 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransdisciplinary AI Observatory -- Retrospective Analyses and Future-Oriented Contradistinctions
Dec 07, 2020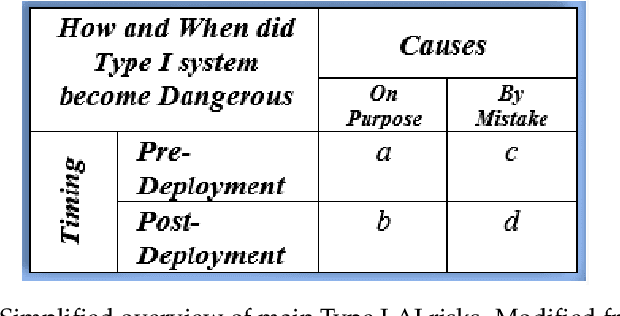
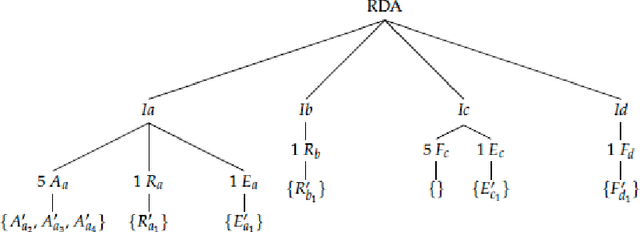
In the last years, AI safety gained international recognition in the light of heterogeneous safety-critical and ethical issues that risk overshadowing the broad beneficial impacts of AI. In this context, the implementation of AI observatory endeavors represents one key research direction. This paper motivates the need for an inherently transdisciplinary AI observatory approach integrating diverse retrospective and counterfactual views. We delineate aims and limitations while providing hands-on-advice utilizing concrete practical examples. Distinguishing between unintentionally and intentionally triggered AI risks with diverse socio-psycho-technological impacts, we exemplify a retrospective descriptive analysis followed by a retrospective counterfactual risk analysis. Building on these AI observatory tools, we present near-term transdisciplinary guidelines for AI safety. As further contribution, we discuss differentiated and tailored long-term directions through the lens of two disparate modern AI safety paradigms. For simplicity, we refer to these two different paradigms with the terms artificial stupidity (AS) and eternal creativity (EC) respectively. While both AS and EC acknowledge the need for a hybrid cognitive-affective approach to AI safety and overlap with regard to many short-term considerations, they differ fundamentally in the nature of multiple envisaged long-term solution patterns. By compiling relevant underlying contradistinctions, we aim to provide future-oriented incentives for constructive dialectics in practical and theoretical AI safety research.
Chess as a Testing Grounds for the Oracle Approach to AI Safety
Oct 06, 2020To reduce the danger of powerful super-intelligent AIs, we might make the first such AIs oracles that can only send and receive messages. This paper proposes a possibly practical means of using machine learning to create two classes of narrow AI oracles that would provide chess advice: those aligned with the player's interest, and those that want the player to lose and give deceptively bad advice. The player would be uncertain which type of oracle it was interacting with. As the oracles would be vastly more intelligent than the player in the domain of chess, experience with these oracles might help us prepare for future artificial general intelligence oracles.
An AGI with Time-Inconsistent Preferences
Jun 23, 2019This paper reveals a trap for artificial general intelligence (AGI) theorists who use economists' standard method of discounting. This trap is implicitly and falsely assuming that a rational AGI would have time-consistent preferences. An agent with time-inconsistent preferences knows that its future self will disagree with its current self concerning intertemporal decision making. Such an agent cannot automatically trust its future self to carry out plans that its current self considers optimal.
The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation
Feb 20, 2018
This report surveys the landscape of potential security threats from malicious uses of AI, and proposes ways to better forecast, prevent, and mitigate these threats. After analyzing the ways in which AI may influence the threat landscape in the digital, physical, and political domains, we make four high-level recommendations for AI researchers and other stakeholders. We also suggest several promising areas for further research that could expand the portfolio of defenses, or make attacks less effective or harder to execute. Finally, we discuss, but do not conclusively resolve, the long-term equilibrium of attackers and defenders.
Towards Moral Autonomous Systems
Oct 31, 2017
Both the ethics of autonomous systems and the problems of their technical implementation have by now been studied in some detail. Less attention has been given to the areas in which these two separate concerns meet. This paper, written by both philosophers and engineers of autonomous systems, addresses a number of issues in machine ethics that are located at precisely the intersection between ethics and engineering. We first discuss the main challenges which, in our view, machine ethics posses to moral philosophy. We them consider different approaches towards the conceptual design of autonomous systems and their implications on the ethics implementation in such systems. Then we examine problematic areas regarding the specification and verification of ethical behavior in autonomous systems, particularly with a view towards the requirements of future legislation. We discuss transparency and accountability issues that will be crucial for any future wide deployment of autonomous systems in society. Finally we consider the, often overlooked, possibility of intentional misuse of AI systems and the possible dangers arising out of deliberately unethical design, implementation, and use of autonomous robots.
The AGI Containment Problem
Jul 13, 2016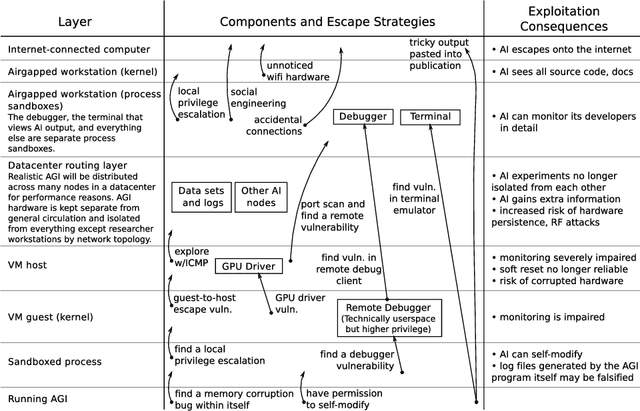
There is considerable uncertainty about what properties, capabilities and motivations future AGIs will have. In some plausible scenarios, AGIs may pose security risks arising from accidents and defects. In order to mitigate these risks, prudent early AGI research teams will perform significant testing on their creations before use. Unfortunately, if an AGI has human-level or greater intelligence, testing itself may not be safe; some natural AGI goal systems create emergent incentives for AGIs to tamper with their test environments, make copies of themselves on the internet, or convince developers and operators to do dangerous things. In this paper, we survey the AGI containment problem - the question of how to build a container in which tests can be conducted safely and reliably, even on AGIs with unknown motivations and capabilities that could be dangerous. We identify requirements for AGI containers, available mechanisms, and weaknesses that need to be addressed.