 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeemg2pose: A Large and Diverse Benchmark for Surface Electromyographic Hand Pose Estimation
Dec 02, 2024



Hands are the primary means through which humans interact with the world. Reliable and always-available hand pose inference could yield new and intuitive control schemes for human-computer interactions, particularly in virtual and augmented reality. Computer vision is effective but requires one or multiple cameras and can struggle with occlusions, limited field of view, and poor lighting. Wearable wrist-based surface electromyography (sEMG) presents a promising alternative as an always-available modality sensing muscle activities that drive hand motion. However, sEMG signals are strongly dependent on user anatomy and sensor placement, and existing sEMG models have required hundreds of users and device placements to effectively generalize. To facilitate progress on sEMG pose inference, we introduce the emg2pose benchmark, the largest publicly available dataset of high-quality hand pose labels and wrist sEMG recordings. emg2pose contains 2kHz, 16 channel sEMG and pose labels from a 26-camera motion capture rig for 193 users, 370 hours, and 29 stages with diverse gestures - a scale comparable to vision-based hand pose datasets. We provide competitive baselines and challenging tasks evaluating real-world generalization scenarios: held-out users, sensor placements, and stages. emg2pose provides the machine learning community a platform for exploring complex generalization problems, holding potential to significantly enhance the development of sEMG-based human-computer interactions.
MO2: Model-Based Offline Options
Sep 05, 2022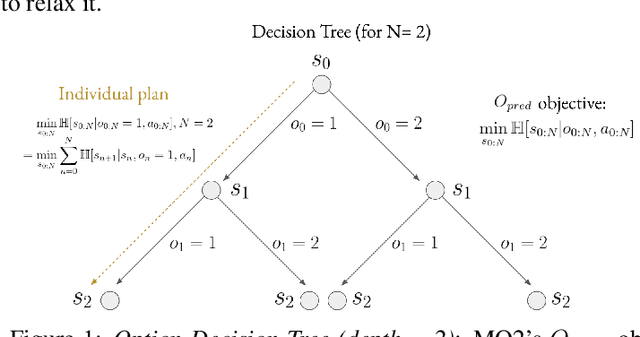

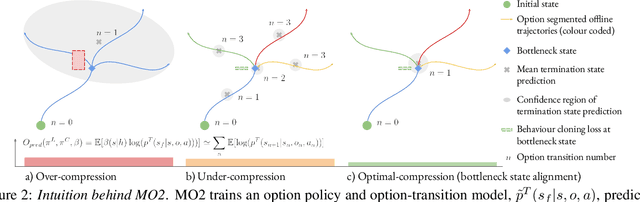
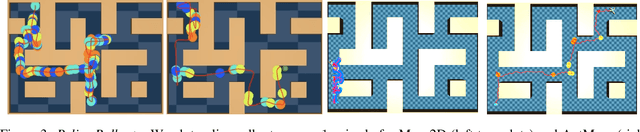
The ability to discover useful behaviours from past experience and transfer them to new tasks is considered a core component of natural embodied intelligence. Inspired by neuroscience, discovering behaviours that switch at bottleneck states have been long sought after for inducing plans of minimum description length across tasks. Prior approaches have either only supported online, on-policy, bottleneck state discovery, limiting sample-efficiency, or discrete state-action domains, restricting applicability. To address this, we introduce Model-Based Offline Options (MO2), an offline hindsight framework supporting sample-efficient bottleneck option discovery over continuous state-action spaces. Once bottleneck options are learnt offline over source domains, they are transferred online to improve exploration and value estimation on the transfer domain. Our experiments show that on complex long-horizon continuous control tasks with sparse, delayed rewards, MO2's properties are essential and lead to performance exceeding recent option learning methods. Additional ablations further demonstrate the impact on option predictability and credit assignment.
