 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Augmentation: Calibration-free Camera Distortion Model Estimation for Real-time Mixed-reality Consistency
Mar 03, 2025
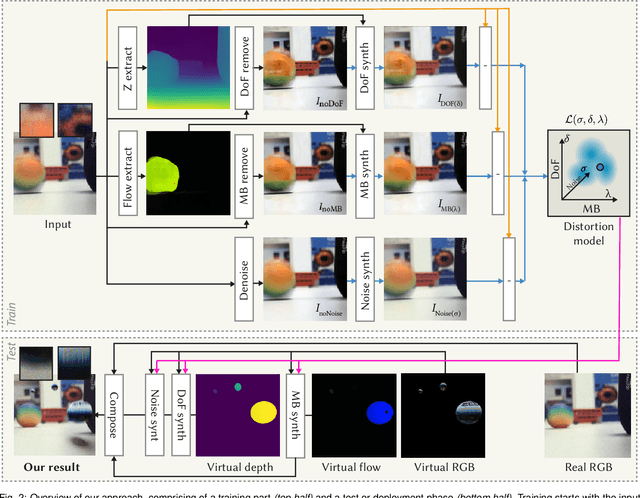
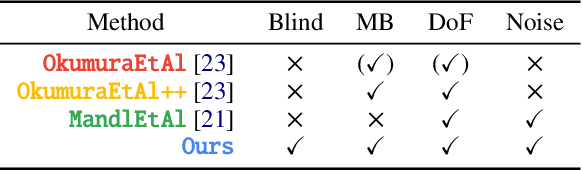

Real camera footage is subject to noise, motion blur (MB) and depth of field (DoF). In some applications these might be considered distortions to be removed, but in others it is important to model them because it would be ineffective, or interfere with an aesthetic choice, to simply remove them. In augmented reality applications where virtual content is composed into a live video feed, we can model noise, MB and DoF to make the virtual content visually consistent with the video. Existing methods for this typically suffer two main limitations. First, they require a camera calibration step to relate a known calibration target to the specific cameras response. Second, existing work require methods that can be (differentiably) tuned to the calibration, such as slow and specialized neural networks. We propose a method which estimates parameters for noise, MB and DoF instantly, which allows using off-the-shelf real-time simulation methods from e.g., a game engine in compositing augmented content. Our main idea is to unlock both features by showing how to use modern computer vision methods that can remove noise, MB and DoF from the video stream, essentially providing self-calibration. This allows to auto-tune any black-box real-time noise+MB+DoF method to deliver fast and high-fidelity augmentation consistency.
Deep scene-scale material estimation from multi-view indoor captures
Nov 15, 2022


The movie and video game industries have adopted photogrammetry as a way to create digital 3D assets from multiple photographs of a real-world scene. But photogrammetry algorithms typically output an RGB texture atlas of the scene that only serves as visual guidance for skilled artists to create material maps suitable for physically-based rendering. We present a learning-based approach that automatically produces digital assets ready for physically-based rendering, by estimating approximate material maps from multi-view captures of indoor scenes that are used with retopologized geometry. We base our approach on a material estimation Convolutional Neural Network (CNN) that we execute on each input image. We leverage the view-dependent visual cues provided by the multiple observations of the scene by gathering, for each pixel of a given image, the color of the corresponding point in other images. This image-space CNN provides us with an ensemble of predictions, which we merge in texture space as the last step of our approach. Our results demonstrate that the recovered assets can be directly used for physically-based rendering and editing of real indoor scenes from any viewpoint and novel lighting. Our method generates approximate material maps in a fraction of time compared to the closest previous solutions.
* 17 pages