 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Based Reasoning with Topology-Encoded Graphs for Anatomical Path Disambiguation in Robot-Assisted Endovascular Navigation
Feb 23, 2026Robotic-assisted percutaneous coronary intervention (PCI) is constrained by the inherent limitations of 2D Digital Subtraction Angiography (DSA). Unlike physicians, who can directly manipulate guidewires and integrate tactile feedback with their prior anatomical knowledge, teleoperated robotic systems must rely solely on 2D projections. This mode of operation, simultaneously lacking spatial context and tactile sensation, may give rise to projection-induced ambiguities at vascular bifurcations. To address this challenge, we propose a two-stage framework (SCAR-UNet-GAT) for real-time robotic path planning. In the first stage, SCAR-UNet, a spatial-coordinate-attention-regularized U-Net, is employed for accurate coronary vessel segmentation. The integration of multi-level attention mechanisms enhances the delineation of thin, tortuous vessels and improves robustness against imaging noise. From the resulting binary masks, vessel centerlines and bifurcation points are extracted, and geometric descriptors (e.g., branch diameter, intersection angles) are fused with local DSA patches to construct node features. In the second stage, a Graph Attention Network (GAT) reasons over the vessel graph to identify anatomically consistent and clinically feasible trajectories, effectively distinguishing true bifurcations from projection-induced false crossings. On a clinical DSA dataset, SCAR-UNet achieved a Dice coefficient of 93.1%. For path disambiguation, the proposed GAT-based method attained a success rate of 95.0% and a target-arrival success rate of 90.0%, substantially outperforming conventional shortest-path planning (60.0% and 55.0%) and heuristic-based planning (75.0% and 70.0%). Validation on a robotic platform further confirmed the practical feasibility and robustness of the proposed framework.
UniVTAC: A Unified Simulation Platform for Visuo-Tactile Manipulation Data Generation, Learning, and Benchmarking
Feb 10, 2026Robotic manipulation has seen rapid progress with vision-language-action (VLA) policies. However, visuo-tactile perception is critical for contact-rich manipulation, as tasks such as insertion are difficult to complete robustly using vision alone. At the same time, acquiring large-scale and reliable tactile data in the physical world remains costly and challenging, and the lack of a unified evaluation platform further limits policy learning and systematic analysis. To address these challenges, we propose UniVTAC, a simulation-based visuo-tactile data synthesis platform that supports three commonly used visuo-tactile sensors and enables scalable and controllable generation of informative contact interactions. Based on this platform, we introduce the UniVTAC Encoder, a visuo-tactile encoder trained on large-scale simulation-synthesized data with designed supervisory signals, providing tactile-centric visuo-tactile representations for downstream manipulation tasks. In addition, we present the UniVTAC Benchmark, which consists of eight representative visuo-tactile manipulation tasks for evaluating tactile-driven policies. Experimental results show that integrating the UniVTAC Encoder improves average success rates by 17.1% on the UniVTAC Benchmark, while real-world robotic experiments further demonstrate a 25% improvement in task success. Our webpage is available at https://univtac.github.io/.
Spatial4D-Bench: A Versatile 4D Spatial Intelligence Benchmark
Dec 31, 20254D spatial intelligence involves perceiving and processing how objects move or change over time. Humans naturally possess 4D spatial intelligence, supporting a broad spectrum of spatial reasoning abilities. To what extent can Multimodal Large Language Models (MLLMs) achieve human-level 4D spatial intelligence? In this work, we present Spatial4D-Bench, a versatile 4D spatial intelligence benchmark designed to comprehensively assess the 4D spatial reasoning abilities of MLLMs. Unlike existing spatial intelligence benchmarks that are often small-scale or limited in diversity, Spatial4D-Bench provides a large-scale, multi-task evaluation benchmark consisting of ~40,000 question-answer pairs covering 18 well-defined tasks. We systematically organize these tasks into six cognitive categories: object understanding, scene understanding, spatial relationship understanding, spatiotemporal relationship understanding, spatial reasoning and spatiotemporal reasoning. Spatial4D-Bench thereby offers a structured and comprehensive benchmark for evaluating the spatial cognition abilities of MLLMs, covering a broad spectrum of tasks that parallel the versatility of human spatial intelligence. We benchmark various state-of-the-art open-source and proprietary MLLMs on Spatial4D-Bench and reveal their substantial limitations in a wide variety of 4D spatial reasoning aspects, such as route plan, action recognition, and physical plausibility reasoning. We hope that the findings provided in this work offer valuable insights to the community and that our benchmark can facilitate the development of more capable MLLMs toward human-level 4D spatial intelligence. More resources can be found on our project page.
