 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAE-Loco: Versatile Quadruped Locomotion by Learning a Disentangled Gait Representation
May 02, 2022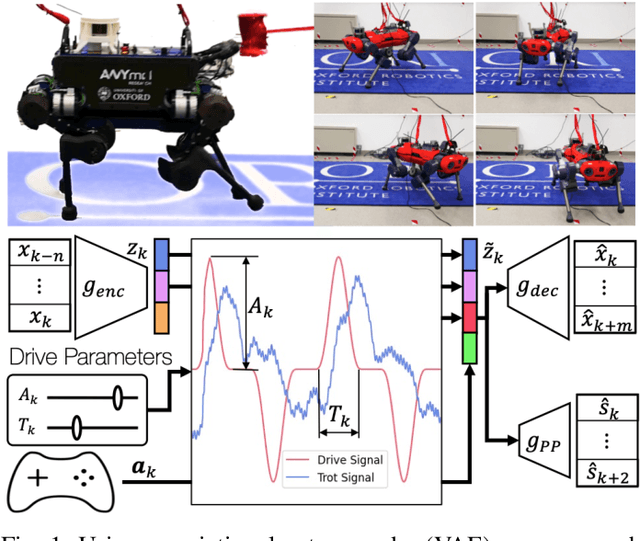
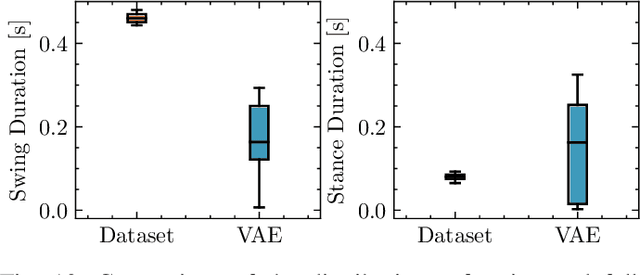
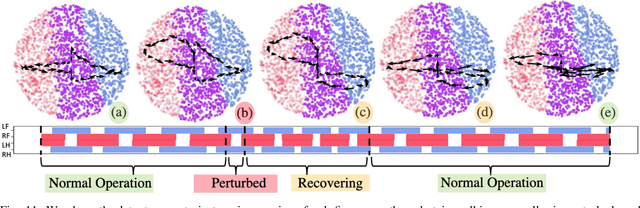
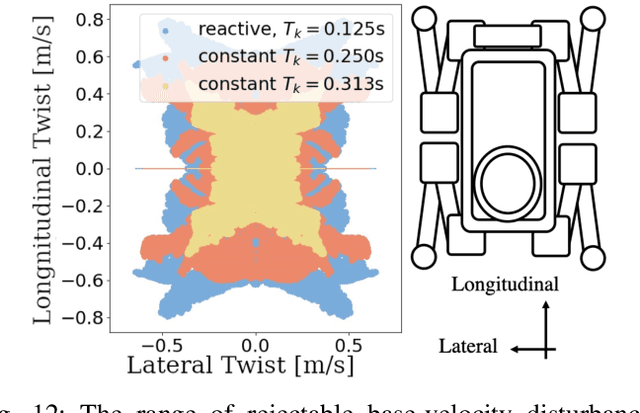
Quadruped locomotion is rapidly maturing to a degree where robots now routinely traverse a variety of unstructured terrains. However, while gaits can be varied typically by selecting from a range of pre-computed styles, current planners are unable to vary key gait parameters continuously while the robot is in motion. The synthesis, on-the-fly, of gaits with unexpected operational characteristics or even the blending of dynamic manoeuvres lies beyond the capabilities of the current state-of-the-art. In this work we address this limitation by learning a latent space capturing the key stance phases constituting a particular gait. This is achieved via a generative model trained on a single trot style, which encourages disentanglement such that application of a drive signal to a single dimension of the latent state induces holistic plans synthesising a continuous variety of trot styles. We demonstrate that specific properties of the drive signal map directly to gait parameters such as cadence, footstep height and full stance duration. Due to the nature of our approach these synthesised gaits are continuously variable online during robot operation and robustly capture a richness of movement significantly exceeding the relatively narrow behaviour seen during training. In addition, the use of a generative model facilitates the detection and mitigation of disturbances to provide a versatile and robust planning framework. We evaluate our approach on two versions of the real ANYmal quadruped robots and demonstrate that our method achieves a continuous blend of dynamic trot styles whilst being robust and reactive to external perturbations.
