 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Demonstration in the Wild
Paper and Code
Nov 08, 2018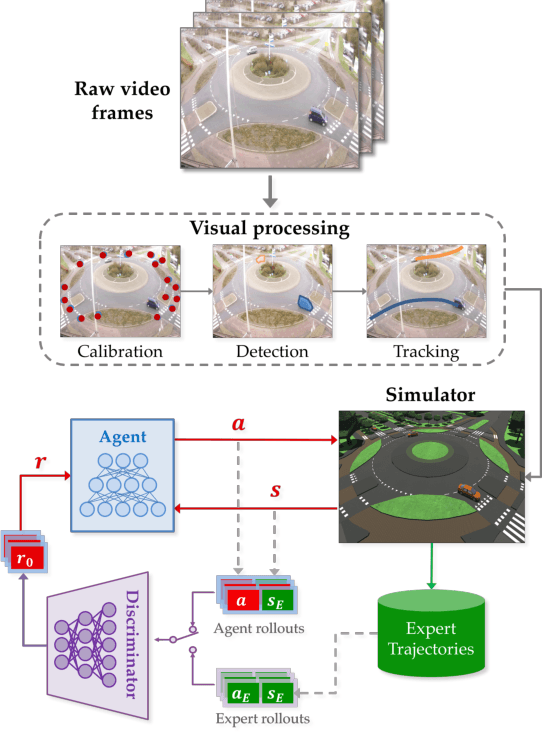
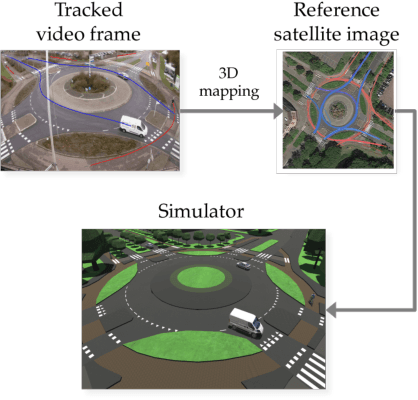
Learning from demonstration (LfD) is useful in settings where hand-coding behaviour or a reward function is impractical. It has succeeded in a wide range of problems but typically relies on artificially generated demonstrations or specially deployed sensors and has not generally been able to leverage the copious demonstrations available in the wild: those that capture behaviour that was occurring anyway using sensors that were already deployed for another purpose, e.g., traffic camera footage capturing demonstrations of natural behaviour of vehicles, cyclists, and pedestrians. We propose video to behaviour (ViBe), a new approach to learning models of road user behaviour that requires as input only unlabelled raw video data of a traffic scene collected from a single, monocular, uncalibrated camera with ordinary resolution. Our approach calibrates the camera, detects relevant objects, tracks them through time, and uses the resulting trajectories to perform LfD, yielding models of naturalistic behaviour. We apply ViBe to raw videos of a traffic intersection and show that it can learn purely from videos, without additional expert knowledge.