 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Category-Level Object Pose Estimation
Paper and Code

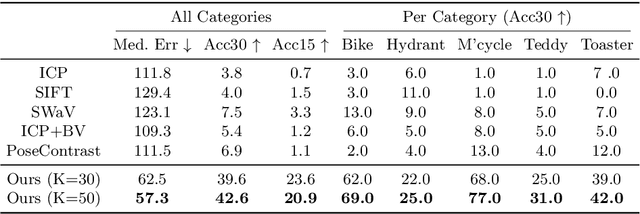
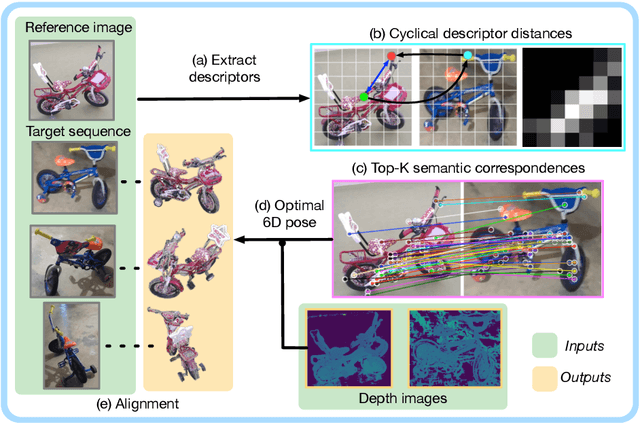
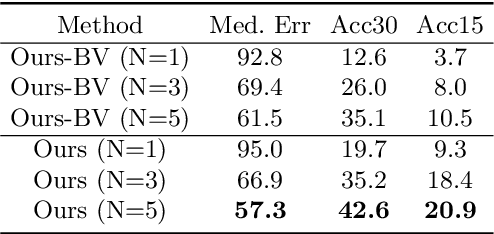
Object pose estimation is an important component of most vision pipelines for embodied agents, as well as in 3D vision more generally. In this paper we tackle the problem of estimating the pose of novel object categories in a zero-shot manner. This extends much of the existing literature by removing the need for pose-labelled datasets or category-specific CAD models for training or inference. Specifically, we make the following contributions. First, we formalise the zero-shot, category-level pose estimation problem and frame it in a way that is most applicable to real-world embodied agents. Secondly, we propose a novel method based on semantic correspondences from a self-supervised vision transformer to solve the pose estimation problem. We further re-purpose the recent CO3D dataset to present a controlled and realistic test setting. Finally, we demonstrate that all baselines for our proposed task perform poorly, and show that our method provides a six-fold improvement in average rotation accuracy at 30 degrees. Our code is available at https://github.com/applied-ai-lab/zero-shot-pose.