 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Minimax-Optimal Distributional Reinforcement Learning with a Generative Model
Feb 12, 2024



We propose a new algorithm for model-based distributional reinforcement learning (RL), and prove that it is minimax-optimal for approximating return distributions with a generative model (up to logarithmic factors), resolving an open question of Zhang et al. (2023). Our analysis provides new theoretical results on categorical approaches to distributional RL, and also introduces a new distributional Bellman equation, the stochastic categorical CDF Bellman equation, which we expect to be of independent interest. We also provide an experimental study comparing several model-based distributional RL algorithms, with several takeaways for practitioners.
Grandmaster-Level Chess Without Search
Feb 07, 2024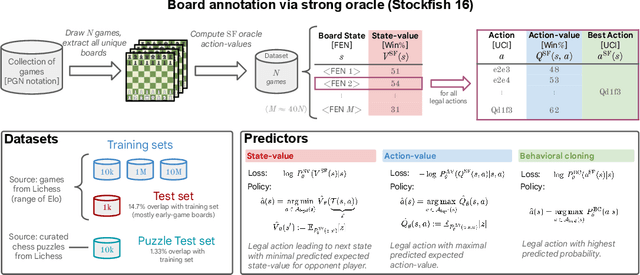
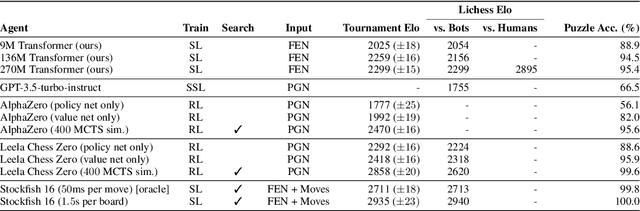
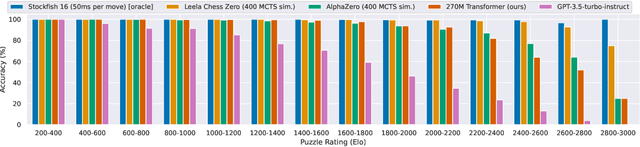
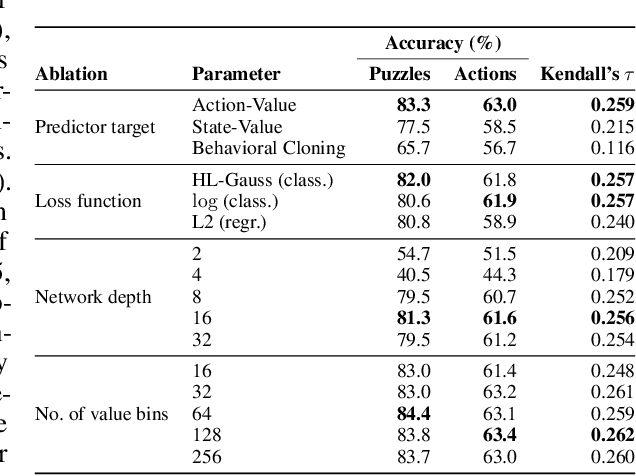
The recent breakthrough successes in machine learning are mainly attributed to scale: namely large-scale attention-based architectures and datasets of unprecedented scale. This paper investigates the impact of training at scale for chess. Unlike traditional chess engines that rely on complex heuristics, explicit search, or a combination of both, we train a 270M parameter transformer model with supervised learning on a dataset of 10 million chess games. We annotate each board in the dataset with action-values provided by the powerful Stockfish 16 engine, leading to roughly 15 billion data points. Our largest model reaches a Lichess blitz Elo of 2895 against humans, and successfully solves a series of challenging chess puzzles, without any domain-specific tweaks or explicit search algorithms. We also show that our model outperforms AlphaZero's policy and value networks (without MCTS) and GPT-3.5-turbo-instruct. A systematic investigation of model and dataset size shows that strong chess performance only arises at sufficient scale. To validate our results, we perform an extensive series of ablations of design choices and hyperparameters.
Learning Universal Predictors
Jan 26, 2024



Meta-learning has emerged as a powerful approach to train neural networks to learn new tasks quickly from limited data. Broad exposure to different tasks leads to versatile representations enabling general problem solving. But, what are the limits of meta-learning? In this work, we explore the potential of amortizing the most powerful universal predictor, namely Solomonoff Induction (SI), into neural networks via leveraging meta-learning to its limits. We use Universal Turing Machines (UTMs) to generate training data used to expose networks to a broad range of patterns. We provide theoretical analysis of the UTM data generation processes and meta-training protocols. We conduct comprehensive experiments with neural architectures (e.g. LSTMs, Transformers) and algorithmic data generators of varying complexity and universality. Our results suggest that UTM data is a valuable resource for meta-learning, and that it can be used to train neural networks capable of learning universal prediction strategies.
