 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDancingBox: A Lightweight MoCap System for Character Animation from Physical Proxies
Mar 18, 2026Creating compelling 3D character animations typically requires either expert use of professional software or expensive motion capture systems operated by skilled actors. We present DancingBox, a lightweight, vision-based system that makes motion capture accessible to novices by reimagining the process as digital puppetry. Instead of tracking precise human motions, DancingBox captures the approximate movements of everyday objects manipulated by users with a single webcam. These coarse proxy motions are then refined into realistic character animations by conditioning a generative motion model on bounding-box representations, enriched with human motion priors learned from large-scale datasets. To overcome the lack of paired proxy-animation data, we synthesize training pairs by converting existing motion capture sequences into proxy representations. A user study demonstrates that DancingBox enables intuitive and creative character animation using diverse proxies, from plush toys to bananas, lowering the barrier to entry for novice animators.
Beyond the Visible: Disocclusion-Aware Editing via Proxy Dynamic Graphs
Dec 16, 2025



We address image-to-video generation with explicit user control over the final frame's disoccluded regions. Current image-to-video pipelines produce plausible motion but struggle to generate predictable, articulated motions while enforcing user-specified content in newly revealed areas. Our key idea is to separate motion specification from appearance synthesis: we introduce a lightweight, user-editable Proxy Dynamic Graph (PDG) that deterministically yet approximately drives part motion, while a frozen diffusion prior is used to synthesize plausible appearance that follows that motion. In our training-free pipeline, the user loosely annotates and reposes a PDG, from which we compute a dense motion flow to leverage diffusion as a motion-guided shader. We then let the user edit appearance in the disoccluded areas of the image, and exploit the visibility information encoded by the PDG to perform a latent-space composite that reconciles motion with user intent in these areas. This design yields controllable articulation and user control over disocclusions without fine-tuning. We demonstrate clear advantages against state-of-the-art alternatives towards images turned into short videos of articulated objects, furniture, vehicles, and deformables. Our method mixes generative control, in the form of loose pose and structure, with predictable controls, in the form of appearance specification in the final frame in the disoccluded regions, unlocking a new image-to-video workflow. Code will be released on acceptance. Project page: https://anranqi.github.io/beyond-visible.github.io/
An evaluation of SVBRDF Prediction from Generative Image Models for Appearance Modeling of 3D Scenes
Dec 15, 2025Digital content creation is experiencing a profound change with the advent of deep generative models. For texturing, conditional image generators now allow the synthesis of realistic RGB images of a 3D scene that align with the geometry of that scene. For appearance modeling, SVBRDF prediction networks recover material parameters from RGB images. Combining these technologies allows us to quickly generate SVBRDF maps for multiple views of a 3D scene, which can be merged to form a SVBRDF texture atlas of that scene. In this paper, we analyze the challenges and opportunities for SVBRDF prediction in the context of such a fast appearance modeling pipeline. On the one hand, single-view SVBRDF predictions might suffer from multiview incoherence and yield inconsistent texture atlases. On the other hand, generated RGB images, and the different modalities on which they are conditioned, can provide additional information for SVBRDF estimation compared to photographs. We compare neural architectures and conditions to identify designs that achieve high accuracy and coherence. We find that, surprisingly, a standard UNet is competitive with more complex designs. Project page: http://repo-sam.inria.fr/nerphys/svbrdf-evaluation
* Project page: http://repo-sam.inria.fr/nerphys/svbrdf-evaluation Code: http://github.com/graphdeco-inria/svbrdf-evaluation
DiffCSG: Differentiable CSG via Rasterization
Sep 02, 2024Differentiable rendering is a key ingredient for inverse rendering and machine learning, as it allows to optimize scene parameters (shape, materials, lighting) to best fit target images. Differentiable rendering requires that each scene parameter relates to pixel values through differentiable operations. While 3D mesh rendering algorithms have been implemented in a differentiable way, these algorithms do not directly extend to Constructive-Solid-Geometry (CSG), a popular parametric representation of shapes, because the underlying boolean operations are typically performed with complex black-box mesh-processing libraries. We present an algorithm, DiffCSG, to render CSG models in a differentiable manner. Our algorithm builds upon CSG rasterization, which displays the result of boolean operations between primitives without explicitly computing the resulting mesh and, as such, bypasses black-box mesh processing. We describe how to implement CSG rasterization within a differentiable rendering pipeline, taking special care to apply antialiasing along primitive intersections to obtain gradients in such critical areas. Our algorithm is simple and fast, can be easily incorporated into modern machine learning setups, and enables a range of applications for computer-aided design, including direct and image-based editing of CSG primitives. Code and data: https://yyyyyhc.github.io/DiffCSG/.
CADTalk: An Algorithm and Benchmark for Semantic Commenting of CAD Programs
Nov 30, 2023



