 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagine That! Leveraging Emergent Affordances for Tool Synthesis in Reaching Tasks
Nov 06, 2019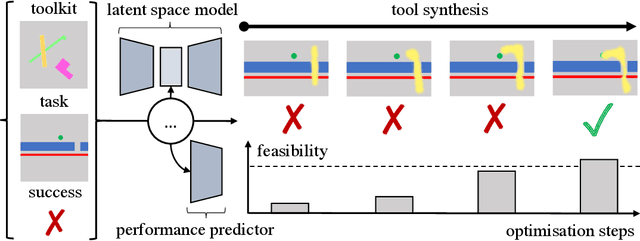
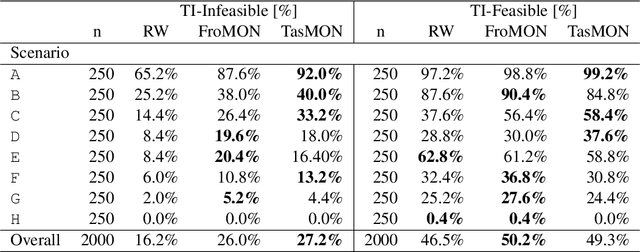
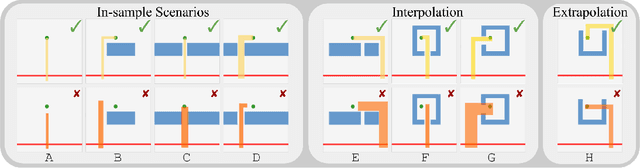
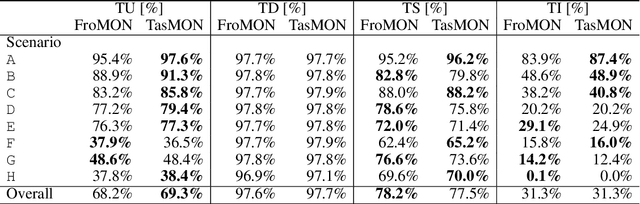
In this paper we investigate an artificial agent's ability to perform task-focused tool synthesis via imagination. Our motivation is to explore the richness of information captured by the latent space of an object-centric generative model -- and how to exploit it. In particular, our approach employs activation maximisation of a task-based performance predictor to optimise the latent variable of a structured latent-space model in order to generate tool geometries appropriate for the task at hand. We evaluate our model using a novel dataset of synthetic reaching tasks inspired by the cognitive sciences and behavioural ecology. In doing so we examine the model's ability to imagine tools for increasingly complex scenario types, beyond those seen during training. Our experiments demonstrate that the synthesis process modifies emergent, task-relevant object affordances in a targeted and deliberate way: the agents often specifically modify aspects of the tools which relate to meaningful (yet implicitly learned) concepts such as a tool's length, width and configuration. Our results therefore suggest that task relevant object affordances are implicitly encoded as directions in a structured latent space shaped by experience.
Learning from Demonstration in the Wild
Nov 08, 2018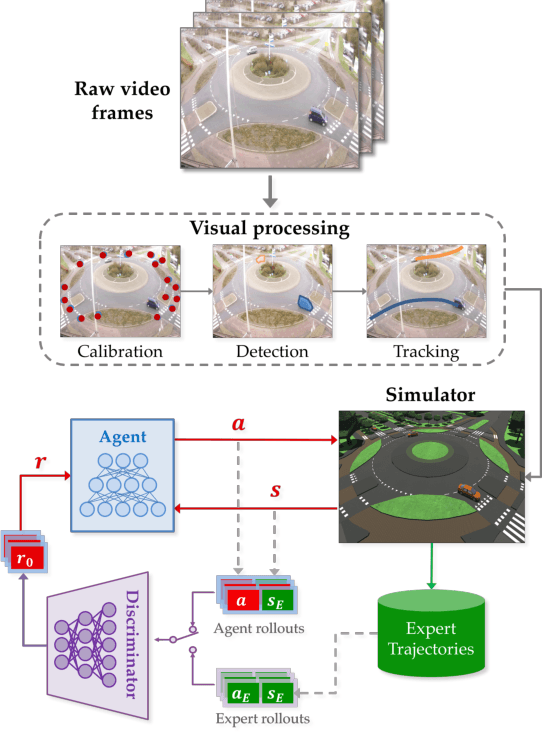
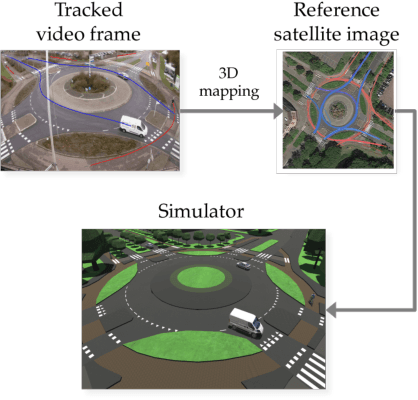
Learning from demonstration (LfD) is useful in settings where hand-coding behaviour or a reward function is impractical. It has succeeded in a wide range of problems but typically relies on artificially generated demonstrations or specially deployed sensors and has not generally been able to leverage the copious demonstrations available in the wild: those that capture behaviour that was occurring anyway using