 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent learning: episodic memory complements parametric learning by enabling flexible reuse of experiences
Sep 19, 2025When do machine learning systems fail to generalize, and what mechanisms could improve their generalization? Here, we draw inspiration from cognitive science to argue that one weakness of machine learning systems is their failure to exhibit latent learning -- learning information that is not relevant to the task at hand, but that might be useful in a future task. We show how this perspective links failures ranging from the reversal curse in language modeling to new findings on agent-based navigation. We then highlight how cognitive science points to episodic memory as a potential part of the solution to these issues. Correspondingly, we show that a system with an oracle retrieval mechanism can use learning experiences more flexibly to generalize better across many of these challenges. We also identify some of the essential components for effectively using retrieval, including the importance of within-example in-context learning for acquiring the ability to use information across retrieved examples. In summary, our results illustrate one possible contributor to the relative data inefficiency of current machine learning systems compared to natural intelligence, and help to understand how retrieval methods can complement parametric learning to improve generalization.
Can foundation models actively gather information in interactive environments to test hypotheses?
Dec 09, 2024



While problem solving is a standard evaluation task for foundation models, a crucial component of problem solving -- actively and strategically gathering information to test hypotheses -- has not been closely investigated. To assess the information gathering abilities of foundation models in interactive environments, we introduce a framework in which a model must determine the factors influencing a hidden reward function by iteratively reasoning about its previously gathered information and proposing its next exploratory action to maximize information gain at each step. We implement this framework in both a text-based environment, which offers a tightly controlled setting and enables high-throughput parameter sweeps, and in an embodied 3D environment, which requires addressing complexities of multi-modal interaction