Priors, Hierarchy, and Information Asymmetry for Skill Transfer in Reinforcement Learning
Jan 20, 2022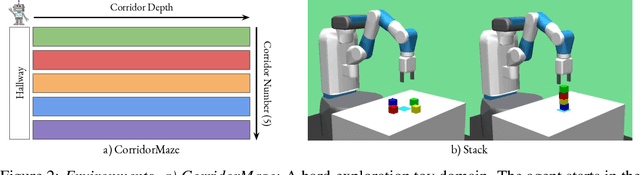
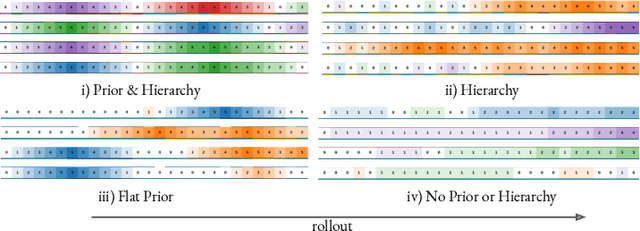
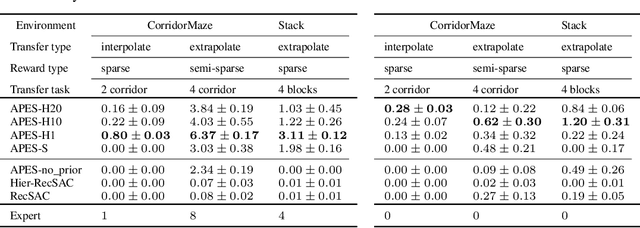
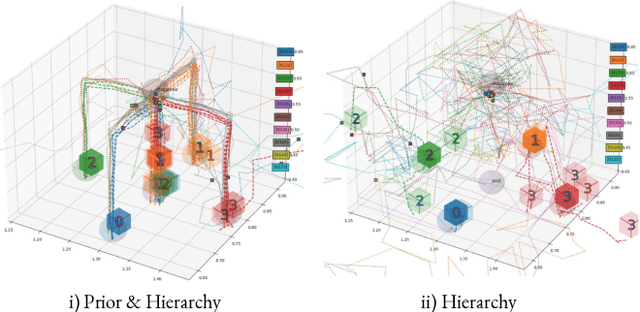
The ability to discover behaviours from past experience and transfer them to new tasks is a hallmark of intelligent agents acting sample-efficiently in the real world. Equipping embodied reinforcement learners with the same ability may be crucial for their successful deployment in robotics. While hierarchical and KL-regularized RL individually hold promise here, arguably a hybrid approach could combine their respective benefits. Key to these fields is the use of information asymmetry to bias which skills are learnt. While asymmetric choice has a large influence on transferability, prior works have explored a narrow range of asymmetries, primarily motivated by intuition. In this paper, we theoretically and empirically show the crucial trade-off, controlled by information asymmetry, between the expressivity and transferability of skills across sequential tasks. Given this insight, we provide a principled approach towards choosing asymmetry and apply our approach to a complex, robotic block stacking domain, unsolvable by baselines, demonstrating the effectiveness of hierarchical KL-regularized RL, coupled with correct asymmetric choice, for sample-efficient transfer learning.
Attention Privileged Reinforcement Learning For Domain Transfer
Nov 19, 2019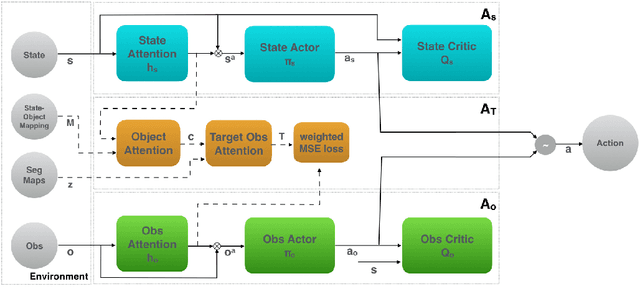
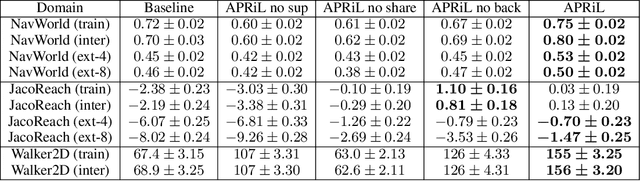
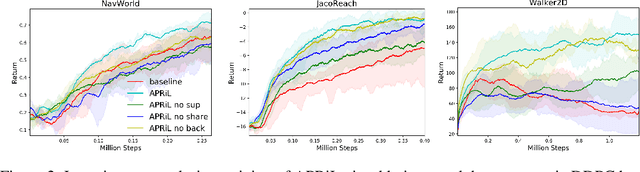
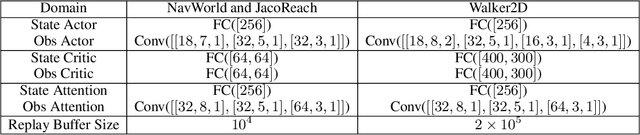
Applying reinforcement learning (RL) to physical systems presents notable challenges, given requirements regarding sample efficiency, safety, and physical constraints compared to simulated environments. To enable transfer of policies trained in simulation, randomising simulation parameters leads to more robust policies, but also significantly extends training time. In this paper, we exploit access to privileged information (such as environment states) often available in simulation, in order to improve and accelerate learning over randomised environments. We introduce Attention Privileged Reinforcement Learning (APRiL), which equips the agent with an attention mechanism and makes use of state information in simulation, learning to align attention between state- and image-based policies while additionally sharing generated data. During deployment we can apply the image-based policy to remove the requirement of access to additional information. We experimentally demonstrate accelerated and more robust learning on a number of diverse domains, leading to improved final performance for environments both within and outside the training distribution.
