 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom AGI to ASI
Jun 10, 2026Over the last decade, building human-level artificial general intelligence has moved from far-fetched speculation to being a concrete next-decade target for many of the largest AI organisations. Achieving this goal would have profound and far-reaching impacts on human society, which raises many complex questions for the decade ahead. This report investigates how AI itself might continue to develop in a post-AGI world along the continuum of machine intelligence. The endpoint of this continuum, Universal AI, is theoretically well understood, which provides some formal grounding for the main focus of this report: the transition from human-level AGI to artificial general superintelligence, which, intuitively, can be understood as a system that is more intelligent and cognitively capable than large organisations of humans. After characterizing ASI, the report discusses four potential pathways from AGI to ASI: scaling AGI, AI paradigm shifts, recursive improvement, and ASI emerging from large-scale multi-agent collectives. The report then discusses possible frictions and bottlenecks along these pathways. Determining whether the impact of these frictions will be negligible or substantial raises a number of concrete open research questions. Due to large uncertainties for predicting ASI progress, it cannot be ruled out that AI progress might continue to accelerate over the next years. This could imply that the image of a single transformative step change, caused by the introduction of human-level AGI into our society, could be inaccurate. More apt might be the prospect of a series of transformative societal changes caused by AI-enabled progress and breakthroughs across many areas of science and technology. Preparing for this prospect requires a massively interdisciplinary endeavour of global scope and interest.
Measuring Progress Toward AGI: A Cognitive Framework
May 27, 2026Despite widespread discussion of AGI, there is no clear framework for measuring progress toward it. This ambiguity fuels subjective claims, makes it difficult to track progress, and risks hindering responsible governance. As a starting point to address this gap, we present a framework for understanding system capabilities in relation to human cognitive abilities. Drawing from decades of research in psychology, neuroscience, and cognitive science, we introduce a Cognitive Taxonomy that deconstructs general intelligence into 10 key cognitive faculties. We then propose a rigorous evaluation protocol in which a system's performance is measured across a suite of targeted, held-out cognitive tasks, generating a 'cognitive profile' that can be used to understand a system's strengths and weaknesses. We hope this framework will provide a practical roadmap and an initial step toward more rigorous, empirical evaluation of AGI.
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Jul 15, 2025
AI systems that "think" in human language offer a unique opportunity for AI safety: we can monitor their chains of thought (CoT) for the intent to misbehave. Like all other known AI oversight methods, CoT monitoring is imperfect and allows some misbehavior to go unnoticed. Nevertheless, it shows promise and we recommend further research into CoT monitorability and investment in CoT monitoring alongside existing safety methods. Because CoT monitorability may be fragile, we recommend that frontier model developers consider the impact of development decisions on CoT monitorability.
An Approach to Technical AGI Safety and Security
Apr 02, 2025Artificial General Intelligence (AGI) promises transformative benefits but also presents significant risks. We develop an approach to address the risk of harms consequential enough to significantly harm humanity. We identify four areas of risk: misuse, misalignment, mistakes, and structural risks. Of these, we focus on technical approaches to misuse and misalignment. For misuse, our strategy aims to prevent threat actors from accessing dangerous capabilities, by proactively identifying dangerous capabilities, and implementing robust security, access restrictions, monitoring, and model safety mitigations. To address misalignment, we outline two lines of defense. First, model-level mitigations such as amplified oversight and robust training can help to build an aligned model. Second, system-level security measures such as monitoring and access control can mitigate harm even if the model is misaligned. Techniques from interpretability, uncertainty estimation, and safer design patterns can enhance the effectiveness of these mitigations. Finally, we briefly outline how these ingredients could be combined to produce safety cases for AGI systems.
Levels of AGI: Operationalizing Progress on the Path to AGI
Nov 04, 2023

