 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan foundation models actively gather information in interactive environments to test hypotheses?
Dec 09, 2024



While problem solving is a standard evaluation task for foundation models, a crucial component of problem solving -- actively and strategically gathering information to test hypotheses -- has not been closely investigated. To assess the information gathering abilities of foundation models in interactive environments, we introduce a framework in which a model must determine the factors influencing a hidden reward function by iteratively reasoning about its previously gathered information and proposing its next exploratory action to maximize information gain at each step. We implement this framework in both a text-based environment, which offers a tightly controlled setting and enables high-throughput parameter sweeps, and in an embodied 3D environment, which requires addressing complexities of multi-modal interaction more relevant to real-world applications. We further investigate whether approaches such as self-correction and increased inference time improve information gathering efficiency. In a relatively simple task that requires identifying a single rewarding feature, we find that LLM's information gathering capability is close to optimal. However, when the model must identify a conjunction of rewarding features, performance is suboptimal. The hit in performance is due partly to the model translating task description to a policy and partly to the model's effectiveness in using its in-context memory. Performance is comparable in both text and 3D embodied environments, although imperfect visual object recognition reduces its accuracy in drawing conclusions from gathered information in the 3D embodied case. For single-feature-based rewards, we find that smaller models curiously perform better; for conjunction-based rewards, incorporating self correction into the model improves performance.
Grandmaster-Level Chess Without Search
Feb 07, 2024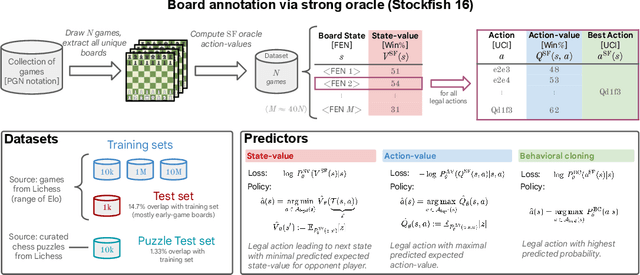
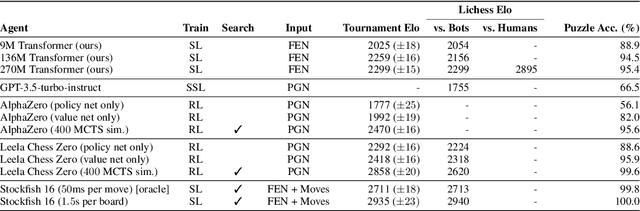
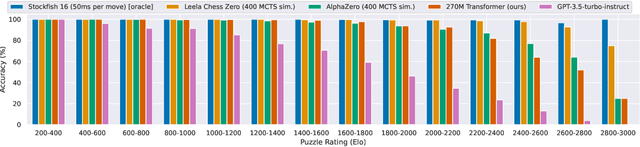
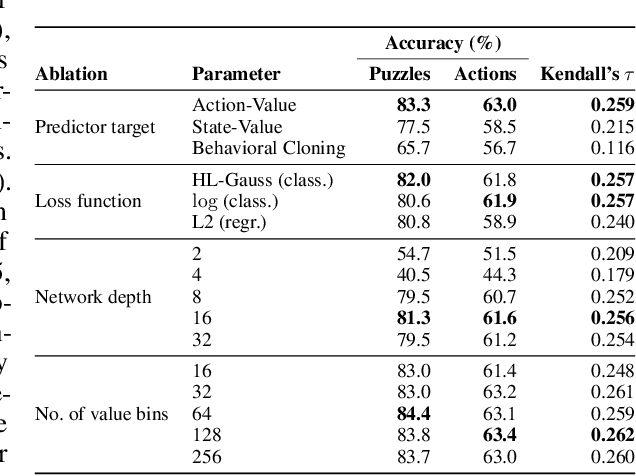
The recent breakthrough successes in machine learning are mainly attributed to scale: namely large-scale attention-based architectures and datasets of unprecedented scale. This paper investigates the impact of training at scale for chess. Unlike traditional chess engines that rely on complex heuristics, explicit search, or a combination of both, we train a 270M parameter transformer model with supervised learning on a dataset of 10 million chess games. We annotate each board in the dataset with action-values provided by the powerful Stockfish 16 engine, leading to roughly 15 billion data points. Our largest model reaches a Lichess blitz Elo of 2895 against humans, and successfully solves a series of challenging chess puzzles, without any domain-specific tweaks or explicit search algorithms. We also show that our model outperforms AlphaZero's policy and value networks (without MCTS) and GPT-3.5-turbo-instruct. A systematic investigation of model and dataset size shows that strong chess performance only arises at sufficient scale. To validate our results, we perform an extensive series of ablations of design choices and hyperparameters.