Imagine That! Leveraging Emergent Affordances for Tool Synthesis in Reaching Tasks
Nov 06, 2019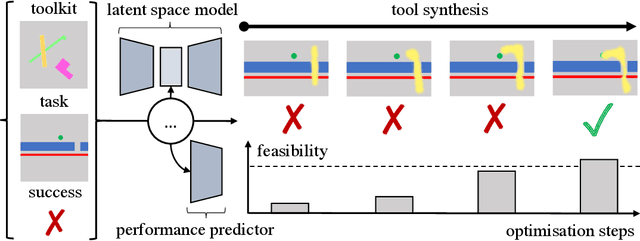
In this paper we investigate an artificial agent's ability to perform task-focused tool synthesis via imagination. Our motivation is to explore the richness of information captured by the latent space of an object-centric generative model -- and how to exploit it. In particular, our approach employs activation maximisation of a task-based performance predictor to optimise the latent variable of a structured latent-space model in order to generate tool geometries appropriate for the task at hand. We evaluate our model using a novel dataset of synthetic reaching tasks inspired by the cognitive sciences and behavioural ecology. In doing so we examine the model's ability to imagine tools for increasingly complex scenario types, beyond those seen during training. Our experiments demonstrate that the synthesis process modifies emergent, task-relevant object affordances in a targeted and deliberate way: the agents often specifically modify aspects of the tools which relate to meaningful (yet implicitly learned) concepts such as a tool's length, width and configuration. Our results therefore suggest that task relevant object affordances are implicitly encoded as directions in a structured latent space shaped by experience.
TACO: Learning Task Decomposition via Temporal Alignment for Control
Aug 10, 2018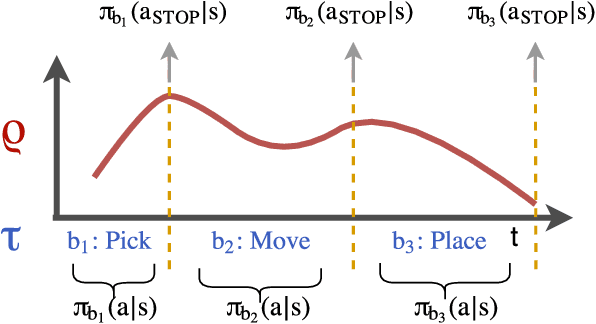
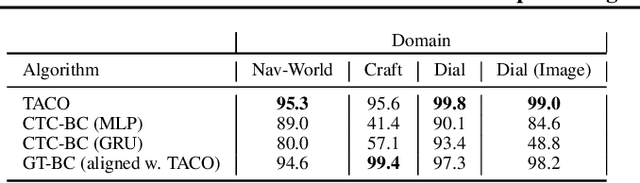
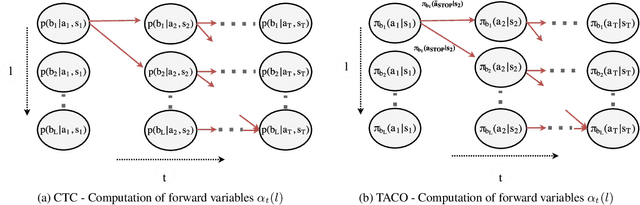

Many advanced Learning from Demonstration (LfD) methods consider the decomposition of complex, real-world tasks into simpler sub-tasks. By reusing the corresponding sub-policies within and between tasks, they provide training data for each policy from different high-level tasks and compose them to perform novel ones. Existing approaches to modular LfD focus either on learning a single high-level task or depend on domain knowledge and temporal segmentation. In contrast, we propose a weakly supervised, domain-agnostic approach based on task sketches, which include only the sequence of sub-tasks performed in each demonstration. Our approach simultaneously aligns the sketches with the observed demonstrations and learns the required sub-policies. This improves generalisation in comparison to separate optimisation procedures. We evaluate the approach on multiple domains, including a simulated 3D robot arm control task using purely image-based observations. The results show that our approach performs commensurately with fully supervised approaches, while requiring significantly less annotation effort.