We propose a framework for classifying the capabilities and behavior of Artificial General Intelligence (AGI) models and their precursors. This framework introduces levels of AGI performance, generality, and autonomy. It is our hope that this framework will be useful in an analogous way to the levels of autonomous driving, by providing a common language to compare models, assess risks, and measure progress along the path to AGI. To develop our framework, we analyze existing definitions of AGI, and distill six principles that a useful ontology for AGI should satisfy. These principles include focusing on capabilities rather than mechanisms; separately evaluating generality and performance; and defining stages along the path toward AGI, rather than focusing on the endpoint. With these principles in mind, we propose 'Levels of AGI' based on depth (performance) and breadth (generality) of capabilities, and reflect on how current systems fit into this ontology. We discuss the challenging requirements for future benchmarks that quantify the behavior and capabilities of AGI models against these levels. Finally, we discuss how these levels of AGI interact with deployment considerations such as autonomy and risk, and emphasize the importance of carefully selecting Human-AI Interaction paradigms for responsible and safe deployment of highly capable AI systems.
The Hydra Effect: Emergent Self-repair in Language Model Computations
Jul 28, 2023We investigate the internal structure of language model computations using causal analysis and demonstrate two motifs: (1) a form of adaptive computation where ablations of one attention layer of a language model cause another layer to compensate (which we term the Hydra effect) and (2) a counterbalancing function of late MLP layers that act to downregulate the maximum-likelihood token. Our ablation studies demonstrate that language model layers are typically relatively loosely coupled (ablations to one layer only affect a small number of downstream layers). Surprisingly, these effects occur even in language models trained without any form of dropout. We analyse these effects in the context of factual recall and consider their implications for circuit-level attribution in language models.
Randomized Positional Encodings Boost Length Generalization of Transformers
May 26, 2023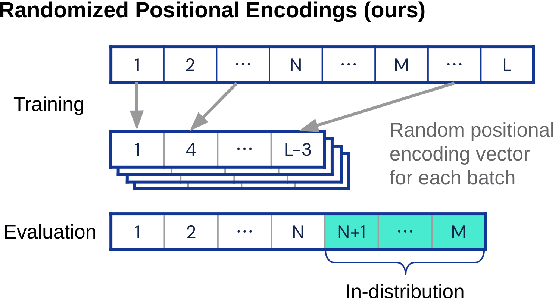
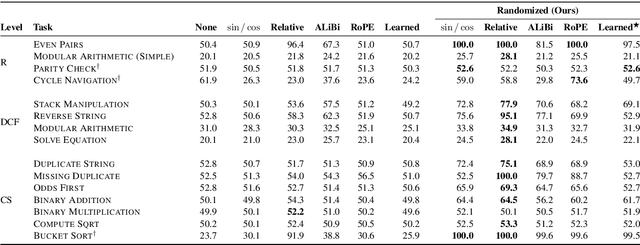
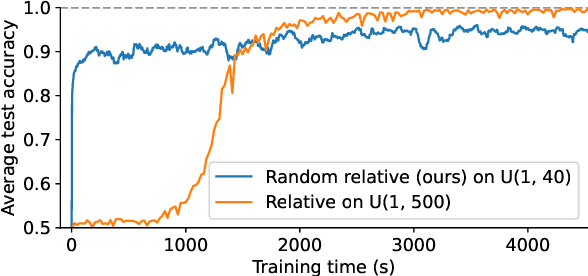
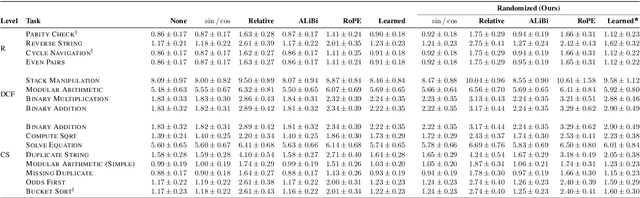
Transformers have impressive generalization capabilities on tasks with a fixed context length. However, they fail to generalize to sequences of arbitrary length, even for seemingly simple tasks such as duplicating a string. Moreover, simply training on longer sequences is inefficient due to the quadratic computation complexity of the global attention mechanism. In this work, we demonstrate that this failure mode is linked to positional encodings being out-of-distribution for longer sequences (even for relative encodings) and introduce a novel family of positional encodings that can overcome this problem. Concretely, our randomized positional encoding scheme simulates the positions of longer sequences and randomly selects an ordered subset to fit the sequence's length. Our large-scale empirical evaluation of 6000 models across 15 algorithmic reasoning tasks shows that our method allows Transformers to generalize to sequences of unseen length (increasing test accuracy by 12.0% on average).
Beyond Bayes-optimality: meta-learning what you know you don't know
Oct 12, 2022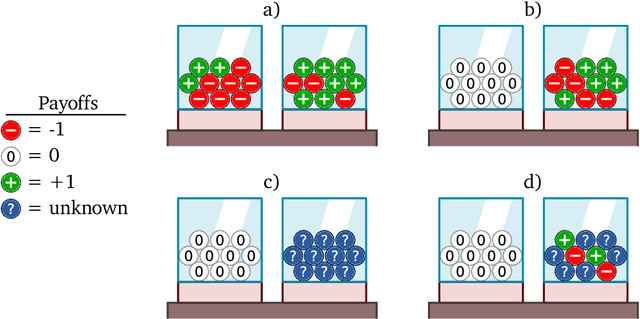



