 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReceding-Horizon Perceptive Trajectory Optimization for Dynamic Legged Locomotion with Learned Initialization
Apr 19, 2021

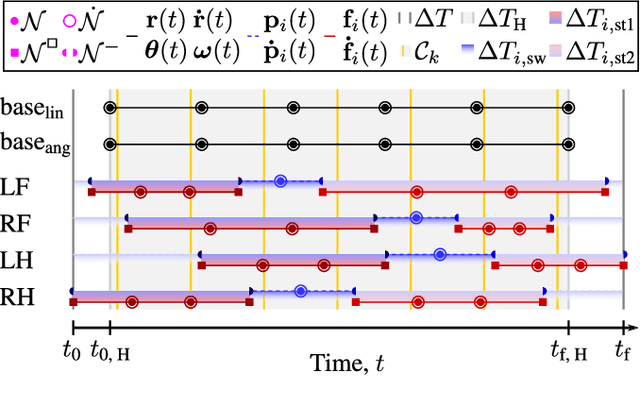
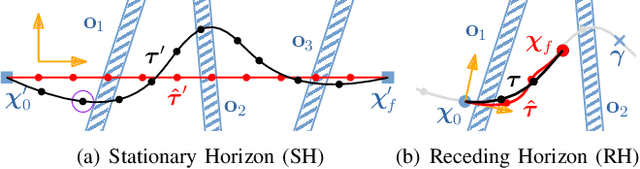
To dynamically traverse challenging terrain, legged robots need to continually perceive and reason about upcoming features, adjust the locations and timings of future footfalls and leverage momentum strategically. We present a pipeline that enables flexibly-parametrized trajectories for perceptive and dynamic quadruped locomotion to be optimized in an online, receding-horizon manner. The initial guess passed to the optimizer affects the computation needed to achieve convergence and the quality of the solution. We consider two methods for generating good guesses. The first is a heuristic initializer which provides a simple guess and requires significant optimization but is nonetheless suitable for adaptation to upcoming terrain. We demonstrate experiments using the ANYmal C quadruped, with fully onboard sensing and computation, to cross obstacles at moderate speeds using this technique. Our second approach uses latent-mode trajectory regression (LMTR) to imitate expert data - while avoiding invalid interpolations between distinct behaviors - such that minimal optimization is needed. This enables high-speed motions that make more expansive use of the robot's capabilities. We demonstrate it on flat ground with the real robot and provide numerical trials that progress toward deployment on terrain. These results illustrate a paradigm for advancing beyond short-horizon dynamic reactions, toward the type of intuitive and adaptive locomotion planning exhibited by animals and humans.
Reliable Trajectories for Dynamic Quadrupeds using Analytical Costs and Learned Initializations
Feb 17, 2020
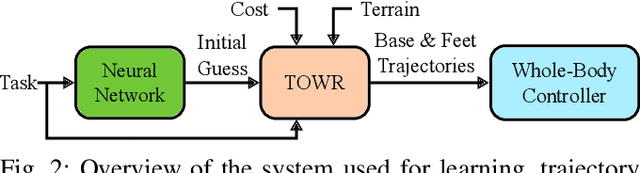
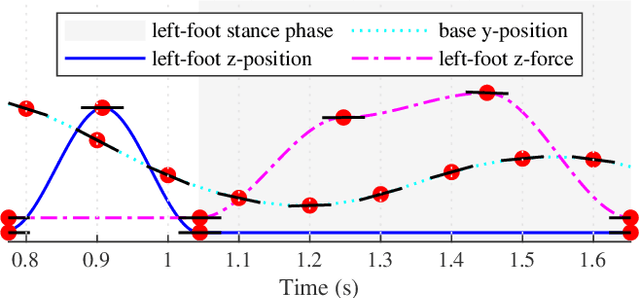
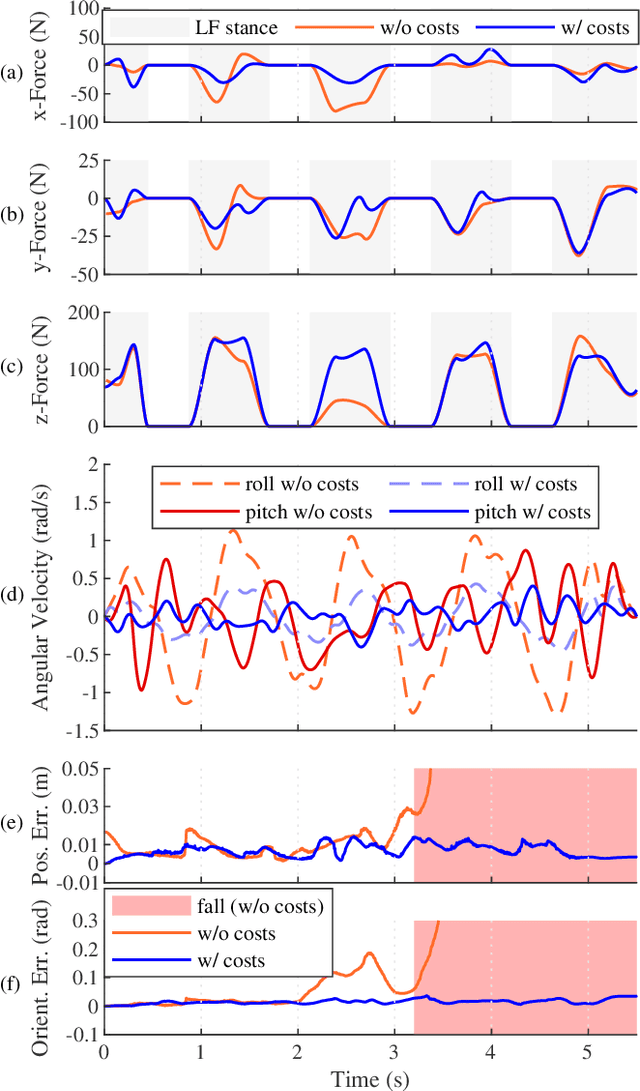
Dynamic traversal of uneven terrain is a major objective in the field of legged robotics. The most recent model predictive control approaches for these systems can generate robust dynamic motion of short duration; however, planning over a longer time horizon may be necessary when navigating complex terrain. A recently-developed framework, Trajectory Optimization for Walking Robots (TOWR), computes such plans but does not guarantee their reliability on real platforms, under uncertainty and perturbations. We extend TOWR with analytical costs to generate trajectories that a state-of-the-art whole-body tracking controller can successfully execute. To reduce online computation time, we implement a learning-based scheme for initialization of the nonlinear program based on offline experience. The execution of trajectories as long as 16 footsteps and 5.5 s over different terrains by a real quadruped demonstrates the effectiveness of the approach on hardware. This work builds toward an online system which can efficiently and robustly replan dynamic trajectories.