DreamUp3D: Object-Centric Generative Models for Single-View 3D Scene Understanding and Real-to-Sim Transfer
Feb 26, 2024
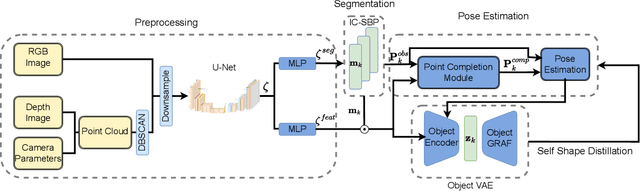

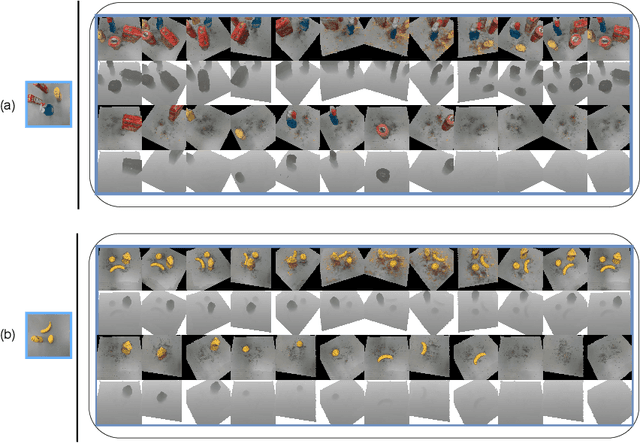
3D scene understanding for robotic applications exhibits a unique set of requirements including real-time inference, object-centric latent representation learning, accurate 6D pose estimation and 3D reconstruction of objects. Current methods for scene understanding typically rely on a combination of trained models paired with either an explicit or learnt volumetric representation, all of which have their own drawbacks and limitations. We introduce DreamUp3D, a novel Object-Centric Generative Model (OCGM) designed explicitly to perform inference on a 3D scene informed only by a single RGB-D image. DreamUp3D is a self-supervised model, trained end-to-end, and is capable of segmenting objects, providing 3D object reconstructions, generating object-centric latent representations and accurate per-object 6D pose estimates. We compare DreamUp3D to baselines including NeRFs, pre-trained CLIP-features, ObSurf, and ObPose, in a range of tasks including 3D scene reconstruction, object matching and object pose estimation. Our experiments show that our model outperforms all baselines by a significant margin in real-world scenarios displaying its applicability for 3D scene understanding tasks while meeting the strict demands exhibited in robotics applications.
ObPose: Leveraging Canonical Pose for Object-Centric Scene Inference in 3D
Jun 07, 2022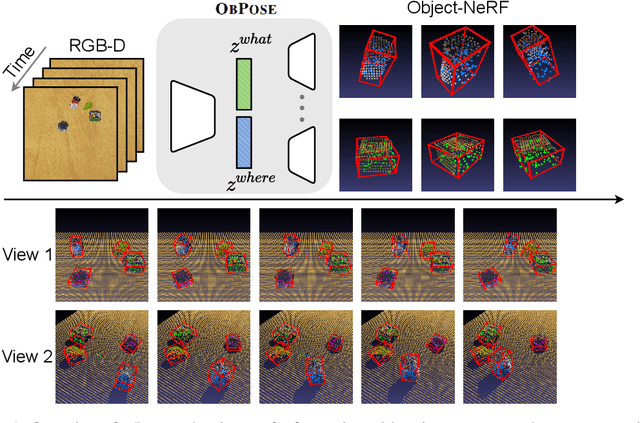



We present ObPose, an unsupervised object-centric generative model that learns to segment 3D objects from RGB-D video in an unsupervised manner. Inspired by prior art in 2D representation learning, ObPose considers a factorised latent space, separately encoding object-wise location (where) and appearance (what) information. In particular, ObPose leverages an object's canonical pose, defined via a minimum volume principle, as a novel inductive bias for learning the where component. To achieve this, we propose an efficient, voxelised approximation approach to recover the object shape directly from a neural radiance field (NeRF). As a consequence, ObPose models scenes as compositions of NeRFs representing individual objects. When evaluated on the YCB dataset for unsupervised scene segmentation, ObPose outperforms the current state-of-the-art in 3D scene inference (ObSuRF) by a significant margin in terms of segmentation quality for both video inputs as well as for multi-view static scenes. In addition, the design choices made in the ObPose encoder are validated with relevant ablations.