more relevant to real-world applications. We further investigate whether approaches such as self-correction and increased inference time improve information gathering efficiency. In a relatively simple task that requires identifying a single rewarding feature, we find that LLM's information gathering capability is close to optimal. However, when the model must identify a conjunction of rewarding features, performance is suboptimal. The hit in performance is due partly to the model translating task description to a policy and partly to the model's effectiveness in using its in-context memory. Performance is comparable in both text and 3D embodied environments, although imperfect visual object recognition reduces its accuracy in drawing conclusions from gathered information in the 3D embodied case. For single-feature-based rewards, we find that smaller models curiously perform better; for conjunction-based rewards, incorporating self correction into the model improves performance.
VAE-Loco: Versatile Quadruped Locomotion by Learning a Disentangled Gait Representation
May 02, 2022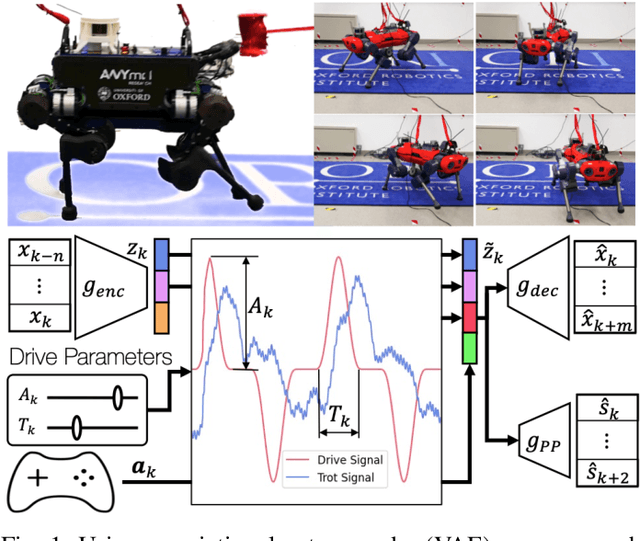
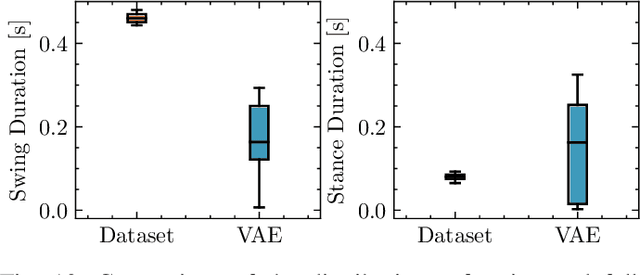
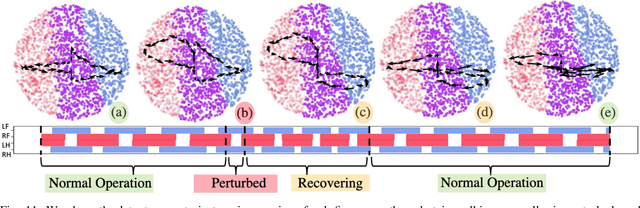
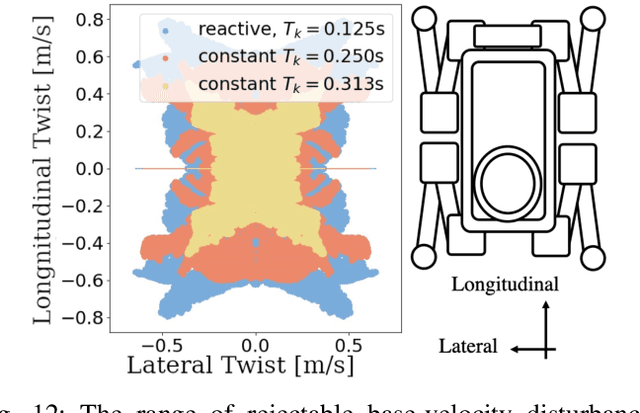
Quadruped locomotion is rapidly maturing to a degree where robots now routinely traverse a variety of unstructured terrains. However, while gaits can be varied typically by selecting from a range of pre-computed styles, current planners are unable to vary key gait parameters continuously while the robot is in motion. The synthesis, on-the-fly, of gaits with unexpected operational characteristics or even the blending of dynamic manoeuvres lies beyond the capabilities of the current state-of-the-art. In this work we address this limitation by learning a latent space capturing the key stance phases constituting a particular gait. This is achieved via a generative model trained on a single trot style, which encourages disentanglement such that application of a drive signal to a single dimension of the latent state induces holistic plans synthesising a continuous variety of trot styles. We demonstrate that specific properties of the drive signal map directly to gait parameters such as cadence, footstep height and full stance duration. Due to the nature of our approach these synthesised gaits are continuously variable