Distributional Bellman Operators over Mean Embeddings
Dec 09, 2023We propose a novel algorithmic framework for distributional reinforcement learning, based on learning finite-dimensional mean embeddings of return distributions. We derive several new algorithms for dynamic programming and temporal-difference learning based on this framework, provide asymptotic convergence theory, and examine the empirical performance of the algorithms on a suite of tabular tasks. Further, we show that this approach can be straightforwardly combined with deep reinforcement learning, and obtain a new deep RL agent that improves over baseline distributional approaches on the Arcade Learning Environment.
Score-based generative models learn manifold-like structures with constrained mixing
Nov 16, 2023



How do score-based generative models (SBMs) learn the data distribution supported on a low-dimensional manifold? We investigate the score model of a trained SBM through its linear approximations and subspaces spanned by local feature vectors. During diffusion as the noise decreases, the local dimensionality increases and becomes more varied between different sample sequences. Importantly, we find that the learned vector field mixes samples by a non-conservative field within the manifold, although it denoises with normal projections as if there is an energy function in off-manifold directions. At each noise level, the subspace spanned by the local features overlap with an effective density function. These observations suggest that SBMs can flexibly mix samples with the learned score field while carefully maintaining a manifold-like structure of the data distribution.
TacticAI: an AI assistant for football tactics
Oct 17, 2023Identifying key patterns of tactics implemented by rival teams, and developing effective responses, lies at the heart of modern football. However, doing so algorithmically remains an open research challenge. To address this unmet need, we propose TacticAI, an AI football tactics assistant developed and evaluated in close collaboration with domain experts from Liverpool FC. We focus on analysing corner kicks, as they offer coaches the most direct opportunities for interventions and improvements. TacticAI incorporates both a predictive and a generative component, allowing the coaches to effectively sample and explore alternative player setups for each corner kick routine and to select those with the highest predicted likelihood of success. We validate TacticAI on a number of relevant benchmark tasks: predicting receivers and shot attempts and recommending player position adjustments. The utility of TacticAI is validated by a qualitative study conducted with football domain experts at Liverpool FC. We show that TacticAI's model suggestions are not only indistinguishable from real tactics, but also favoured over existing tactics 90% of the time, and that TacticAI offers an effective corner kick retrieval system. TacticAI achieves these results despite the limited availability of gold-standard data, achieving data efficiency through geometric deep learning.
Language Modeling Is Compression
Sep 19, 2023It has long been established that predictive models can be transformed into lossless compressors and vice versa. Incidentally, in recent years, the machine learning community has focused on training increasingly large and powerful self-supervised (language) models. Since these large language models exhibit impressive predictive capabilities, they are well-positioned to be strong compressors. In this work, we advocate for viewing the prediction problem through the lens of compression and evaluate the compression capabilities of large (foundation) models. We show that large language models are powerful general-purpose predictors and that the compression viewpoint provides novel insights into scaling laws, tokenization, and in-context learning. For example, Chinchilla 70B, while trained primarily on text, compresses ImageNet patches to 43.4% and LibriSpeech samples to 16.4% of their raw size, beating domain-specific compressors like PNG (58.5%) or FLAC (30.3%), respectively. Finally, we show that the prediction-compression equivalence allows us to use any compressor (like gzip) to build a conditional generative model.
Memory-Based Meta-Learning on Non-Stationary Distributions
Feb 06, 2023Memory-based meta-learning is a technique for approximating Bayes-optimal predictors. Under fairly general conditions, minimizing sequential prediction error, measured by the log loss, leads to implicit meta-learning. The goal of this work is to investigate how far this interpretation can be realized by current sequence prediction models and training regimes. The focus is on piecewise stationary sources with unobserved switching-points, which arguably capture an important characteristic of natural language and action-observation sequences in partially observable environments. We show that various types of memory-based neural models, including Transformers, LSTMs, and RNNs can learn to accurately approximate known Bayes-optimal algorithms and behave as if performing Bayesian inference over the latent switching-points and the latent parameters governing the data distribution within each segment.
