 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAny Resolution Any Geometry: From Multi-View To Multi-Patch
Mar 03, 2026Joint estimation of surface normals and depth is essential for holistic 3D scene understanding, yet high-resolution prediction remains difficult due to the trade-off between preserving fine local detail and maintaining global consistency. To address this challenge, we propose the Ultra Resolution Geometry Transformer (URGT), which adapts the Visual Geometry Grounded Transformer (VGGT) into a unified multi-patch transformer for monocular high-resolution depth--normal estimation. A single high-resolution image is partitioned into patches that are augmented with coarse depth and normal priors from pre-trained models, and jointly processed in a single forward pass to predict refined geometric outputs. Global coherence is enforced through cross-patch attention, which enables long-range geometric reasoning and seamless propagation of information across patches within a shared backbone. To further enhance spatial robustness, we introduce a GridMix patch sampling strategy that probabilistically samples grid configurations during training, improving inter-patch consistency and generalization. Our method achieves state-of-the-art results on UnrealStereo4K, jointly improving depth and normal estimation, reducing AbsRel from 0.0582 to 0.0291, RMSE from 2.17 to 1.31, and lowering mean angular error from 23.36 degrees to 18.51 degrees, while producing sharper and more stable geometry. The proposed multi-patch framework also demonstrates strong zero-shot and cross-domain generalization and scales effectively to very high resolutions, offering an efficient and extensible solution for high-quality geometry refinement.
Delineate Anything Flow: Fast, Country-Level Field Boundary Detection from Any Source
Nov 17, 2025Accurate delineation of agricultural field boundaries from satellite imagery is essential for land management and crop monitoring, yet existing methods often produce incomplete boundaries, merge adjacent fields, and struggle to scale. We present the Delineate Anything Flow (DelAnyFlow) methodology, a resolution-agnostic approach for large-scale field boundary mapping. DelAnyFlow combines the DelAny instance segmentation model, based on a YOLOv11 backbone and trained on the large-scale Field Boundary Instance Segmentation-22M (FBIS 22M) dataset, with a structured post-processing, merging, and vectorization sequence to generate topologically consistent vector boundaries. FBIS 22M, the largest dataset of its kind, contains 672,909 multi-resolution image patches (0.25-10m) and 22.9million validated field instances. The DelAny model delivers state-of-the-art accuracy with over 100% higher mAP and 400x faster inference than SAM2. DelAny demonstrates strong zero-shot generalization and supports national-scale applications: using Sentinel 2 data for 2024, DelAnyFlow generated a complete field boundary layer for Ukraine (603,000km2) in under six hours on a single workstation. DelAnyFlow outputs significantly improve boundary completeness relative to operational products from Sinergise Solutions and NASA Harvest, particularly in smallholder and fragmented systems (0.25-1ha). For Ukraine, DelAnyFlow delineated 3.75M fields at 5m and 5.15M at 2.5m, compared to 2.66M detected by Sinergise Solutions and 1.69M by NASA Harvest. This work delivers a scalable, cost-effective methodology for field delineation in regions lacking digital cadastral data. A project landing page with links to model weights, code, national-scale vector outputs, and dataset is available at https://lavreniuk.github.io/Delineate-Anything/.
NTIRE 2025 Challenge on HR Depth from Images of Specular and Transparent Surfaces
Jun 06, 2025This paper reports on the NTIRE 2025 challenge on HR Depth From images of Specular and Transparent surfaces, held in conjunction with the New Trends in Image Restoration and Enhancement (NTIRE) workshop at CVPR 2025. This challenge aims to advance the research on depth estimation, specifically to address two of the main open issues in the field: high-resolution and non-Lambertian surfaces. The challenge proposes two tracks on stereo and single-image depth estimation, attracting about 177 registered participants. In the final testing stage, 4 and 4 participating teams submitted their models and fact sheets for the two tracks.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025


This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
Delineate Anything: Resolution-Agnostic Field Boundary Delineation on Satellite Imagery
Apr 03, 2025



The accurate delineation of agricultural field boundaries from satellite imagery is vital for land management and crop monitoring. However, current methods face challenges due to limited dataset sizes, resolution discrepancies, and diverse environmental conditions. We address this by reformulating the task as instance segmentation and introducing the Field Boundary Instance Segmentation - 22M dataset (FBIS-22M), a large-scale, multi-resolution dataset comprising 672,909 high-resolution satellite image patches (ranging from 0.25 m to 10 m) and 22,926,427 instance masks of individual fields, significantly narrowing the gap between agricultural datasets and those in other computer vision domains. We further propose Delineate Anything, an instance segmentation model trained on our new FBIS-22M dataset. Our proposed model sets a new state-of-the-art, achieving a substantial improvement of 88.5% in mAP@0.5 and 103% in mAP@0.5:0.95 over existing methods, while also demonstrating significantly faster inference and strong zero-shot generalization across diverse image resolutions and unseen geographic regions. Code, pre-trained models, and the FBIS-22M dataset are available at https://lavreniuk.github.io/Delineate-Anything.
Amodal Depth Anything: Amodal Depth Estimation in the Wild
Dec 03, 2024Amodal depth estimation aims to predict the depth of occluded (invisible) parts of objects in a scene. This task addresses the question of whether models can effectively perceive the geometry of occluded regions based on visible cues. Prior methods primarily rely on synthetic datasets and focus on metric depth estimation, limiting their generalization to real-world settings due to domain shifts and scalability challenges. In this paper, we propose a novel formulation of amodal depth estimation in the wild, focusing on relative depth prediction to improve model generalization across diverse natural images. We introduce a new large-scale dataset, Amodal Depth In the Wild (ADIW), created using a scalable pipeline that leverages segmentation datasets and compositing techniques. Depth maps are generated using large pre-trained depth models, and a scale-and-shift alignment strategy is employed to refine and blend depth predictions, ensuring consistency in ground-truth annotations. To tackle the amodal depth task, we present two complementary frameworks: Amodal-DAV2, a deterministic model based on Depth Anything V2, and Amodal-DepthFM, a generative model that integrates conditional flow matching principles. Our proposed frameworks effectively leverage the capabilities of large pre-trained models with minimal modifications to achieve high-quality amodal depth predictions. Experiments validate our design choices, demonstrating the flexibility of our models in generating diverse, plausible depth structures for occluded regions. Our method achieves a 69.5% improvement in accuracy over the previous SoTA on the ADIW dataset.
The Third Monocular Depth Estimation Challenge
Apr 27, 2024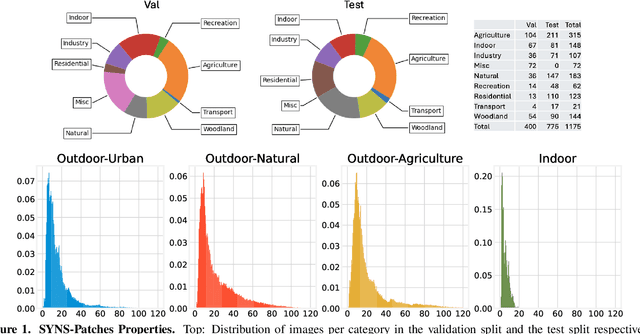

