 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE and Diverse Generalization via Selective Disagreement
Sep 09, 2025Deep neural networks are notoriously sensitive to spurious correlations - where a model learns a shortcut that fails out-of-distribution. Existing work on spurious correlations has often focused on incomplete correlations,leveraging access to labeled instances that break the correlation. But in cases where the spurious correlations are complete, the correct generalization is fundamentally \textit{underspecified}. To resolve this underspecification, we propose learning a set of concepts that are consistent with training data but make distinct predictions on a subset of novel unlabeled inputs. Using a self-training approach that encourages \textit{confident} and \textit{selective} disagreement, our method ACE matches or outperforms existing methods on a suite of complete-spurious correlation benchmarks, while remaining robust to incomplete spurious correlations. ACE is also more configurable than prior approaches, allowing for straight-forward encoding of prior knowledge and principled unsupervised model selection. In an early application to language-model alignment, we find that ACE achieves competitive performance on the measurement tampering detection benchmark \textit{without} access to untrusted measurements. While still subject to important limitations, ACE represents significant progress towards overcoming underspecification.
CoinRun: Solving Goal Misgeneralisation
Sep 28, 2023Goal misgeneralisation is a key challenge in AI alignment -- the task of getting powerful Artificial Intelligences to align their goals with human intentions and human morality. In this paper, we show how the ACE (Algorithm for Concept Extrapolation) agent can solve one of the key standard challenges in goal misgeneralisation: the CoinRun challenge. It uses no new reward information in the new environment. This points to how autonomous agents could be trusted to act in human interests, even in novel and critical situations.
Concept Extrapolation: A Conceptual Primer
Jun 19, 2023This article is a primer on concept extrapolation - the ability to take a concept, a feature, or a goal that is defined in one context and extrapolate it safely to a more general context. Concept extrapolation aims to solve model splintering - a ubiquitous occurrence wherein the features or concepts shift as the world changes over time. Through discussing value splintering and value extrapolation the article argues that concept extrapolation is necessary for Artificial Intelligence alignment.
Recognising the importance of preference change: A call for a coordinated multidisciplinary research effort in the age of AI
Mar 30, 2022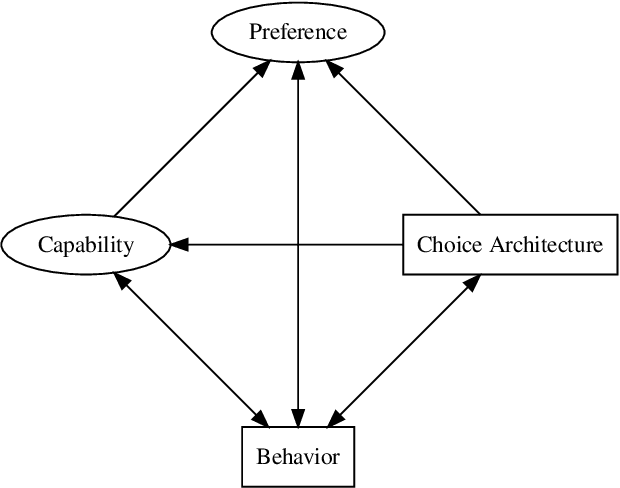
As artificial intelligence becomes more powerful and a ubiquitous presence in daily life, it is imperative to understand and manage the impact of AI systems on our lives and decisions. Modern ML systems often change user behavior (e.g. personalized recommender systems learn user preferences to deliver recommendations that change online behavior). An externality of behavior change is preference change. This article argues for the establishment of a multidisciplinary endeavor focused on understanding how AI systems change preference: Preference Science. We operationalize preference to incorporate concepts from various disciplines, outlining the importance of meta-preferences and preference-change preferences, and proposing a preliminary framework for how preferences change. We draw a distinction between preference change, permissible preference change, and outright preference manipulation. A diversity of disciplines contribute unique insights to this framework.