Next Steps: Learning a Disentangled Gait Representation for Versatile Quadruped Locomotion
Dec 09, 2021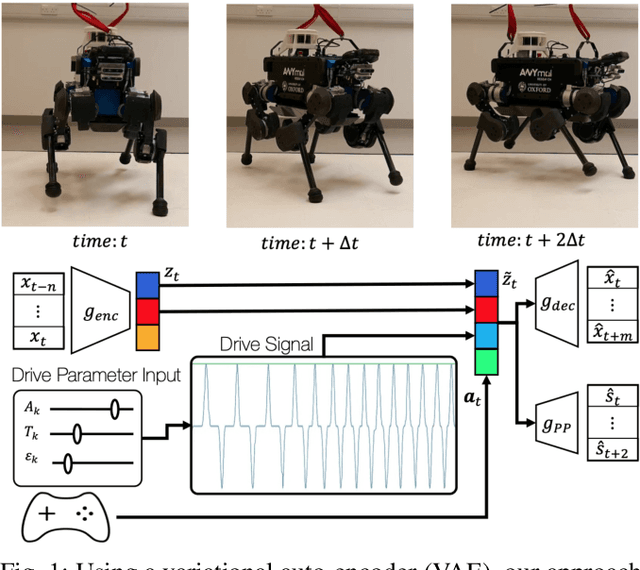
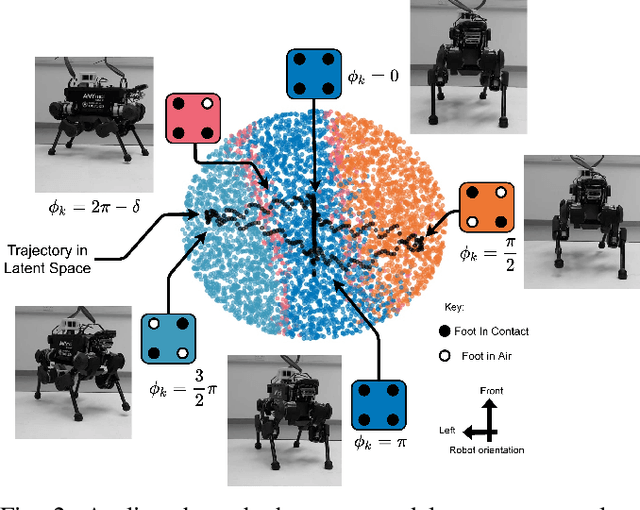
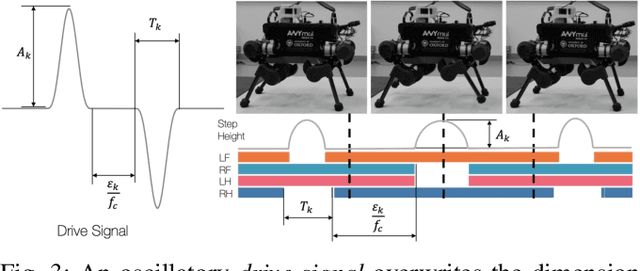

Quadruped locomotion is rapidly maturing to a degree where robots now routinely traverse a variety of unstructured terrains. However, while gaits can be varied typically by selecting from a range of pre-computed styles, current planners are unable to vary key gait parameters continuously while the robot is in motion. The synthesis, on-the-fly, of gaits with unexpected operational characteristics or even the blending of dynamic manoeuvres lies beyond the capabilities of the current state-of-the-art. In this work we address this limitation by learning a latent space capturing the key stance phases constituting a particular gait. This is achieved via a generative model trained on a single trot style, which encourages disentanglement such that application of a drive signal to a single dimension of the latent state induces holistic plans synthesising a continuous variety of trot styles. We demonstrate that specific properties of the drive signal map directly to gait parameters such as cadence, foot step height and full stance duration. Due to the nature of our approach these synthesised gaits are continuously variable online during robot operation and robustly capture a richness of movement significantly exceeding the relatively narrow behaviour seen during training. In addition, the use of a generative model facilitates the detection and mitigation of disturbances to provide a versatile and robust planning framework. We evaluate our approach on a real ANYmal quadruped robot and demonstrate that our method achieves a continuous blend of dynamic trot styles whilst being robust and reactive to external perturbations.
