 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePitfalls of learning a reward function online
Paper and Code
Apr 28, 2020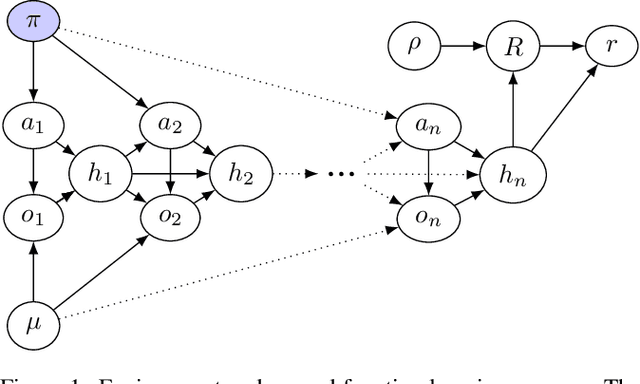



In some agent designs like inverse reinforcement learning an agent needs to learn its own reward function. Learning the reward function and optimising for it are typically two different processes, usually performed at different stages. We consider a continual (``one life'') learning approach where the agent both learns the reward function and optimises for it at the same time. We show that this comes with a number of pitfalls, such as deliberately manipulating the learning process in one direction, refusing to learn, ``learning'' facts already known to the agent, and making decisions that are strictly dominated (for all relevant reward functions). We formally introduce two desirable properties: the first is `unriggability', which prevents the agent from steering the learning process in the direction of a reward function that is easier to optimise. The second is `uninfluenceability', whereby the reward-function learning process operates by learning facts about the environment. We show that an uninfluenceable process is automatically unriggable, and if the set of possible environments is sufficiently rich, the converse is true too.