* Accepted at the AAAI-22 Workshop on AI For Behavior Change held at the Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI-22), 7 pages, 1 figure
The dangers in algorithms learning humans' values and irrationalities
Mar 01, 2022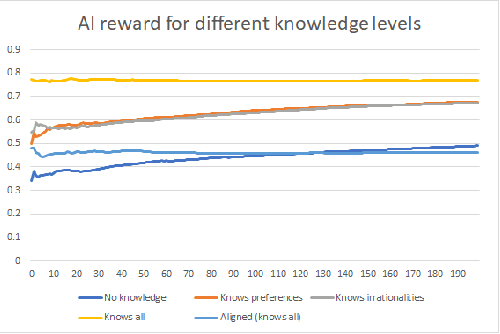
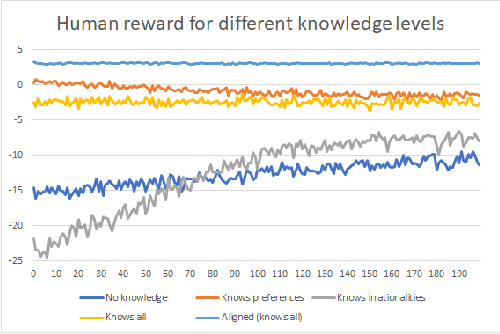
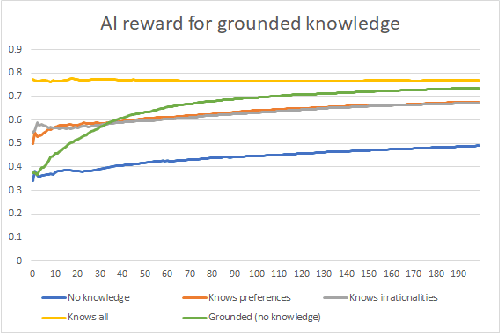
For an artificial intelligence (AI) to be aligned with human values (or human preferences), it must first learn those values. AI systems that are trained on human behavior, risk miscategorising human irrationalities as human values -- and then optimising for these irrationalities. Simply learning human values still carries risks: AI learning them will inevitably also gain information on human irrationalities and human behaviour/policy. Both of these can be dangerous: knowing human policy allows an AI to become generically more powerful (whether it is partially aligned or not aligned at all), while learning human irrationalities allows it to exploit humans without needing to provide value in return. This paper analyses the danger in developing artificial intelligence that learns about human irrationalities and human policy, and constructs a model recommendation system with various levels of information about human biases, human policy, and human values. It concludes that, whatever the power and knowledge of the AI, it is more dangerous for it to know human irrationalities than human values. Thus it is better for the AI to learn human values directly, rather than learning human biases and then deducing values from behaviour.
Chess as a Testing Grounds for the Oracle Approach to AI Safety
Oct 06, 2020To reduce the danger of powerful super-intelligent AIs, we might make the first such AIs oracles that can only send and receive messages. This paper proposes a possibly practical means of using machine learning to create two classes of narrow AI oracles that would provide chess advice: those aligned with the player's interest, and those that want the player to lose and give deceptively bad advice. The player would be uncertain which type of oracle it was interacting with. As the oracles would be vastly more intelligent than the player in the domain of chess, experience with these oracles might help us prepare for future artificial general intelligence oracles.
Pitfalls of learning a reward function online
Apr 28, 2020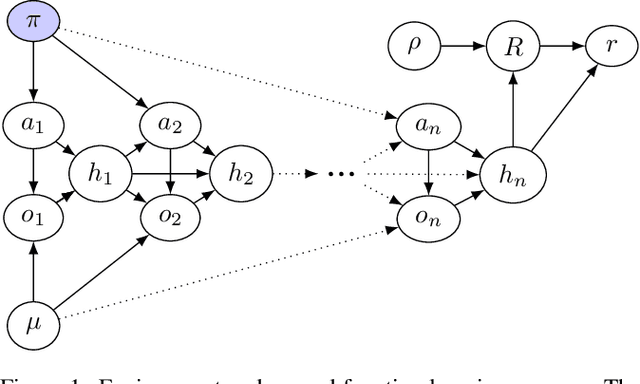



In some agent designs like inverse reinforcement learning an agent needs to learn its own reward function. Learning the reward function and optimising for it are typically two different processes, usually performed at different stages. We consider a continual (``one life'') learning approach where the agent both learns the reward function and optimises for it at the same time. We show that this comes with a number of pitfalls, such as deliberately manipulating the learning process in one direction, refusing to learn, ``learning'' facts already known to the agent, and making decisions that are strictly dominated (for all relevant reward functions). We formally introduce two desirable properties: the first is `unriggability', which prevents the agent from steering the learning process in the direction of a reward function that is easier to optimise. The second is `uninfluenceability', whereby the reward-function learning process operates by learning facts about the environment. We show that an uninfluenceable process is automatically unriggable, and if the set of possible environments is sufficiently rich, the converse is true too.