Receding-Horizon Perceptive Trajectory Optimization for Dynamic Legged Locomotion with Learned Initialization
Apr 19, 2021

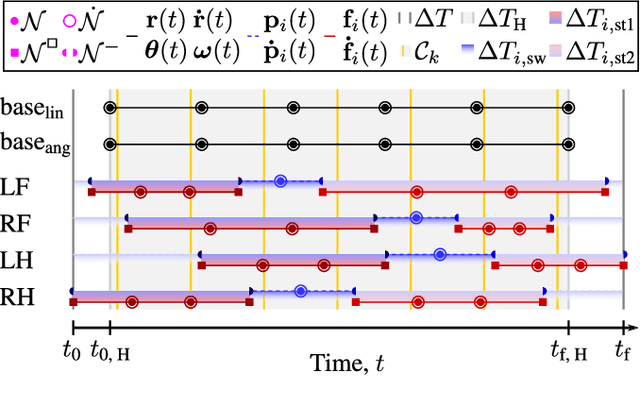
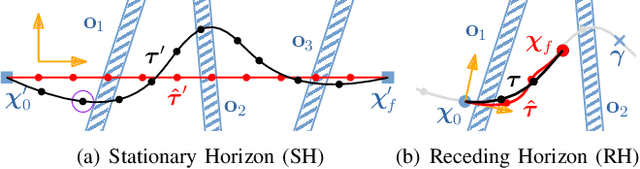
To dynamically traverse challenging terrain, legged robots need to continually perceive and reason about upcoming features, adjust the locations and timings of future footfalls and leverage momentum strategically. We present a pipeline that enables flexibly-parametrized trajectories for perceptive and dynamic quadruped locomotion to be optimized in an online, receding-horizon manner. The initial guess passed to the optimizer affects the computation needed to achieve convergence and the quality of the solution. We consider two methods for generating good guesses. The first is a heuristic initializer which provides a simple guess and requires significant optimization but is nonetheless suitable for adaptation to upcoming terrain. We demonstrate experiments using the ANYmal C quadruped, with fully onboard sensing and computation, to cross obstacles at moderate speeds using this technique. Our second approach uses latent-mode trajectory regression (LMTR) to imitate expert data - while avoiding invalid interpolations between distinct behaviors - such that minimal optimization is needed. This enables high-speed motions that make more expansive use of the robot's capabilities. We demonstrate it on flat ground with the real robot and provide numerical trials that progress toward deployment on terrain. These results illustrate a paradigm for advancing beyond short-horizon dynamic reactions, toward the type of intuitive and adaptive locomotion planning exhibited by animals and humans.
