 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePriors, Hierarchy, and Information Asymmetry for Skill Transfer in Reinforcement Learning
Paper and Code
Jan 20, 2022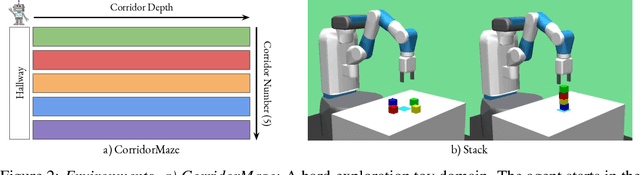
The ability to discover behaviours from past experience and transfer them to new tasks is a hallmark of intelligent agents acting sample-efficiently in the real world. Equipping embodied reinforcement learners with the same ability may be crucial for their successful deployment in robotics. While hierarchical and KL-regularized RL individually hold promise here, arguably a hybrid approach could combine their respective benefits. Key to these fields is the use of information asymmetry to bias which skills are learnt. While asymmetric choice has a large influence on transferability, prior works have explored a narrow range of asymmetries, primarily motivated by intuition. In this paper, we theoretically and empirically show the crucial trade-off, controlled by information asymmetry, between the expressivity and transferability of skills across sequential tasks. Given this insight, we provide a principled approach towards choosing asymmetry and apply our approach to a complex, robotic block stacking domain, unsolvable by baselines, demonstrating the effectiveness of hierarchical KL-regularized RL, coupled with correct asymmetric choice, for sample-efficient transfer learning.