 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMF: Template-free and Rig-free Animation Transfer using Kinetic Codes
Apr 07, 2025Animation retargeting involves applying a sparse motion description (e.g., 2D/3D keypoint sequences) to a given character mesh to produce a semantically plausible and temporally coherent full-body motion. Existing approaches come with a mix of restrictions - they require annotated training data, assume access to template-based shape priors or artist-designed deformation rigs, suffer from limited generalization to unseen motion and/or shapes, or exhibit motion jitter. We propose Self-supervised Motion Fields (SMF) as a self-supervised framework that can be robustly trained with sparse motion representations, without requiring dataset specific annotations, templates, or rigs. At the heart of our method are Kinetic Codes, a novel autoencoder-based sparse motion encoding, that exposes a semantically rich latent space simplifying large-scale training. Our architecture comprises dedicated spatial and temporal gradient predictors, which are trained end-to-end. The resultant network, regularized by the Kinetic Codes's latent space, has good generalization across shapes and motions. We evaluated our method on unseen motion sampled from AMASS, D4D, Mixamo, and raw monocular video for animation transfer on various characters with varying shapes and topology. We report a new SoTA on the AMASS dataset in the context of generalization to unseen motion. Project webpage at https://motionfields.github.io/
Temporal Residual Jacobians For Rig-free Motion Transfer
Jul 20, 2024We introduce Temporal Residual Jacobians as a novel representation to enable data-driven motion transfer. Our approach does not assume access to any rigging or intermediate shape keyframes, produces geometrically and temporally consistent motions, and can be used to transfer long motion sequences. Central to our approach are two coupled neural networks that individually predict local geometric and temporal changes that are subsequently integrated, spatially and temporally, to produce the final animated meshes. The two networks are jointly trained, complement each other in producing spatial and temporal signals, and are supervised directly with 3D positional information. During inference, in the absence of keyframes, our method essentially solves a motion extrapolation problem. We test our setup on diverse meshes (synthetic and scanned shapes) to demonstrate its superiority in generating realistic and natural-looking animations on unseen body shapes against SoTA alternatives. Supplemental video and code are available at https://temporaljacobians.github.io/ .
Diffusion 3D Features (Diff3F): Decorating Untextured Shapes with Distilled Semantic Features
Nov 28, 2023



We present Diff3F as a simple, robust, and class-agnostic feature descriptor that can be computed for untextured input shapes (meshes or point clouds). Our method distills diffusion features from image foundational models onto input shapes. Specifically, we use the input shapes to produce depth and normal maps as guidance for conditional image synthesis, and in the process produce (diffusion) features in 2D that we subsequently lift and aggregate on the original surface. Our key observation is that even if the conditional image generations obtained from multi-view rendering of the input shapes are inconsistent, the associated image features are robust and can be directly aggregated across views. This produces semantic features on the input shapes, without requiring additional data or training. We perform extensive experiments on multiple benchmarks (SHREC'19, SHREC'20, and TOSCA) and demonstrate that our features, being semantic instead of geometric, produce reliable correspondence across both isometeric and non-isometrically related shape families.
BLiSS: Bootstrapped Linear Shape Space
Sep 04, 2023



Morphable models are fundamental to numerous human-centered processes as they offer a simple yet expressive shape space. Creating such morphable models, however, is both tedious and expensive. The main challenge is establishing dense correspondences across raw scans that capture sufficient shape variation. This is often addressed using a mix of significant manual intervention and non-rigid registration. We observe that creating a shape space and solving for dense correspondence are tightly coupled -- while dense correspondence is needed to build shape spaces, an expressive shape space provides a reduced dimensional space to regularize the search. We introduce BLiSS, a method to solve both progressively. Starting from a small set of manually registered scans to bootstrap the process, we enrich the shape space and then use that to get new unregistered scans into correspondence automatically. The critical component of BLiSS is a non-linear deformation model that captures details missed by the low-dimensional shape space, thus allowing progressive enrichment of the space.
GLASS: Geometric Latent Augmentation for Shape Spaces
Aug 09, 2021