RLOC: Terrain-Aware Legged Locomotion using Reinforcement Learning and Optimal Control
Dec 05, 2020



We present a unified model-based and data-driven approach for quadrupedal planning and control to achieve dynamic locomotion over uneven terrain. We utilize on-board proprioceptive and exteroceptive feedback to map sensory information and desired base velocity commands into footstep plans using a reinforcement learning (RL) policy trained in simulation over a wide range of procedurally generated terrains. When ran online, the system tracks the generated footstep plans using a model-based controller. We evaluate the robustness of our method over a wide variety of complex terrains. It exhibits behaviors which prioritize stability over aggressive locomotion. Additionally, we introduce two ancillary RL policies for corrective whole-body motion tracking and recovery control. These policies account for changes in physical parameters and external perturbations. We train and evaluate our framework on a complex quadrupedal system, ANYmal version B, and demonstrate transferability to a larger and heavier robot, ANYmal C, without requiring retraining.
Reliable Trajectories for Dynamic Quadrupeds using Analytical Costs and Learned Initializations
Feb 17, 2020
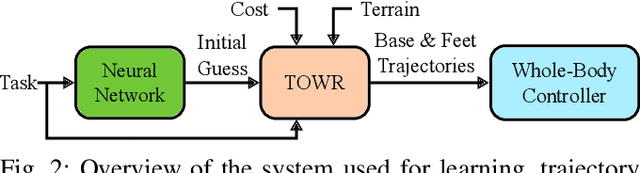
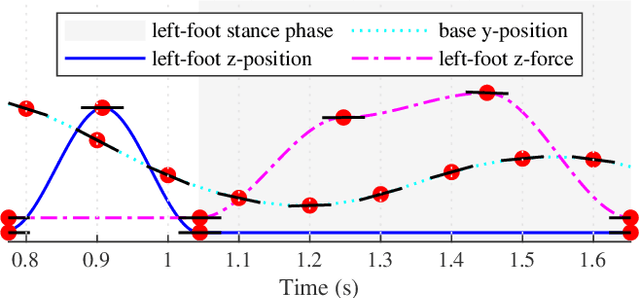
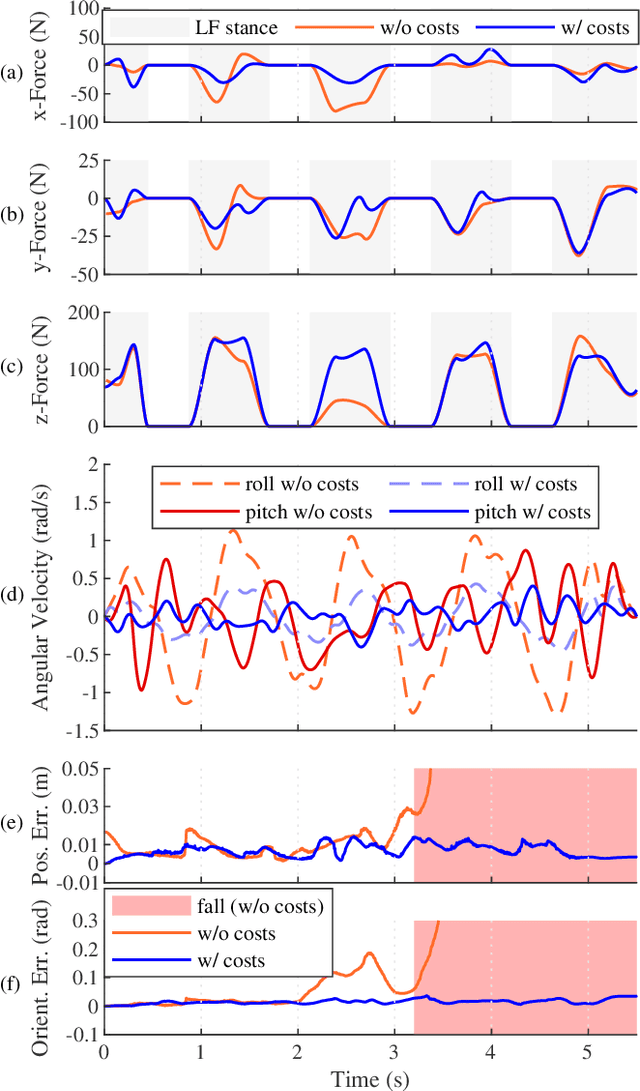
Dynamic traversal of uneven terrain is a major objective in the field of legged robotics. The most recent model predictive control approaches for these systems can generate robust dynamic motion of short duration; however, planning over a longer time horizon may be necessary when navigating complex terrain. A recently-developed framework, Trajectory Optimization for Walking Robots (TOWR), computes such plans but does not guarantee their reliability on real platforms, under uncertainty and perturbations. We extend TOWR with analytical costs to generate trajectories that a state-of-the-art whole-body tracking controller can successfully execute. To reduce online computation time, we implement a learning-based scheme for initialization of the nonlinear program based on offline experience. The execution of trajectories as long as 16 footsteps and 5.5 s over different terrains by a real quadruped demonstrates the effectiveness of the approach on hardware. This work builds toward an online system which can efficiently and robustly replan dynamic trajectories.