APEX: Unsupervised, Object-Centric Scene Segmentation and Tracking for Robot Manipulation
May 31, 2021
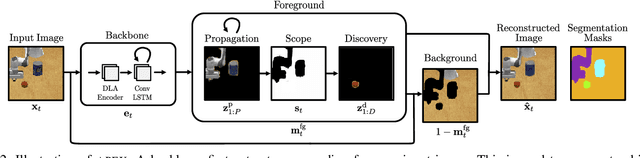
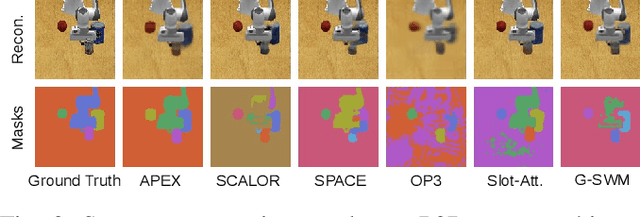

Recent advances in unsupervised learning for object detection, segmentation, and tracking hold significant promise for applications in robotics. A common approach is to frame these tasks as inference in probabilistic latent-variable models. In this paper, however, we show that the current state-of-the-art struggles with visually complex scenes such as typically encountered in robot manipulation tasks. We propose APEX, a new latent-variable model which is able to segment and track objects in more realistic scenes featuring objects that vary widely in size and texture, including the robot arm itself. This is achieved by a principled mask normalisation algorithm and a high-resolution scene encoder. To evaluate our approach, we present results on the real-world Sketchy dataset. This dataset, however, does not contain ground truth masks and object IDs for a quantitative evaluation. We thus introduce the Panda Pushing Dataset (P2D) which shows a Panda arm interacting with objects on a table in simulation and which includes ground-truth segmentation masks and object IDs for tracking. In both cases, APEX comprehensively outperforms the current state-of-the-art in unsupervised object segmentation and tracking. We demonstrate the efficacy of our segmentations for robot skill execution on an object arrangement task, where we also achieve the best or comparable performance among all the baselines.
Introspective Visuomotor Control: Exploiting Uncertainty in Deep Visuomotor Control for Failure Recovery
Mar 22, 2021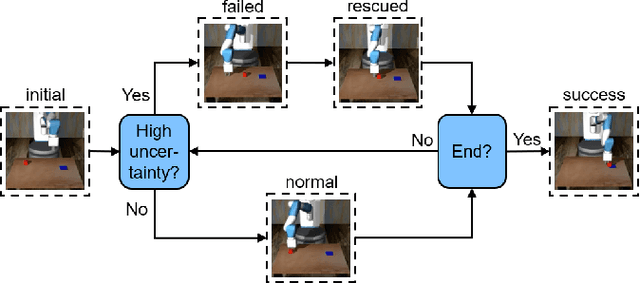
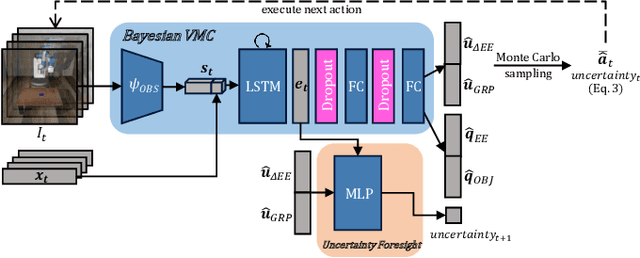

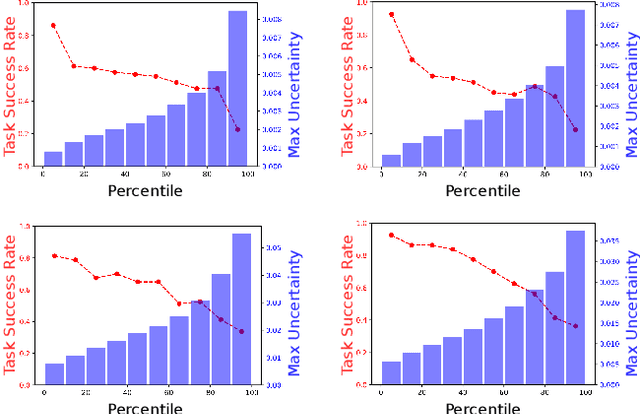
End-to-end visuomotor control is emerging as a compelling solution for robot manipulation tasks. However, imitation learning-based visuomotor control approaches tend to suffer from a common limitation, lacking the ability to recover from an out-of-distribution state caused by compounding errors. In this paper, instead of using tactile feedback or explicitly detecting the failure