Meta-training agents with memory has been shown to culminate in Bayes-optimal agents, which casts Bayes-optimality as the implicit solution to a numerical optimization problem rather than an explicit modeling assumption. Bayes-optimal agents are risk-neutral, since they solely attune to the expected return, and ambiguity-neutral, since they act in new situations as if the uncertainty were known. This is in contrast to risk-sensitive agents, which additionally exploit the higher-order moments of the return, and ambiguity-sensitive agents, which act differently when recognizing situations in which they lack knowledge. Humans are also known to be averse to ambiguity and sensitive to risk in ways that aren't Bayes-optimal, indicating that such sensitivity can confer advantages, especially in safety-critical situations. How can we extend the meta-learning protocol to generate risk- and ambiguity-sensitive agents? The goal of this work is to fill this gap in the literature by showing that risk- and ambiguity-sensitivity also emerge as the result of an optimization problem using modified meta-training algorithms, which manipulate the experience-generation process of the learner. We empirically test our proposed meta-training algorithms on agents exposed to foundational classes of decision-making experiments and demonstrate that they become sensitive to risk and ambiguity.
Neural Networks and the Chomsky Hierarchy
Jul 05, 2022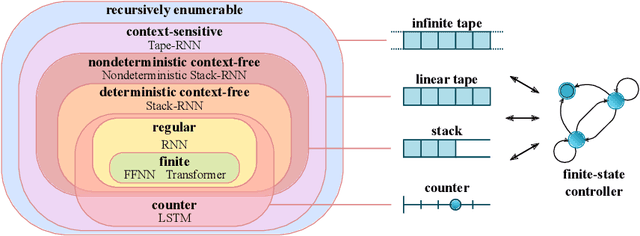



Reliable generalization lies at the heart of safe ML and AI. However, understanding when and how neural networks generalize remains one of the most important unsolved problems in the field. In this work, we conduct an extensive empirical study (2200 models, 16 tasks) to investigate whether insights from the theory of computation can predict the limits of neural network generalization in practice. We demonstrate that grouping tasks according to the Chomsky hierarchy allows us to forecast whether certain architectures will be able to generalize to out-of-distribution inputs. This includes negative results where even extensive amounts of data and training time never led to any non-trivial generalization, despite models having sufficient capacity to perfectly fit the training data. Our results show that, for our subset of tasks, RNNs and Transformers fail to generalize on non-regular tasks, LSTMs can solve regular and counter-language tasks, and only networks augmented with structured memory (such as a stack or memory tape) can successfully generalize on context-free and context-sensitive tasks.
Your Policy Regularizer is Secretly an Adversary
Apr 01, 2022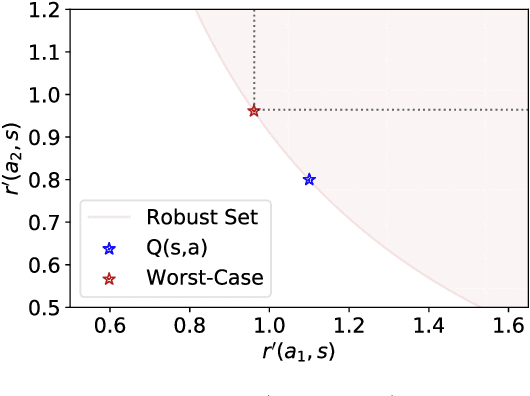

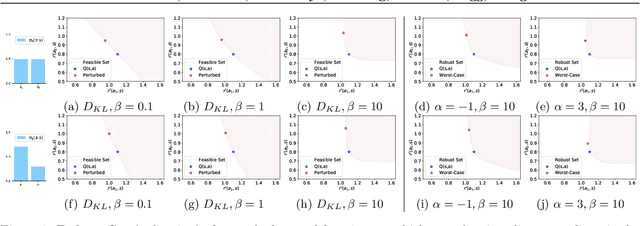

Policy regularization methods such as maximum entropy regularization are widely used in reinforcement learning to improve the robustness of a learned policy. In this paper, we show how this robustness arises from hedging against worst-case perturbations of the reward function, which are chosen from a limited set by an imagined adversary. Using convex duality, we characterize this robust set of adversarial reward perturbations under KL and alpha-divergence regularization, which includes Shannon and Tsallis entropy regularization as special cases. Importantly, generalization guarantees can be given within this robust set. We provide detailed discussion of the worst-case reward perturbations, and present intuitive empirical examples to illustrate this robustness and its relationship with generalization. Finally, we discuss how our analysis complements and extends previous results on adversarial reward robustness and path consistency optimality conditions.