Contact Planning for the ANYmal Quadruped Robot using an Acyclic Reachability-Based Planner
Apr 17, 2019
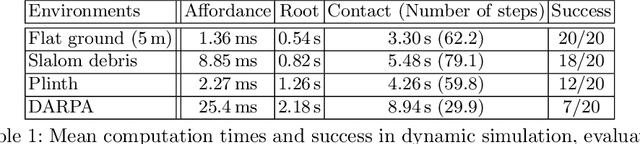

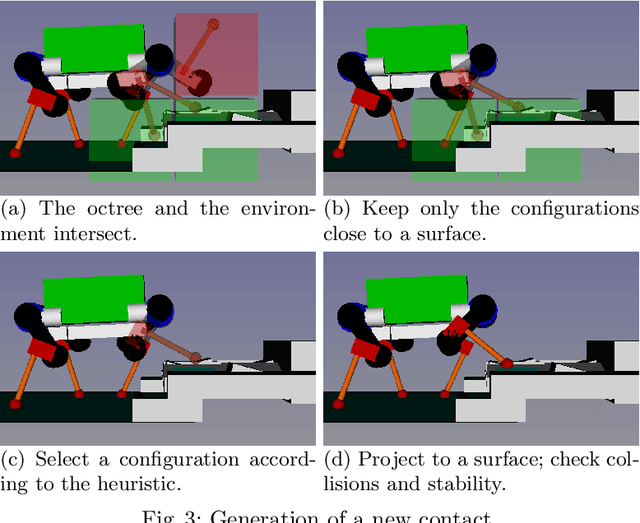
Despite the great progress in quadrupedal robotics during the last decade, selecting good contacts (footholds) in highly uneven and cluttered environments still remains an open challenge. This paper builds upon a state-of-the-art approach, already successfully used for humanoid robots, and applies it to our robotic platform; the quadruped robot ANY-mal. The proposed algorithm decouples the problem into two subprob-lems: first a guide trajectory for the robot is generated, then contacts are created along this trajectory. Both subproblems rely on approximations and heuristics that need to be tuned. The main contribution of this work is to explain how this algorithm has been retuned to work with ANY-mal and to show the relevance of the approach with a variety of tests in realistic dynamic simulations.
Trajectory Generation for Quadrotor Based Systems using Numerical Optimal Control
Feb 08, 2016



The recent works on quadrotor have focused on more and more challenging tasks on increasingly complex systems. Systems are often augmented with slung loads, inverted pendulums or arms, and accomplish complex tasks such as going through a window, grasping, throwing or catching. Usually, controllers are designed to accomplish a specific task on a specific system using analytic solutions, so each application needs long preparations. On the other hand, the direct multiple shooting approach is able to solve complex problems without any analytic development, by using on-the-shelf optimization solver. In this paper, we show that this approach is able to solve a wide range of problems relevant to quadrotor systems, from on-line trajectory generation for quadrotors, to going through a window for a quadrotor-and-pendulum system, through manipulation tasks for a aerial manipulator.