 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObPose: Leveraging Canonical Pose for Object-Centric Scene Inference in 3D
Paper and Code
Jun 07, 2022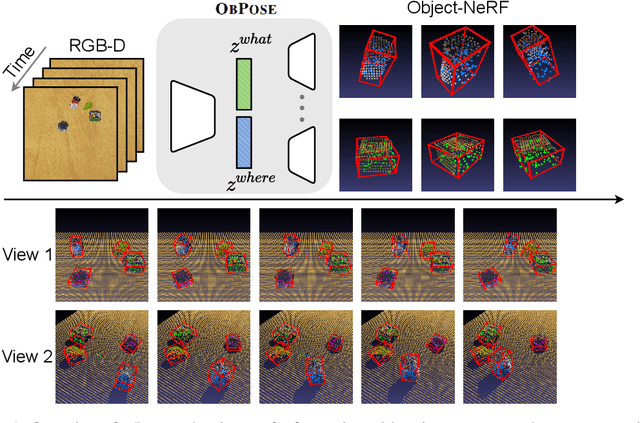



We present ObPose, an unsupervised object-centric generative model that learns to segment 3D objects from RGB-D video in an unsupervised manner. Inspired by prior art in 2D representation learning, ObPose considers a factorised latent space, separately encoding object-wise location (where) and appearance (what) information. In particular, ObPose leverages an object's canonical pose, defined via a minimum volume principle, as a novel inductive bias for learning the where component. To achieve this, we propose an efficient, voxelised approximation approach to recover the object shape directly from a neural radiance field (NeRF). As a consequence, ObPose models scenes as compositions of NeRFs representing individual objects. When evaluated on the YCB dataset for unsupervised scene segmentation, ObPose outperforms the current state-of-the-art in 3D scene inference (ObSuRF) by a significant margin in terms of segmentation quality for both video inputs as well as for multi-view static scenes. In addition, the design choices made in the ObPose encoder are validated with relevant ablations.