 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Look at One: Category-Level Object Representations for Pose Estimation From a Single Example
May 22, 2023



In order to meaningfully interact with the world, robot manipulators must be able to interpret objects they encounter. A critical aspect of this interpretation is pose estimation: inferring quantities that describe the position and orientation of an object in 3D space. Most existing approaches to pose estimation make limiting assumptions, often working only for specific, known object instances, or at best generalising to an object category using large pose-labelled datasets. In this work, we present a method for achieving category-level pose estimation by inspection of just a single object from a desired category. We show that we can subsequently perform accurate pose estimation for unseen objects from an inspected category, and considerably outperform prior work by exploiting multi-view correspondences. We demonstrate that our method runs in real-time, enabling a robot manipulator equipped with an RGBD sensor to perform online 6D pose estimation for novel objects. Finally, we showcase our method in a continual learning setting, with a robot able to determine whether objects belong to known categories, and if not, use active perception to produce a one-shot category representation for subsequent pose estimation.
Zero-Shot Category-Level Object Pose Estimation
Apr 07, 2022
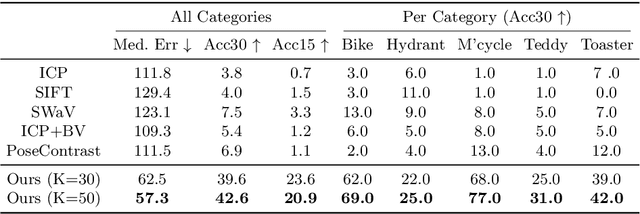
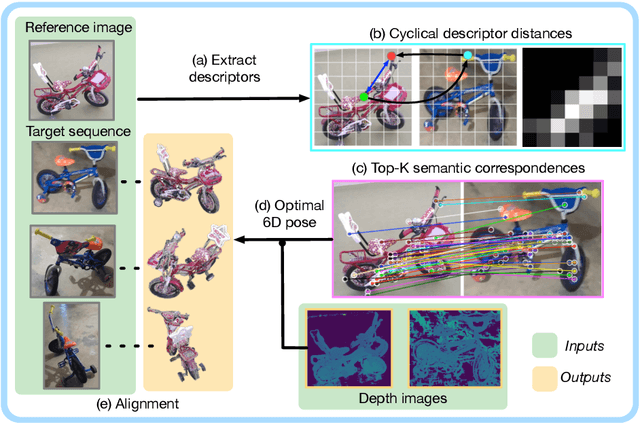
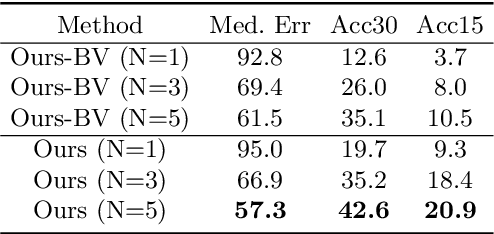
Object pose estimation is an important component of most vision pipelines for embodied agents, as well as in 3D vision more generally. In this paper we tackle the problem of estimating the pose of novel object categories in a zero-shot manner. This extends much of the existing literature by removing the need for pose-labelled datasets or category-specific CAD models for training or inference. Specifically, we make the following contributions. First, we formalise the zero-shot, category-level pose estimation problem and frame it in a way that is most applicable to real-world embodied agents. Secondly, we propose a novel method based on semantic correspondences from a self-supervised vision transformer to solve the pose estimation problem. We further re-purpose the recent CO3D dataset to present a controlled and realistic test setting. Finally, we demonstrate that all baselines for our proposed task perform poorly, and show that our method provides a six-fold improvement in average rotation accuracy at 30 degrees. Our code is available at https://github.com/applied-ai-lab/zero-shot-pose.