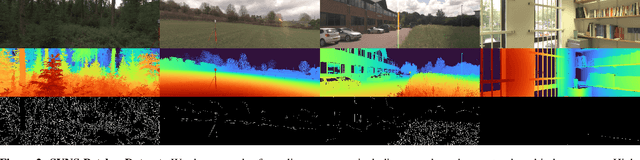
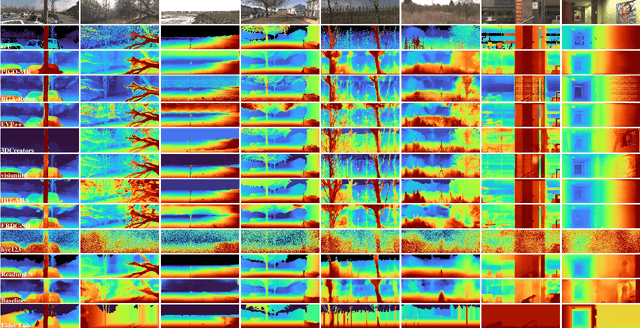
This paper discusses the results of the third edition of the Monocular Depth Estimation Challenge (MDEC). The challenge focuses on zero-shot generalization to the challenging SYNS-Patches dataset, featuring complex scenes in natural and indoor settings. As with the previous edition, methods can use any form of supervision, i.e. supervised or self-supervised. The challenge received a total of 19 submissions outperforming the baseline on the test set: 10 among them submitted a report describing their approach, highlighting a diffused use of foundational models such as Depth Anything at the core of their method. The challenge winners drastically improved 3D F-Score performance, from 17.51% to 23.72%.
SPIdepth: Strengthened Pose Information for Self-supervised Monocular Depth Estimation
Apr 18, 2024Self-supervised monocular depth estimation has garnered considerable attention for its applications in autonomous driving and robotics. While recent methods have made strides in leveraging techniques like the Self Query Layer (SQL) to infer depth from motion, they often overlook the potential of strengthening pose information. In this paper, we introduce SPIdepth, a novel approach that prioritizes enhancing the pose network for improved depth estimation. Building upon the foundation laid by SQL, SPIdepth emphasizes the importance of pose information in capturing fine-grained scene structures. By enhancing the pose network's capabilities, SPIdepth achieves remarkable advancements in scene understanding and depth estimation. Experimental results on benchmark datasets such as KITTI and Cityscapes showcase SPIdepth's state-of-the-art performance, surpassing previous methods by significant margins. Notably, SPIdepth's performance exceeds that of unsupervised models and, after finetuning on metric data, outperforms all existing methods. Remarkably, SPIdepth achieves these results using only a single image for inference, surpassing even methods that utilize video sequences for inference, thus demonstrating its efficacy and efficiency in real-world applications. Our approach represents a significant leap forward in self-supervised monocular depth estimation, underscoring the importance of strengthening pose information for advancing scene understanding in real-world applications.
EVP: Enhanced Visual Perception using Inverse Multi-Attentive Feature Refinement and Regularized Image-Text Alignment
Dec 13, 2023



This work presents the network architecture EVP (Enhanced Visual Perception). EVP builds on the previous work VPD which paved the way to use the Stable Diffusion network for computer vision tasks. We propose two major enhancements. First, we develop the Inverse Multi-Attentive Feature Refinement (IMAFR) module which enhances feature learning capabilities by aggregating spatial information from higher pyramid levels. Second, we propose a novel image-text alignment module for improved feature extraction of the Stable Diffusion backbone. The resulting architecture is suitable for a wide variety of tasks and we demonstrate its performance in the context of single-image depth estimation with a specialized decoder using classification-based bins and referring segmentation with an off-the-shelf decoder. Comprehensive experiments conducted on established datasets show that EVP achieves state-of-the-art results in single-image depth estimation for indoor (NYU Depth v2, 11.8% RMSE improvement over VPD) and outdoor (KITTI) environments, as well as referring segmentation (RefCOCO, 2.53 IoU improvement over ReLA). The code and pre-trained models are publicly available at https://github.com/Lavreniuk/EVP.