithfully capture all the nuanced details within longer and more elaborate textual inputs. In response, we present a novel approach leveraging Large Language Models (LLMs) to extract critical components from text prompts, including bounding box coordinates for foreground objects, detailed textual descriptions for individual objects, and a succinct background context. These components form the foundation of our layout-to-image generation model, which operates in two phases. The initial Global Scene Generation utilizes object layouts and background context to create an initial scene but often falls short in faithfully representing object characteristics as specified in the prompts. To address this limitation, we introduce an Iterative Refinement Scheme that iteratively evaluates and refines box-level content to align them with their textual descriptions, recomposing objects as needed to ensure consistency. Our evaluation on complex prompts featuring multiple objects demonstrates a substantial improvement in recall compared to baseline diffusion models. This is further validated by a user study, underscoring the efficacy of our approach in generating coherent and detailed scenes from intricate textual inputs.
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
Feb 23, 2023



This paper tackles the problem of depth estimation from a single image. Existing work either focuses on generalization performance disregarding metric scale, i.e. relative depth estimation, or state-of-the-art results on specific datasets, i.e. metric depth estimation. We propose the first approach that combines both worlds, leading to a model with excellent generalization performance while maintaining metric scale. Our flagship model, ZoeD-M12-NK, is pre-trained on 12 datasets using relative depth and fine-tuned on two datasets using metric depth. We use a lightweight head with a novel bin adjustment design called metric bins module for each domain. During inference, each input image is automatically routed to the appropriate head using a latent classifier. Our framework admits multiple configurations depending on the datasets used for relative depth pre-training and metric fine-tuning. Without pre-training, we can already significantly improve the state of the art (SOTA) on the NYU Depth v2 indoor dataset. Pre-training on twelve datasets and fine-tuning on the NYU Depth v2 indoor dataset, we can further improve SOTA for a total of 21% in terms of relative absolute error (REL). Finally, ZoeD-M12-NK is the first model that can jointly train on multiple datasets (NYU Depth v2 and KITTI) without a significant drop in performance and achieve unprecedented zero-shot generalization performance to eight unseen datasets from both indoor and outdoor domains. The code and pre-trained models are publicly available at https://github.com/isl-org/ZoeDepth .
LocalBins: Improving Depth Estimation by Learning Local Distributions
Mar 28, 2022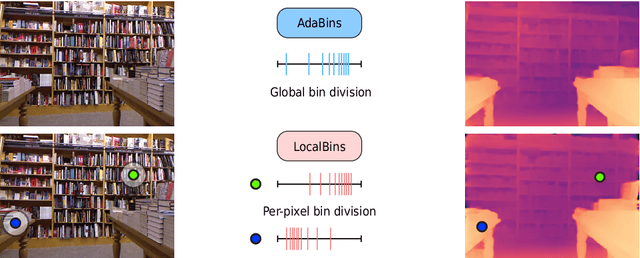



We propose a novel architecture for depth estimation from a single image. The architecture itself is based on the popular encoder-decoder architecture that is frequently used as a starting point for all dense regression tasks. We build on AdaBins which estimates a global distribution of depth values for the input image and evolve the architecture in two ways. First, instead of predicting global depth distributions, we predict depth distributions of local neighborhoods at every pixel. Second, instead of predicting depth distributions only towards the end of the decoder, we involve all layers of the decoder. We call this new architecture LocalBins. Our results demonstrate a clear improvement over the state-of-the-art in all metrics on the NYU-Depth V2 dataset. Code and pretrained models will be made publicly available.