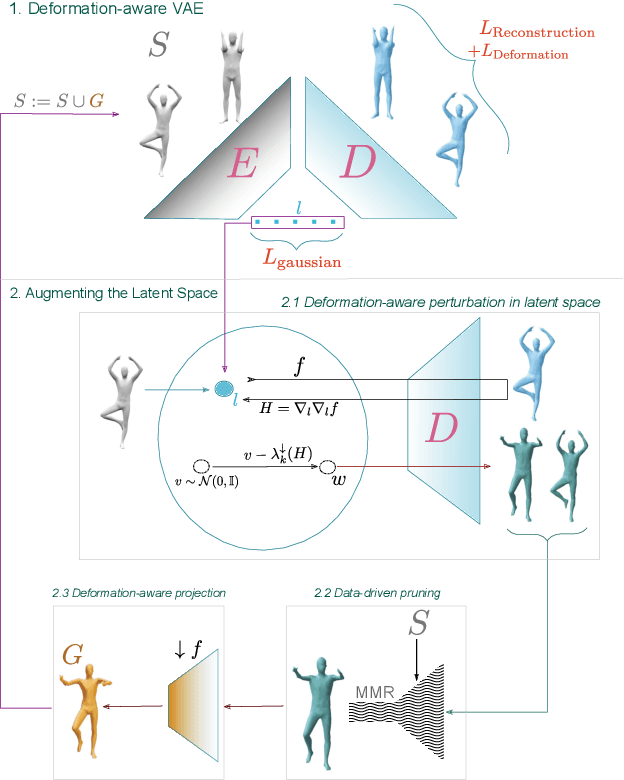

We investigate the problem of training generative models on a very sparse collection of 3D models. We use geometrically motivated energies to augment and thus boost a sparse collection of example (training) models. We analyze the Hessian of the as-rigid-as-possible (ARAP) energy to sample from and project to the underlying (local) shape space, and use the augmented dataset to train a variational autoencoder (VAE). We iterate the process of building latent spaces of VAE and augmenting the associated dataset, to progressively reveal a richer and more expressive generative space for creating geometrically and semantically valid samples. Our framework allows us to train generative 3D models even with a small set of good quality 3D models, which are typically hard to curate. We extensively evaluate our method against a set of strong baselines, provide ablation studies and demonstrate application towards establishing shape correspondences. We present multiple examples of interesting and meaningful shape variations even when starting from as few as 3-10 training shapes.
Tags2Parts: Discovering Semantic Regions from Shape Tags
Apr 30, 2018
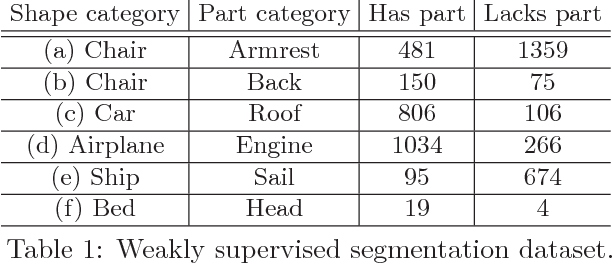
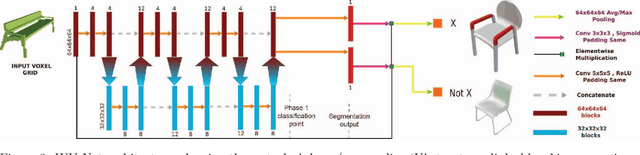

We propose a novel method for discovering shape regions that strongly correlate with user-prescribed tags. For example, given a collection of chairs tagged as either "has armrest" or "lacks armrest", our system correctly highlights the armrest regions as the main distinctive parts between the two chair types. To obtain point-wise predictions from shape-wise tags we develop a novel neural network architecture that is trained with tag classification loss, but is designed to rely on segmentation to predict the tag. Our network is inspired by U-Net, but we replicate shallow U structures several times with new skip connections and pooling layers, and call the resulting architecture "WU-Net". We test our method on segmentation benchmarks and show that even with weak supervision of whole shape tags, our method can infer meaningful semantic regions, without ever observing shape segmentations. Further, once trained, the model can process shapes for which the tag is entirely unknown. As a bonus, our architecture is directly operational under full supervision and performs strongly on standard benchmarks. We validate our method through experiments with many variant architectures and prior baselines, and demonstrate several applications.