 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically Grounded Object Matching for Robust Robotic Scene Rearrangement
Paper and Code
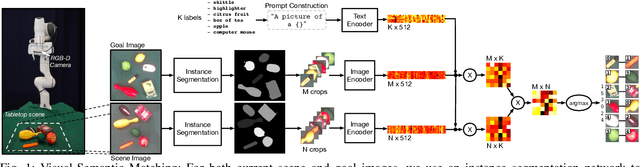



Object rearrangement has recently emerged as a key competency in robot manipulation, with practical solutions generally involving object detection, recognition, grasping and high-level planning. Goal-images describing a desired scene configuration are a promising and increasingly used mode of instruction. A key outstanding challenge is the accurate inference of matches between objects in front of a robot, and those seen in a provided goal image, where recent works have struggled in the absence of object-specific training data. In this work, we explore the deterioration of existing methods' ability to infer matches between objects as the visual shift between observed and goal scenes increases. We find that a fundamental limitation of the current setting is that source and target images must contain the same $\textit{instance}$ of every object, which restricts practical deployment. We present a novel approach to object matching that uses a large pre-trained vision-language model to match objects in a cross-instance setting by leveraging semantics together with visual features as a more robust, and much more general, measure of similarity. We demonstrate that this provides considerably improved matching performance in cross-instance settings, and can be used to guide multi-object rearrangement with a robot manipulator from an image that shares no object $\textit{instances}$ with the robot's scene.