CAD programs are a popular way to compactly encode shapes as a sequence of operations that are easy to parametrically modify. However, without sufficient semantic comments and structure, such programs can be challenging to understand, let alone modify. We introduce the problem of semantic commenting CAD programs, wherein the goal is to segment the input program into code blocks corresponding to semantically meaningful shape parts and assign a semantic label to each block. We solve the problem by combining program parsing with visual-semantic analysis afforded by recent advances in foundational language and vision models. Specifically, by executing the input programs, we create shapes, which we use to generate conditional photorealistic images to make use of semantic annotators for such images. We then distill the information across the images and link back to the original programs to semantically comment on them. Additionally, we collected and annotated a benchmark dataset, CADTalk, consisting of 5,280 machine-made programs and 45 human-made programs with ground truth semantic comments to foster future research. We extensively evaluated our approach, compared to a GPT-based baseline approach, and an open-set shape segmentation baseline, i.e., PartSLIP, and reported an 83.24% accuracy on the new CADTalk dataset. Project page: https://enigma-li.github.io/CADTalk/.
Deep scene-scale material estimation from multi-view indoor captures
Nov 15, 2022


The movie and video game industries have adopted photogrammetry as a way to create digital 3D assets from multiple photographs of a real-world scene. But photogrammetry algorithms typically output an RGB texture atlas of the scene that only serves as visual guidance for skilled artists to create material maps suitable for physically-based rendering. We present a learning-based approach that automatically produces digital assets ready for physically-based rendering, by estimating approximate material maps from multi-view captures of indoor scenes that are used with retopologized geometry. We base our approach on a material estimation Convolutional Neural Network (CNN) that we execute on each input image. We leverage the view-dependent visual cues provided by the multiple observations of the scene by gathering, for each pixel of a given image, the color of the corresponding point in other images. This image-space CNN provides us with an ensemble of predictions, which we merge in texture space as the last step of our approach. Our results demonstrate that the recovered assets can be directly used for physically-based rendering and editing of real indoor scenes from any viewpoint and novel lighting. Our method generates approximate material maps in a fraction of time compared to the closest previous solutions.
* 17 pages
Guided Fine-Tuning for Large-Scale Material Transfer
Jul 08, 2020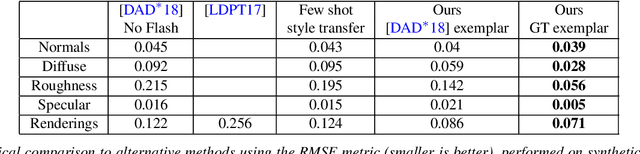
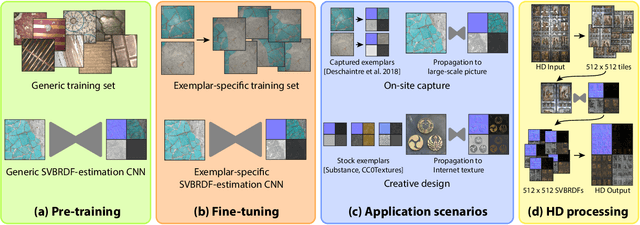
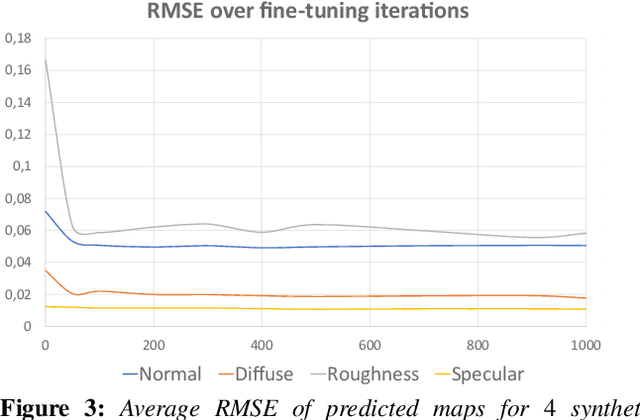

