 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOFS: Controllable Furniture layout Synthesis
Paper and Code



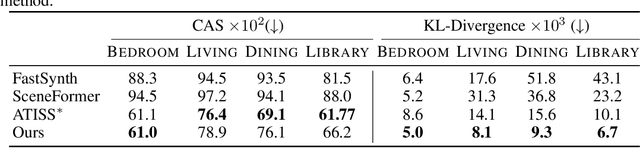
Scalable generation of furniture layouts is essential for many applications in virtual reality, augmented reality, game development and synthetic data generation. Many existing methods tackle this problem as a sequence generation problem which imposes a specific ordering on the elements of the layout making such methods impractical for interactive editing or scene completion. Additionally, most methods focus on generating layouts unconditionally and offer minimal control over the generated layouts. We propose COFS, an architecture based on standard transformer architecture blocks from language modeling. The proposed model is invariant to object order by design, removing the unnatural requirement of specifying an object generation order. Furthermore, the model allows for user interaction at multiple levels enabling fine grained control over the generation process. Our model consistently outperforms other methods which we verify by performing quantitative evaluations. Our method is also faster to train and sample from, compared to existing methods.