Priors, Hierarchy, and Information Asymmetry for Skill Transfer in Reinforcement Learning
Jan 20, 2022
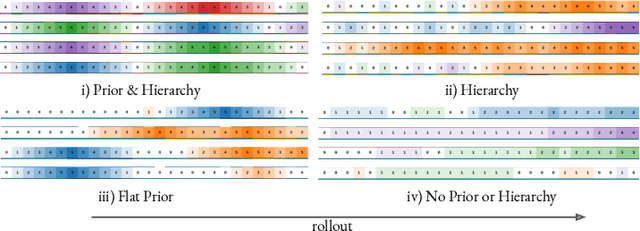
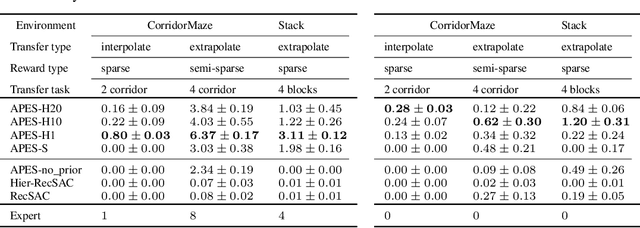
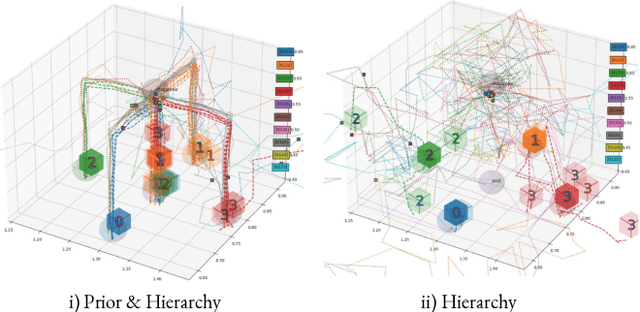
The ability to discover behaviours from past experience and transfer them to new tasks is a hallmark of intelligent agents acting sample-efficiently in the real world. Equipping embodied reinforcement learners with the same ability may be crucial for their successful deployment in robotics. While hierarchical and KL-regularized RL individually hold promise here, arguably a hybrid approach could combine their respective benefits. Key to these fields is the use of information asymmetry to bias which skills are learnt. While asymmetric choice has a large influence on transferability, prior works have explored a narrow range of asymmetries, primarily motivated by intuition. In this paper, we theoretically and empirically show the crucial trade-off, controlled by information asymmetry, between the expressivity and transferability of skills across sequential tasks. Given this insight, we provide a principled approach towards choosing asymmetry and apply our approach to a complex, robotic block stacking domain, unsolvable by baselines, demonstrating the effectiveness of hierarchical KL-regularized RL, coupled with correct asymmetric choice, for sample-efficient transfer learning.
Semantically Grounded Object Matching for Robust Robotic Scene Rearrangement
Nov 15, 2021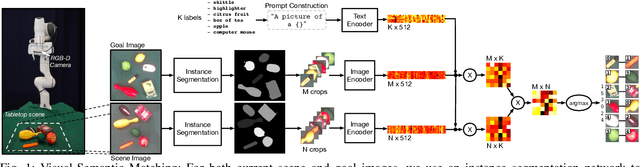



Object rearrangement has recently emerged as a key competency in robot manipulation, with practical solutions generally involving object detection, recognition, grasping and high-level planning. Goal-images describing a desired scene configuration are a promising and increasingly used mode of instruction. A key outstanding challenge is the accurate inference of matches between objects in front of a robot, and those seen in a provided goal image, where recent works have struggled in the absence of object-specific training data. In this work, we explore the deterioration of existing methods' ability to infer matches between objects as the visual shift between observed and goal scenes increases. We find that a fundamental limitation of the current setting is that source and target images must contain the same $\textit{instance}$ of every object, which restricts practical deployment. We present a novel approach to object matching that uses a large pre-trained vision-language model to match objects in a cross-instance setting by leveraging semantics together with visual features as a more robust, and much more general, measure of similarity. We demonstrate that this provides considerably improved matching performance in cross-instance settings, and can be used to guide multi-object rearrangement with a robot manipulator from an image that shares no object $\textit{instances}$ with the robot's scene.