We present a method to transfer the appearance of one or a few exemplar SVBRDFs to a target image representing similar materials. Our solution is extremely simple: we fine-tune a deep appearance-capture network on the provided exemplars, such that it learns to extract similar SVBRDF values from the target image. We introduce two novel material capture and design workflows that demonstrate the strength of this simple approach. Our first workflow allows to produce plausible SVBRDFs of large-scale objects from only a few pictures. Specifically, users only need take a single picture of a large surface and a few close-up flash pictures of some of its details. We use existing methods to extract SVBRDF parameters from the close-ups, and our method to transfer these parameters to the entire surface, enabling the lightweight capture of surfaces several meters wide such as murals, floors and furniture. In our second workflow, we provide a powerful way for users to create large SVBRDFs from internet pictures by transferring the appearance of existing, pre-designed SVBRDFs. By selecting different exemplars, users can control the materials assigned to the target image, greatly enhancing the creative possibilities offered by deep appearance capture.
3D Sketching using Multi-View Deep Volumetric Prediction
Jun 19, 2018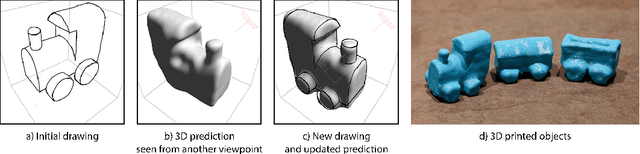

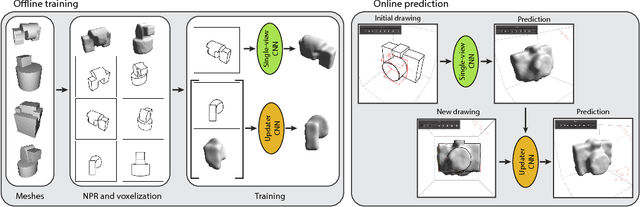

Sketch-based modeling strives to bring the ease and immediacy of drawing to the 3D world. However, while drawings are easy for humans to create, they are very challenging for computers to interpret due to their sparsity and ambiguity. We propose a data-driven approach that tackles this challenge by learning to reconstruct 3D shapes from one or more drawings. At the core of our approach is a deep convolutional neural network (CNN) that predicts occupancy of a voxel grid from a line drawing. This CNN provides us with an initial 3D reconstruction as soon as the user completes a single drawing of the desired shape. We complement this single-view network with an updater CNN that refines an existing prediction given a new drawing of the shape created from a novel viewpoint. A key advantage of our approach is that we can apply the updater iteratively to fuse information from an arbitrary number of viewpoints, without requiring explicit stroke correspondences between the drawings. We train both CNNs by rendering synthetic contour drawings from hand-modeled shape collections as well as from procedurally-generated abstract shapes. Finally, we integrate our CNNs in a minimal modeling interface that allows users to seamlessly draw an object, rotate it to see its 3D reconstruction, and refine it by re-drawing from another vantage point using the 3D reconstruction as guidance. The main strengths of our approach are its robustness to freehand bitmap drawings, its ability to adapt to different object categories, and the continuum it offers between single-view and multi-view sketch-based modeling.