On the failure of variational score matching for VAE models
Oct 24, 2022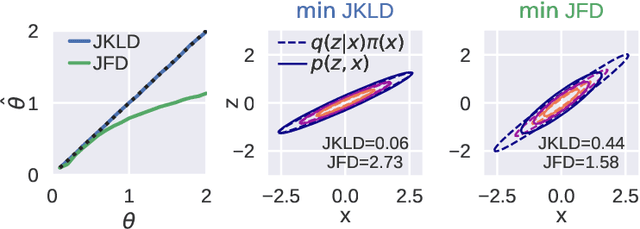
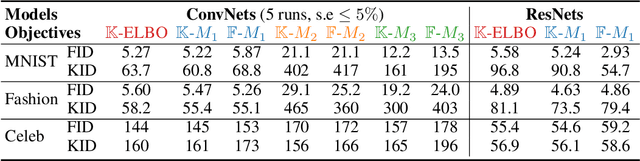
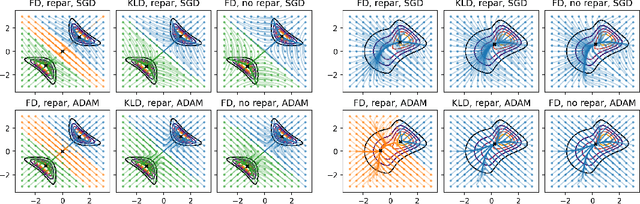
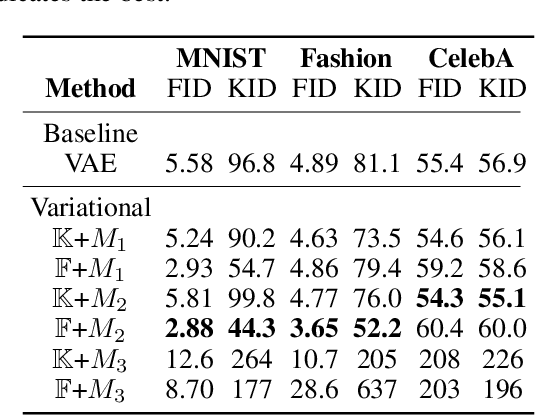
Score matching (SM) is a convenient method for training flexible probabilistic models, which is often preferred over the traditional maximum-likelihood (ML) approach. However, these models are less interpretable than normalized models; as such, training robustness is in general difficult to assess. We present a critical study of existing variational SM objectives, showing catastrophic failure on a wide range of datasets and network architectures. Our theoretical insights on the objectives emerge directly from their equivalent autoencoding losses when optimizing variational autoencoder (VAE) models. First, we show that in the Fisher autoencoder, SM produces far worse models than maximum-likelihood, and approximate inference by Fisher divergence can lead to low-density local optima. However, with important modifications, this objective reduces to a regularized autoencoding loss that resembles the evidence lower bound (ELBO). This analysis predicts that the modified SM algorithm should behave very similarly to ELBO on Gaussian VAEs. We then review two other FD-based objectives from the literature and show that they reduce to uninterpretable autoencoding losses, likely leading to poor performance. The experiments verify our theoretical predictions and suggest that only ELBO and the baseline objective robustly produce expected results, while previously proposed SM methods do not.
Neural Networks and the Chomsky Hierarchy
Jul 05, 2022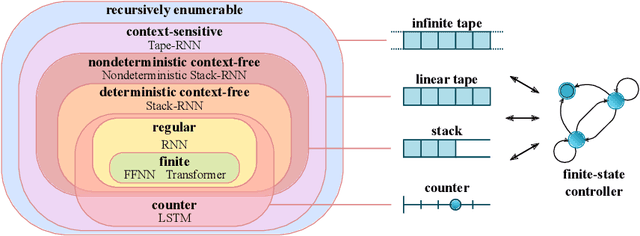



Reliable generalization lies at the heart of safe ML and AI. However, understanding when and how neural networks generalize remains one of the most important unsolved problems in the field. In this work, we conduct an extensive empirical study (2200 models, 16 tasks) to investigate whether insights from the theory of computation can predict the limits of neural network generalization in practice. We demonstrate that grouping tasks according to the Chomsky hierarchy allows us to forecast whether certain architectures will be able to generalize to out-of-distribution inputs. This includes negative results where even extensive amounts of data and training time never led to any non-trivial generalization, despite models having sufficient capacity to perfectly fit the training data. Our results show that, for our subset of tasks, RNNs and Transformers fail to generalize on non-regular tasks, LSTMs can solve regular and counter-language tasks, and only networks augmented with structured memory (such as a stack or memory tape) can successfully generalize on context-free and context-sensitive tasks.