online during robot operation and robustly capture a richness of movement significantly exceeding the relatively narrow behaviour seen during training. In addition, the use of a generative model facilitates the detection and mitigation of disturbances to provide a versatile and robust planning framework. We evaluate our approach on two versions of the real ANYmal quadruped robots and demonstrate that our method achieves a continuous blend of dynamic trot styles whilst being robust and reactive to external perturbations.
Next Steps: Learning a Disentangled Gait Representation for Versatile Quadruped Locomotion
Dec 09, 2021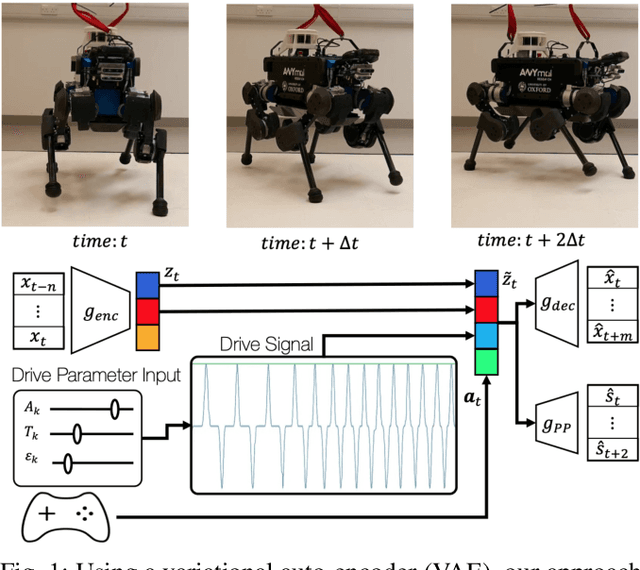
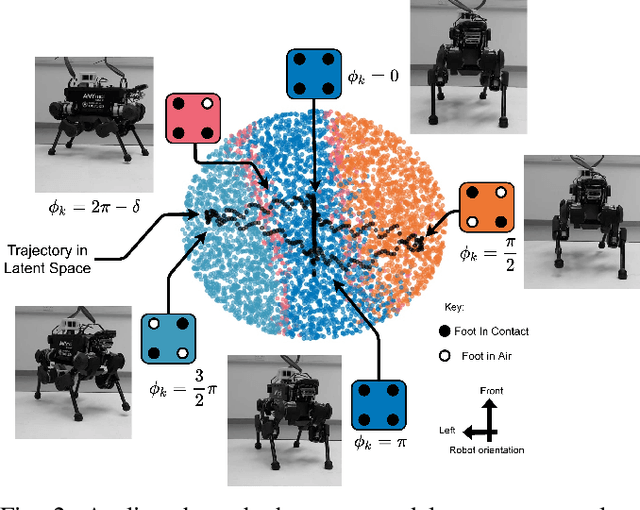
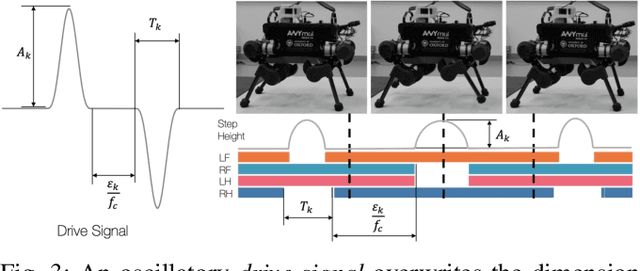

Quadruped locomotion is rapidly maturing to a degree where robots now routinely traverse a variety of unstructured terrains. However, while gaits can be varied typically by selecting from a range of pre-computed styles, current planners are unable to vary key gait parameters continuously while the robot is in motion. The synthesis, on-the-fly, of gaits with unexpected operational characteristics or even the blending of dynamic manoeuvres lies beyond the capabilities of the current state-of-the-art. In this work we address this limitation by learning a latent space capturing the key stance phases constituting a particular gait. This is achieved via a generative model trained on a single trot style, which encourages disentanglement such that application of a drive signal to a single dimension of the latent state induces holistic plans synthesising a continuous variety of trot styles. We demonstrate that specific properties of the drive signal map directly to gait parameters such as cadence, foot step height and full stance duration. Due to the nature of our approach these synthesised gaits are continuously variable online during robot operation and robustly capture a richness of movement significantly exceeding the relatively narrow behaviour seen during training. In addition, the use of a generative model facilitates the detection and mitigation of disturbances to provide a versatile and robust planning framework. We evaluate our approach on a real ANYmal quadruped robot and demonstrate that our method achieves a continuous blend of dynamic trot styles whilst being robust and reactive to external perturbations.
