 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalcon Perception
Mar 28, 2026Perception-centric systems are typically implemented with a modular encoder-decoder pipeline: a vision backbone for feature extraction and a separate decoder (or late-fusion module) for task prediction. This raises a central question: is this architectural separation essential or can a single early-fusion stack do both perception and task modeling at scale? We introduce Falcon Perception, a unified dense Transformer that processes image patches and text tokens in a shared parameter space from the first layer, using a hybrid attention pattern (bidirectional among image tokens, causal for prediction tokens) to combine global visual context with autoregressive, variable-length instance generation. To keep dense outputs practical, Falcon Perception retains a lightweight token interface and decodes continuous spatial outputs with specialized heads, enabling parallel high-resolution mask prediction. Our design promotes simplicity: we keep a single scalable backbone and shift complexity toward data and training signals, adding only small heads where outputs are continuous and dense. On SA-Co, Falcon Perception improves mask quality to 68.0 Macro-F$_1$ compared to 62.3 of SAM3. We also introduce PBench, a benchmark targeting compositional prompts (OCR, spatial constraints, relations) and dense long-context regimes, where the model shows better gains. Finally, we extend the same early-fusion recipe to Falcon OCR: a compact 300M-parameter model which attains 80.3% on olmOCR and 88.64 on OmniDocBench.
VisRes Bench: On Evaluating the Visual Reasoning Capabilities of VLMs
Dec 24, 2025Vision-Language Models (VLMs) have achieved remarkable progress across tasks such as visual question answering and image captioning. Yet, the extent to which these models perform visual reasoning as opposed to relying on linguistic priors remains unclear. To address this, we introduce VisRes Bench, a benchmark designed to study visual reasoning in naturalistic settings without contextual language supervision. Analyzing model behavior across three levels of complexity, we uncover clear limitations in perceptual and relational visual reasoning capacities. VisRes isolates distinct reasoning abilities across its levels. Level 1 probes perceptual completion and global image matching under perturbations such as blur, texture changes, occlusion, and rotation; Level 2 tests rule-based inference over a single attribute (e.g., color, count, orientation); and Level 3 targets compositional reasoning that requires integrating multiple visual attributes. Across more than 19,000 controlled task images, we find that state-of-the-art VLMs perform near random under subtle perceptual perturbations, revealing limited abstraction beyond pattern recognition. We conclude by discussing how VisRes provides a unified framework for advancing abstract visual reasoning in multimodal research.
AMoE: Agglomerative Mixture-of-Experts Vision Foundation Model
Dec 23, 2025Vision foundation models trained via multi-teacher distillation offer a promising path toward unified visual representations, yet the learning dynamics and data efficiency of such approaches remain underexplored. In this paper, we systematically study multi-teacher distillation for vision foundation models and identify key factors that enable training at lower computational cost. We introduce Agglomerative Mixture-of-Experts Vision Foundation Models (AMoE), which distill knowledge from SigLIP2 and DINOv3 simultaneously into a Mixture-of-Experts student. We show that (1) our Asymmetric Relation-Knowledge Distillation loss preserves the geometric properties of each teacher while enabling effective knowledge transfer, (2) token-balanced batching that packs varying-resolution images into sequences with uniform token budgets stabilizes representation learning across resolutions without sacrificing performance, and (3) hierarchical clustering and sampling of training data--typically reserved for self-supervised learning--substantially improves sample efficiency over random sampling for multi-teacher distillation. By combining these findings, we curate OpenLVD200M, a 200M-image corpus that demonstrates superior efficiency for multi-teacher distillation. Instantiated in a Mixture-of-Experts. We release OpenLVD200M and distilled models.
AvatarMMC: 3D Head Avatar Generation and Editing with Multi-Modal Conditioning
Feb 08, 2024We introduce an approach for 3D head avatar generation and editing with multi-modal conditioning based on a 3D Generative Adversarial Network (GAN) and a Latent Diffusion Model (LDM). 3D GANs can generate high-quality head avatars given a single or no condition. However, it is challenging to generate samples that adhere to multiple conditions of different modalities. On the other hand, LDMs excel at learning complex conditional distributions. To this end, we propose to exploit the conditioning capabilities of LDMs to enable multi-modal control over the latent space of a pre-trained 3D GAN. Our method can generate and edit 3D head avatars given a mixture of control signals such as RGB input, segmentation masks, and global attributes. This provides better control over the generation and editing of synthetic avatars both globally and locally. Experiments show that our proposed approach outperforms a solely GAN-based approach both qualitatively and quantitatively on generation and editing tasks. To the best of our knowledge, our approach is the first to introduce multi-modal conditioning to 3D avatar generation and editing. \\href{avatarmmc-sig24.github.io}{Project Page}
COFS: Controllable Furniture layout Synthesis
May 29, 2022