Occam's razor is insufficient to infer the preferences of irrational agents
Oct 29, 2018Inverse reinforcement learning (IRL) attempts to infer human rewards or preferences from observed behavior. Since human planning systematically deviates from rationality, several approaches have been tried to account for specific human shortcomings. However, the general problem of inferring the reward function of an agent of unknown rationality has received little attention. Unlike the well-known ambiguity problems in IRL, this one is practically relevant but cannot be resolved by observing the agent's policy in enough environments. This paper shows (1) that a No Free Lunch result implies it is impossible to uniquely decompose a policy into a planning algorithm and reward function, and (2) that even with a reasonable simplicity prior/Occam's razor on the set of decompositions, we cannot distinguish between the true decomposition and others that lead to high regret. To address this, we need simple `normative' assumptions, which cannot be deduced exclusively from observations.
Good and safe uses of AI Oracles
Jun 05, 2018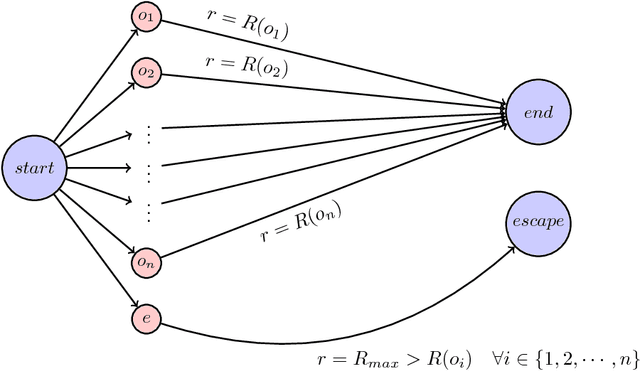
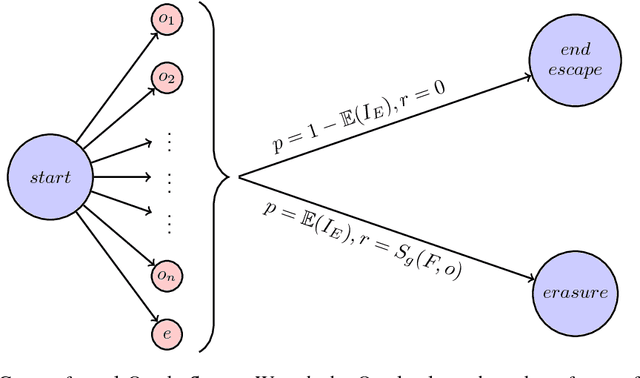


It is possible that powerful and potentially dangerous artificial intelligence (AI) might be developed in the future. An Oracle is a design which aims to restrain the impact of a potentially dangerous AI by restricting the agent to no actions besides answering questions. Unfortunately, most Oracles will be motivated to gain more control over the world by manipulating users through the content of their answers, and Oracles of potentially high intelligence might be very successful at this \citep{DBLP:journals/corr/AlfonsecaCACAR16}. In this paper we present two designs for Oracles which, even under pessimistic assumptions, will not manipulate their users into releasing them and yet will still be incentivised to provide their users with helpful answers. The first design is the counterfactual Oracle -- which choses its answer as if it expected nobody to ever read it. The second design is the low-bandwidth Oracle -- which is limited by the quantity of information it can transmit.
'Indifference' methods for managing agent rewards
Jun 05, 2018
`Indifference' refers to a class of methods used to control reward based agents. Indifference techniques aim to achieve one or more of three distinct goals: rewards dependent on certain events (without the agent being motivated to manipulate the probability of those events), effective disbelief (where agents behave as if particular events could never happen), and seamless transition from one reward function to another (with the agent acting as if this change is unanticipated). This paper presents several methods for achieving these goals in the POMDP setting, establishing their uses, strengths, and requirements. These methods of control work even when the implications of the agent's reward are otherwise not fully understood.