Universal Approximation of Functions on Sets
Jul 05, 2021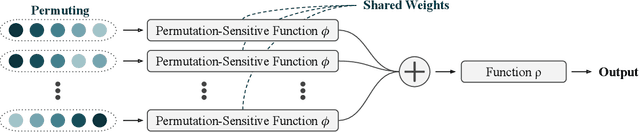
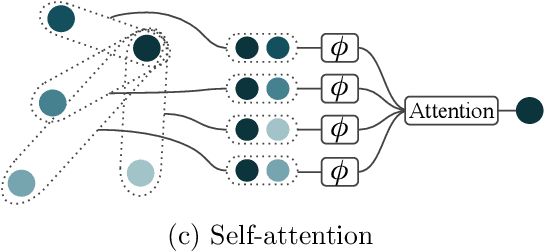
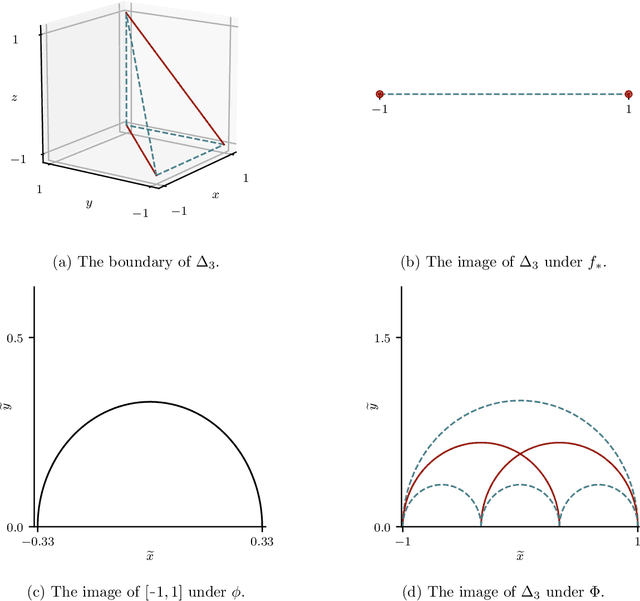
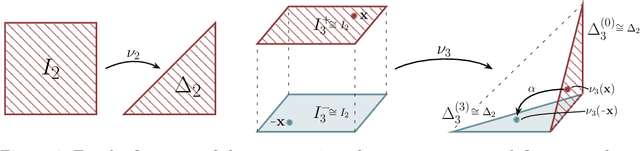
Modelling functions of sets, or equivalently, permutation-invariant functions, is a long-standing challenge in machine learning. Deep Sets is a popular method which is known to be a universal approximator for continuous set functions. We provide a theoretical analysis of Deep Sets which shows that this universal approximation property is only guaranteed if the model's latent space is sufficiently high-dimensional. If the latent space is even one dimension lower than necessary, there exist piecewise-affine functions for which Deep Sets performs no better than a na\"ive constant baseline, as judged by worst-case error. Deep Sets may be viewed as the most efficient incarnation of the Janossy pooling paradigm. We identify this paradigm as encompassing most currently popular set-learning methods. Based on this connection, we discuss the implications of our results for set learning more broadly, and identify some open questions on the universality of Janossy pooling in general.
APEX: Unsupervised, Object-Centric Scene Segmentation and Tracking for Robot Manipulation
May 31, 2021
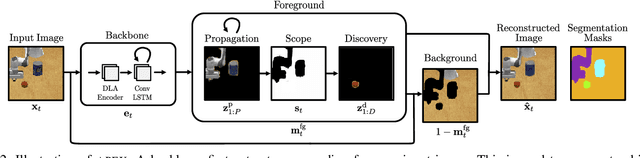
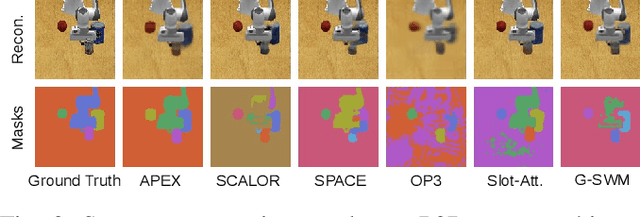

Recent advances in unsupervised learning for object detection, segmentation, and tracking hold significant promise for applications in robotics. A common approach is to frame these tasks as inference in probabilistic latent-variable models. In this paper, however, we show that the current state-of-the-art struggles with visually complex scenes such as typically encountered in robot manipulation tasks. We propose APEX, a new latent-variable model which is able to segment and track objects in more realistic scenes featuring objects that vary widely in size and texture, including the robot arm itself. This is achieved by a principled mask normalisation algorithm and a high-resolution scene encoder. To evaluate our approach, we present results on the real-world Sketchy dataset. This dataset, however, does not contain ground truth masks and object IDs for a quantitative evaluation. We thus introduce the Panda Pushing Dataset (P2D) which shows a Panda arm interacting with objects on a table in simulation and which includes ground-truth segmentation masks and object IDs for tracking. In both cases, APEX comprehensively outperforms the current state-of-the-art in unsupervised object segmentation and tracking. We demonstrate the efficacy of our segmentations for robot skill execution on an object arrangement task, where we also achieve the best or comparable performance among all the baselines.