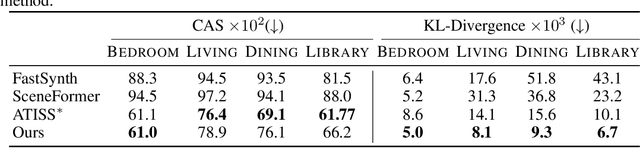
Scalable generation of furniture layouts is essential for many applications in virtual reality, augmented reality, game development and synthetic data generation. Many existing methods tackle this problem as a sequence generation problem which imposes a specific ordering on the elements of the layout making such methods impractical for interactive editing or scene completion. Additionally, most methods focus on generating layouts unconditionally and offer minimal control over the generated layouts. We propose COFS, an architecture based on standard transformer architecture blocks from language modeling. The proposed model is invariant to object order by design, removing the unnatural requirement of specifying an object generation order. Furthermore, the model allows for user interaction at multiple levels enabling fine grained control over the generation process. Our model consistently outperforms other methods which we verify by performing quantitative evaluations. Our method is also faster to train and sample from, compared to existing methods.
SketchGen: Generating Constrained CAD Sketches
Jun 04, 2021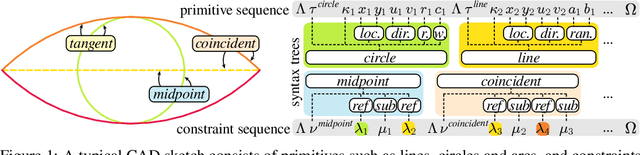

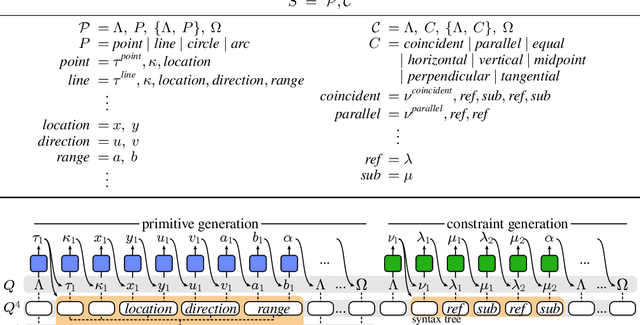
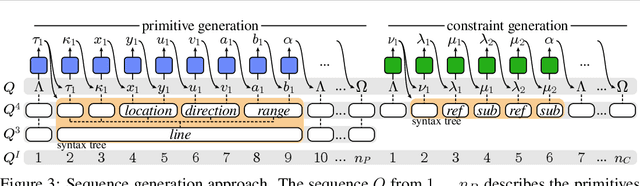
Computer-aided design (CAD) is the most widely used modeling approach for technical design. The typical starting point in these designs is 2D sketches which can later be extruded and combined to obtain complex three-dimensional assemblies. Such sketches are typically composed of parametric primitives, such as points, lines, and circular arcs, augmented with geometric constraints linking the primitives, such as coincidence, parallelism, or orthogonality. Sketches can be represented as graphs, with the primitives as nodes and the constraints as edges. Training a model to automatically generate CAD sketches can enable several novel workflows, but is challenging due to the complexity of the graphs and the heterogeneity of the primitives and constraints. In particular, each type of primitive and constraint may require a record of different size and parameter types. We propose SketchGen as a generative model based on a transformer architecture to address the heterogeneity problem by carefully designing a sequential language for the primitives and constraints that allows distinguishing between different primitive or constraint types and their parameters, while encouraging our model to re-use information across related parameters, encoding shared structure. A particular highlight of our work is the ability to produce primitives linked via constraints that enables the final output to be further regularized via a constraint solver. We evaluate our model by demonstrating constraint prediction for given sets of primitives and full sketch generation from scratch, showing that our approach significantly out performs the state-of-the-art in CAD sketch generation.
Facade Segmentation in the Wild
May 09, 2018



Urban facade segmentation from automatically acquired imagery, in contrast to traditional image segmentation, poses several unique challenges. 360-degree photospheres captured from vehicles are an effective way to capture a large number of images, but this data presents difficult-to-model warping and stitching artifacts. In addition, each pixel can belong to multiple facade elements, and different facade elements (e.g., window, balcony, sill, etc.) are correlated and vary wildly in their characteristics. In this paper, we propose three network architectures of varying complexity to achieve multilabel semantic segmentation of facade images while exploiting their unique characteristics. Specifically, we propose a MULTIFACSEGNET architecture to assign multiple labels to each pixel, a SEPARABLE architecture as a low-rank formulation that encourages extraction of rectangular elements, and a COMPATIBILITY network that simultaneously seeks segmentation across facade element types allowing the network to 'see' intermediate output probabilities of the various facade element classes. Our results on benchmark datasets show significant improvements over existing facade segmentation approaches for the typical facade elements. For example, on one commonly used dataset, the accuracy scores for window(the most important architectural element) increases from 0.91 to 0.97 percent compared to the best competing method, and comparable improvements on other element types.