through vision, we investigate using the uncertainty of a policy neural network. We propose a novel uncertainty-based approach to detect and recover from failure cases. Our hypothesis is that policy uncertainties can implicitly indicate the potential failures in the visuomotor control task and that robot states with minimum uncertainty are more likely to lead to task success. To recover from high uncertainty cases, the robot monitors its uncertainty along a trajectory and explores possible actions in the state-action space to bring itself to a more certain state. Our experiments verify this hypothesis and show a significant improvement on task success rate: 12% in pushing, 15% in pick-and-reach and 22% in pick-and-place.
Imagine That! Leveraging Emergent Affordances for Tool Synthesis in Reaching Tasks
Nov 06, 2019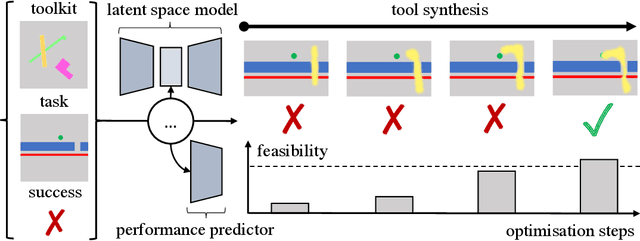
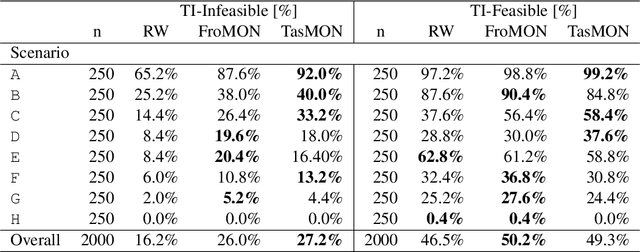
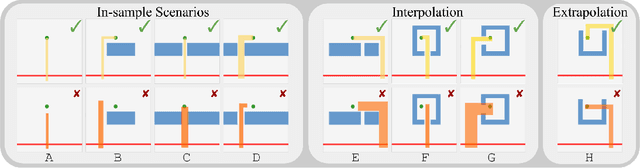
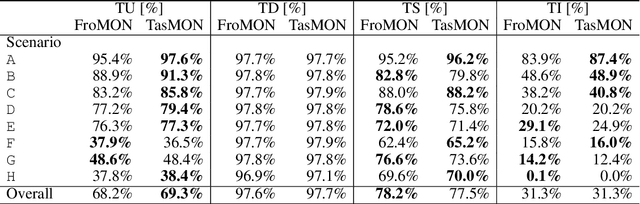
In this paper we investigate an artificial agent's ability to perform task-focused tool synthesis via imagination. Our motivation is to explore the richness of information captured by the latent space of an object-centric generative model -- and how to exploit it. In particular, our approach employs activation maximisation of a task-based performance predictor to optimise the latent variable of a structured latent-space model in order to generate tool geometries appropriate for the task at hand. We evaluate our model using a novel dataset of synthetic reaching tasks inspired by the cognitive sciences and behavioural ecology. In doing so we examine the model's ability to imagine tools for increasingly complex scenario types, beyond those seen during training. Our experiments demonstrate that the synthesis process modifies emergent, task-relevant object affordances in a targeted and deliberate way: the agents often specifically modify aspects of the tools which relate to meaningful (yet implicitly learned) concepts such as a tool's length, width and configuration. Our results therefore suggest that task relevant object affordances are implicitly encoded as directions in a structured latent space shaped by experience.