sensors that were already deployed for another purpose, e.g., traffic camera footage capturing demonstrations of natural behaviour of vehicles, cyclists, and pedestrians. We propose video to behaviour (ViBe), a new approach to learning models of road user behaviour that requires as input only unlabelled raw video data of a traffic scene collected from a single, monocular, uncalibrated camera with ordinary resolution. Our approach calibrates the camera, detects relevant objects, tracks them through time, and uses the resulting trajectories to perform LfD, yielding models of naturalistic behaviour. We apply ViBe to raw videos of a traffic intersection and show that it can learn purely from videos, without additional expert knowledge.
Wronging a Right: Generating Better Errors to Improve Grammatical Error Detection
Sep 26, 2018
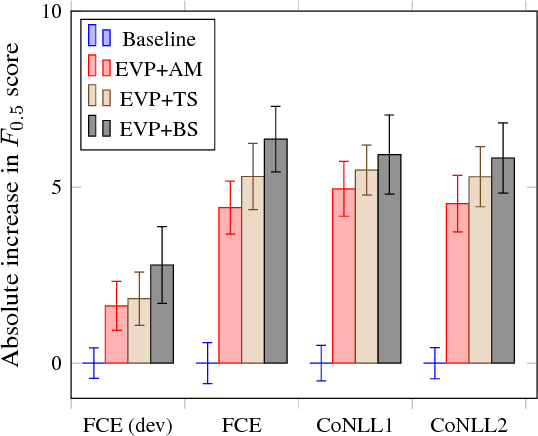
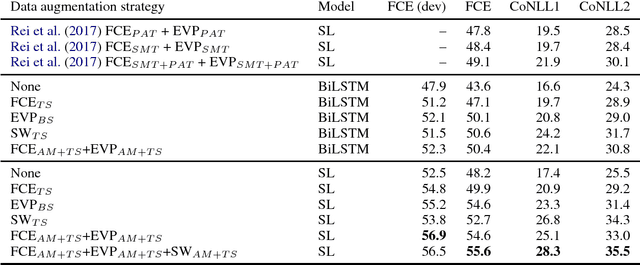
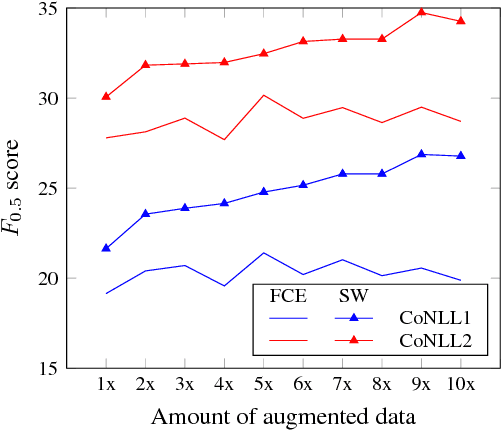
Grammatical error correction, like other machine learning tasks, greatly benefits from large quantities of high quality training data, which is typically expensive to produce. While writing a program to automatically generate realistic grammatical errors would be difficult, one could learn the distribution of naturallyoccurring errors and attempt to introduce them into other datasets. Initial work on inducing errors in this way using statistical machine translation has shown promise; we investigate cheaply constructing synthetic samples, given a small corpus of human-annotated data, using an off-the-rack attentive sequence-to-sequence model and a straight-forward post-processing procedure. Our approach yields error-filled artificial data that helps a vanilla bi-directional LSTM to outperform the previous state of the art at grammatical error detection, and a previously introduced model to gain further improvements of over 5% $F_{0.5}$ score. When attempting to determine if a given sentence is synthetic, a human annotator at best achieves 39.39 $F_1$ score, indicating that our model generates mostly human-like instances.