 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE and Diverse Generalization via Selective Disagreement
Sep 09, 2025Deep neural networks are notoriously sensitive to spurious correlations - where a model learns a shortcut that fails out-of-distribution. Existing work on spurious correlations has often focused on incomplete correlations,leveraging access to labeled instances that break the correlation. But in cases where the spurious correlations are complete, the correct generalization is fundamentally \textit{underspecified}. To resolve this underspecification, we propose learning a set of concepts that are consistent with training data but make distinct predictions on a subset of novel unlabeled inputs. Using a self-training approach that encourages \textit{confident} and \textit{selective} disagreement, our method ACE matches or outperforms existing methods on a suite of complete-spurious correlation benchmarks, while remaining robust to incomplete spurious correlations. ACE is also more configurable than prior approaches, allowing for straight-forward encoding of prior knowledge and principled unsupervised model selection. In an early application to language-model alignment, we find that ACE achieves competitive performance on the measurement tampering detection benchmark \textit{without} access to untrusted measurements. While still subject to important limitations, ACE represents significant progress towards overcoming underspecification.
CoinRun: Solving Goal Misgeneralisation
Sep 28, 2023Goal misgeneralisation is a key challenge in AI alignment -- the task of getting powerful Artificial Intelligences to align their goals with human intentions and human morality. In this paper, we show how the ACE (Algorithm for Concept Extrapolation) agent can solve one of the key standard challenges in goal misgeneralisation: the CoinRun challenge. It uses no new reward information in the new environment. This points to how autonomous agents could be trusted to act in human interests, even in novel and critical situations.
Strengthening the EU AI Act: Defining Key Terms on AI Manipulation
Aug 30, 2023The European Union's Artificial Intelligence Act aims to regulate manipulative and harmful uses of AI, but lacks precise definitions for key concepts. This paper provides technical recommendations to improve the Act's conceptual clarity and enforceability. We review psychological models to define "personality traits," arguing the Act should protect full "psychometric profiles." We urge expanding "behavior" to include "preferences" since preferences causally influence and are influenced by behavior. Clear definitions are provided for "subliminal," "manipulative," and "deceptive" techniques, considering incentives, intent, and covertness. We distinguish "exploiting individuals" from "exploiting groups," emphasising different policy needs. An "informed decision" is defined by four facets: comprehension, accurate information, no manipulation, and understanding AI's influence. We caution the Act's therapeutic use exemption given the lack of regulation of digital therapeutics by the EMA. Overall, the recommendations strengthen definitions of vague concepts in the EU AI Act, enhancing precise applicability to regulate harmful AI manipulation.
Concept Extrapolation: A Conceptual Primer
Jun 19, 2023This article is a primer on concept extrapolation - the ability to take a concept, a feature, or a goal that is defined in one context and extrapolate it safely to a more general context. Concept extrapolation aims to solve model splintering - a ubiquitous occurrence wherein the features or concepts shift as the world changes over time. Through discussing value splintering and value extrapolation the article argues that concept extrapolation is necessary for Artificial Intelligence alignment.
Recognising the importance of preference change: A call for a coordinated multidisciplinary research effort in the age of AI
Mar 30, 2022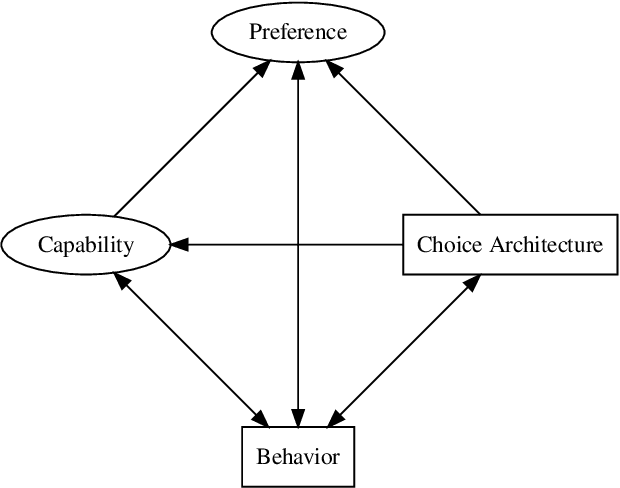
As artificial intelligence becomes more powerful and a ubiquitous presence in daily life, it is imperative to understand and manage the impact of AI systems on our lives and decisions. Modern ML systems often change user behavior (e.g. personalized recommender systems learn user preferences to deliver recommendations that change online behavior). An externality of behavior change is preference change. This article argues for the establishment of a multidisciplinary endeavor focused on understanding how AI systems change preference: Preference Science. We operationalize preference to incorporate concepts from various disciplines, outlining the importance of meta-preferences and preference-change preferences, and proposing a preliminary framework for how preferences change. We draw a distinction between preference change, permissible preference change, and outright preference manipulation. A diversity of disciplines contribute unique insights to this framework.
* Accepted at the AAAI-22 Workshop on AI For Behavior Change held at the Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI-22), 7 pages, 1 figure
The dangers in algorithms learning humans' values and irrationalities
Mar 01, 2022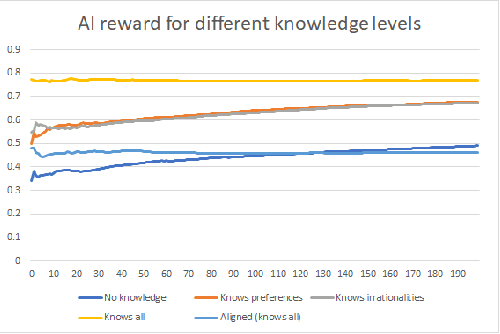
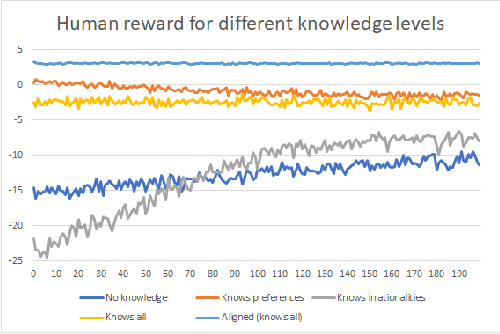
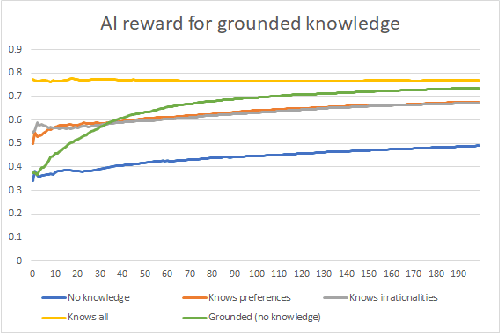
For an artificial intelligence (AI) to be aligned with human values (or human preferences), it must first learn those values. AI systems that are trained on human behavior, risk miscategorising human irrationalities as human values -- and then optimising for these irrationalities. Simply learning human values still carries risks: AI learning them will inevitably also gain information on human irrationalities and human behaviour/policy. Both of these can be dangerous: knowing human policy allows an AI to become generically more powerful (whether it is partially aligned or not aligned at all), while learning human irrationalities allows it to exploit humans without needing to provide value in return. This paper analyses the danger in developing artificial intelligence that learns about human irrationalities and human policy, and constructs a model recommendation system with various levels of information about human biases, human policy, and human values. It concludes that, whatever the power and knowledge of the AI, it is more dangerous for it to know human irrationalities than human values. Thus it is better for the AI to learn human values directly, rather than learning human biases and then deducing values from behaviour.