 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Hydra Effect: Emergent Self-repair in Language Model Computations
Jul 28, 2023We investigate the internal structure of language model computations using causal analysis and demonstrate two motifs: (1) a form of adaptive computation where ablations of one attention layer of a language model cause another layer to compensate (which we term the Hydra effect) and (2) a counterbalancing function of late MLP layers that act to downregulate the maximum-likelihood token. Our ablation studies demonstrate that language model layers are typically relatively loosely coupled (ablations to one layer only affect a small number of downstream layers). Surprisingly, these effects occur even in language models trained without any form of dropout. We analyse these effects in the context of factual recall and consider their implications for circuit-level attribution in language models.
Power-seeking can be probable and predictive for trained agents
Apr 13, 2023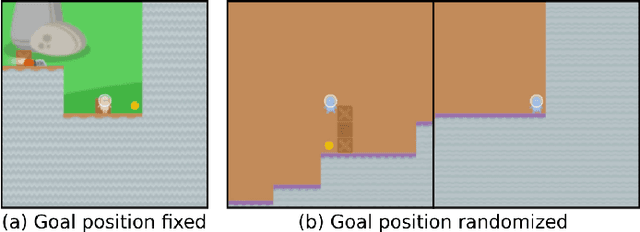
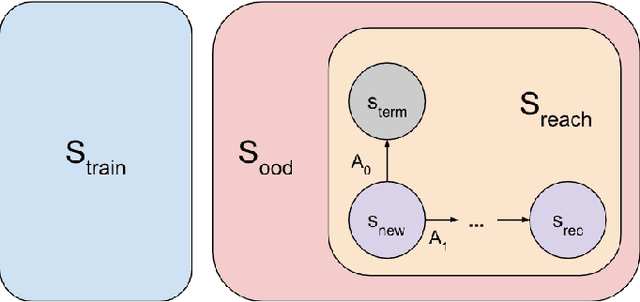
Power-seeking behavior is a key source of risk from advanced AI, but our theoretical understanding of this phenomenon is relatively limited. Building on existing theoretical results demonstrating power-seeking incentives for most reward functions, we investigate how the training process affects power-seeking incentives and show that they are still likely to hold for trained agents under some simplifying assumptions. We formally define the training-compatible goal set (the set of goals consistent with the training rewards) and assume that the trained agent learns a goal from this set. In a setting where the trained agent faces a choice to shut down or avoid shutdown in a new situation, we prove that the agent is likely to avoid shutdown. Thus, we show that power-seeking incentives can be probable (likely to arise for trained agents) and predictive (allowing us to predict undesirable behavior in new situations).
Guidelines for Artificial Intelligence Containment
Jul 24, 2017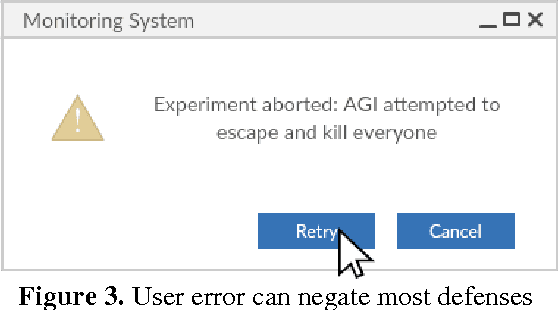
With almost daily improvements in capabilities of artificial intelligence it is more important than ever to develop safety software for use by the AI research community. Building on our previous work on AI Containment Problem we propose a number of guidelines which should help AI safety researchers to develop reliable sandboxing software for intelligent programs of all levels. Such safety container software will make it possible to study and analyze intelligent artificial agent while maintaining certain level of safety against information leakage, social engineering attacks and cyberattacks from within the container.
The AGI Containment Problem
Jul 13, 2016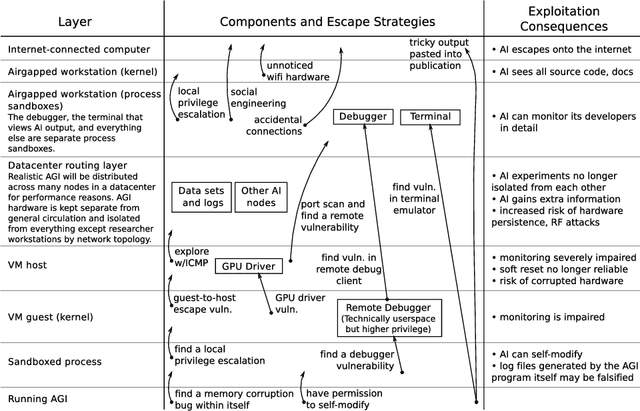
There is considerable uncertainty about what properties, capabilities and motivations future AGIs will have. In some plausible scenarios, AGIs may pose security risks arising from accidents and defects. In order to mitigate these risks, prudent early AGI research teams will perform significant testing on their creations before use. Unfortunately, if an AGI has human-level or greater intelligence, testing itself may not be safe; some natural AGI goal systems create emergent incentives for AGIs to tamper with their test environments, make copies of themselves on the internet, or convince developers and operators to do dangerous things. In this paper, we survey the AGI containment problem - the question of how to build a container in which tests can be conducted safely and reliably, even on AGIs with unknown motivations and capabilities that could be dangerous. We identify requirements for AGI containers, available mechanisms, and weaknesses that need to be addressed.