GENESIS-V2: Inferring Unordered Object Representations without Iterative Refinement
Apr 21, 2021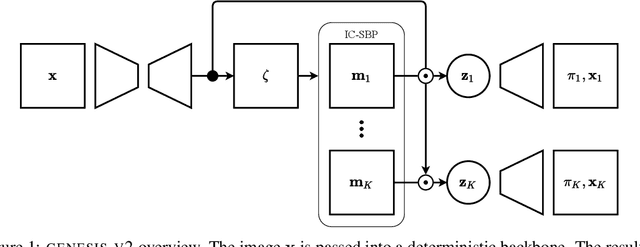

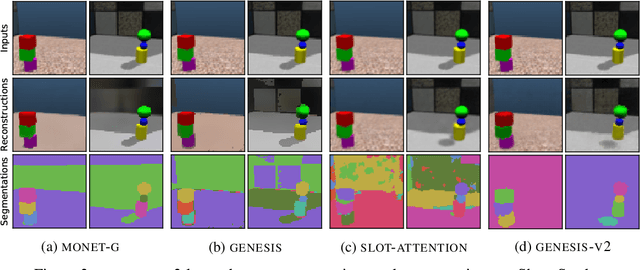
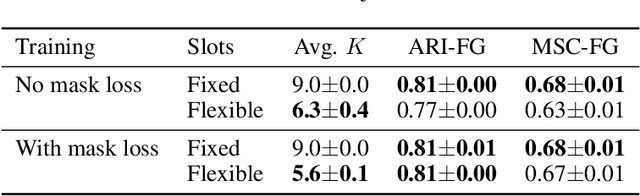
Advances in object-centric generative models (OCGMs) have culminated in the development of a broad range of methods for unsupervised object segmentation and interpretable object-centric scene generation. These methods, however, are limited to simulated and real-world datasets with limited visual complexity. Moreover, object representations are often inferred using RNNs which do not scale well to large images or iterative refinement which avoids imposing an unnatural ordering on objects in an image but requires the a priori initialisation of a fixed number of object representations. In contrast to established paradigms, this work proposes an embedding-based approach in which embeddings of pixels are clustered in a differentiable fashion using a stochastic, non-parametric stick-breaking process. Similar to iterative refinement, this clustering procedure also leads to randomly ordered object representations, but without the need of initialising a fixed number of clusters a priori. This is used to develop a new model, GENESIS-V2, which can infer a variable number of object representations without using RNNs or iterative refinement. We show that GENESIS-V2 outperforms previous methods for unsupervised image segmentation and object-centric scene generation on established synthetic datasets as well as more complex real-world datasets.
Reconstruction Bottlenecks in Object-Centric Generative Models
Jul 13, 2020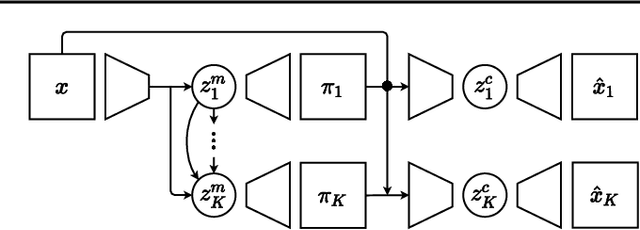
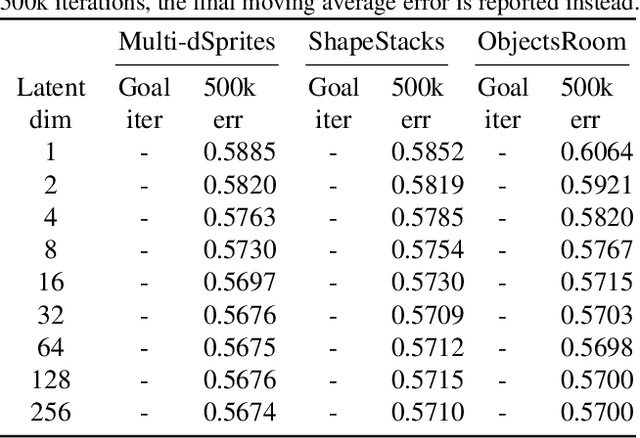
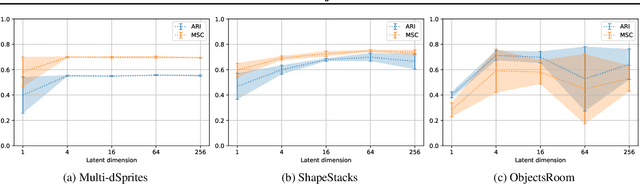
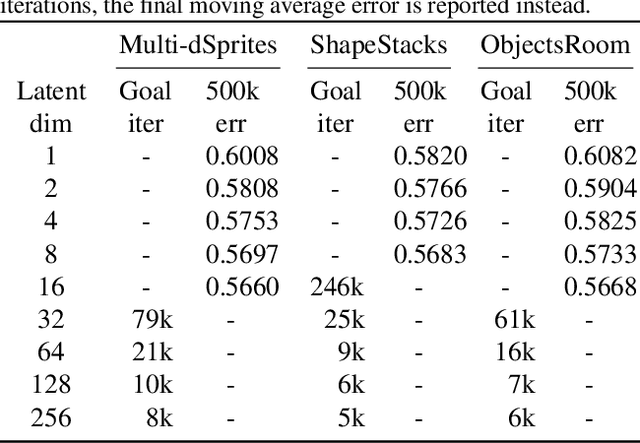
A range of methods with suitable inductive biases exist to learn interpretable object-centric representations of images without supervision. However, these are largely restricted to visually simple images; robust object discovery in real-world sensory datasets remains elusive. To increase the understanding of such inductive biases, we empirically investigate the role of "reconstruction bottlenecks" for scene decomposition in GENESIS, a recent VAE-based model. We show such bottlenecks determine reconstruction and segmentation quality and critically influence model behaviour.
First Steps: Latent-Space Control with Semantic Constraints for Quadruped Locomotion
Jul 03, 2020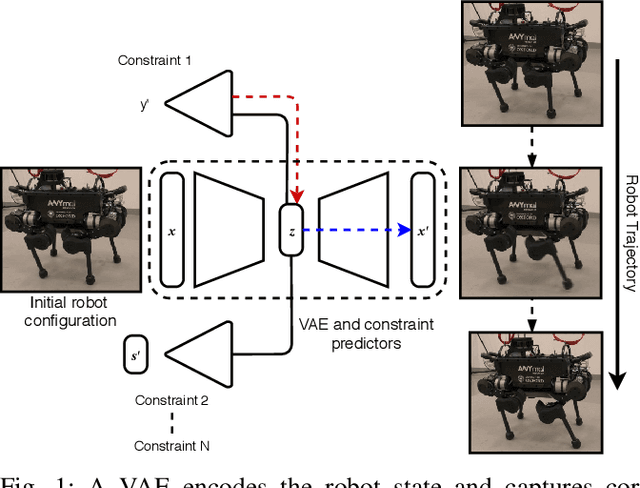

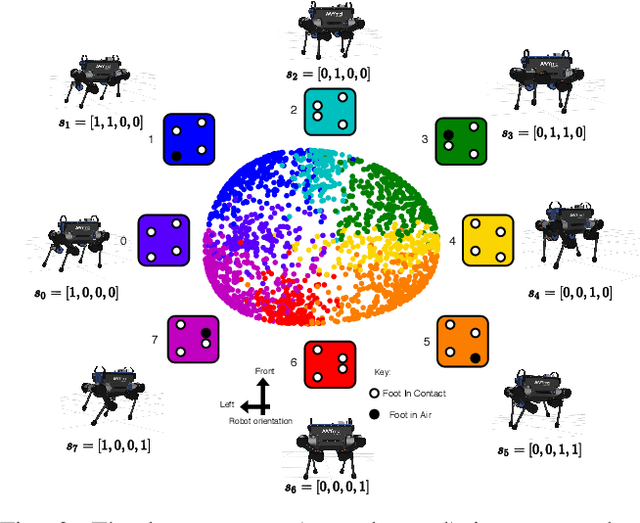
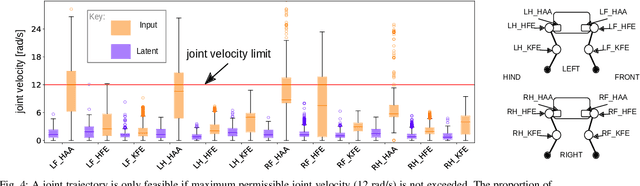
Traditional approaches to quadruped control frequently employ simplified, hand-derived models. This significantly reduces the capability of the robot since its effective kinematic range is curtailed. In addition, kinodynamic constraints are often non-differentiable and difficult to implement in an optimisation approach. In this work, these challenges are addressed by framing quadruped control as optimisation in a structured latent space. A deep generative model captures a statistical representation of feasible joint configurations, whilst complex dynamic and terminal constraints are expressed via high-level, semantic indicators and represented by learned classifiers operating upon the latent space. As a consequence, complex constraints are rendered differentiable and evaluated an order of magnitude faster than analytical approaches. We validate the feasibility of locomotion trajectories optimised using our approach both in simulation and on a real-world ANYmal quadruped. Our results demonstrate that this approach is capable of generating smooth and realisable trajectories. To the best of our knowledge, this is the first time latent space control has been successfully applied to a complex, real robot platform.
RELATE: Physically Plausible Multi-Object Scene Synthesis Using Structured Latent Spaces
Jul 02, 2020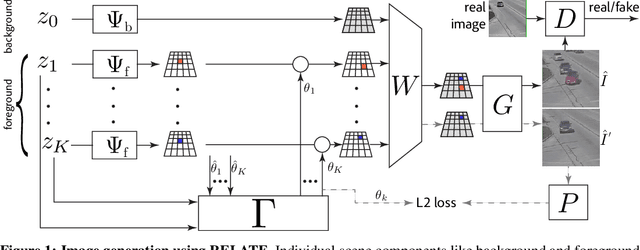

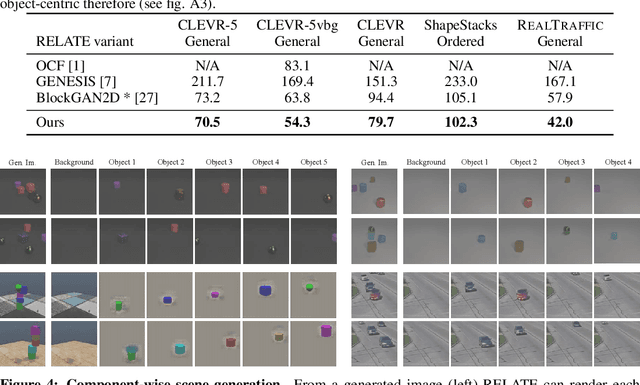

We present RELATE, a model that learns to generate physically plausible scenes and videos of multiple interacting objects. Similar to other generative approaches, RELATE is trained end-to-end on raw, unlabeled data. RELATE combines an object-centric GAN formulation with a model that explicitly accounts for correlations between individual objects. This allows the model to generate realistic scenes and videos from a physically-interpretable parameterization. Furthermore, we show that modeling the object correlation is necessary to learn to disentangle object positions and identity. We find that RELATE is also amenable to physically realistic scene editing and that it significantly outperforms prior art in object-centric scene generation in both synthetic (CLEVR, ShapeStacks) and real-world data (street traffic scenes). In addition, in contrast to state-of-the-art methods in object-centric generative modeling, RELATE also extends naturally to dynamic scenes and generates videos of high visual fidelity