 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransdisciplinary AI Observatory -- Retrospective Analyses and Future-Oriented Contradistinctions
Dec 07, 2020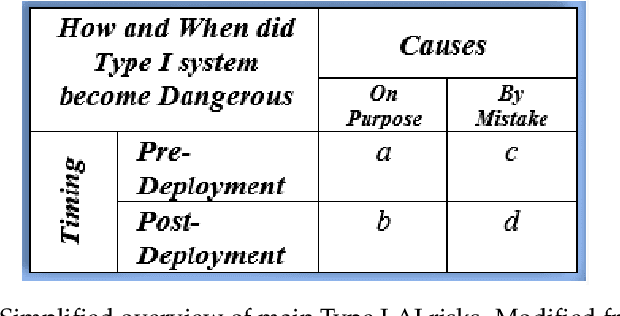
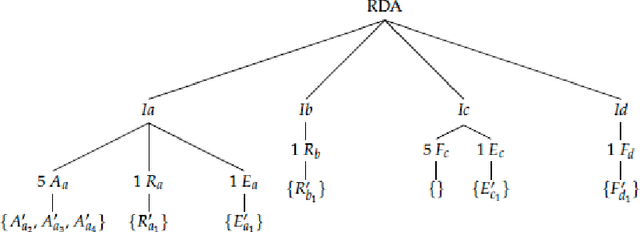
In the last years, AI safety gained international recognition in the light of heterogeneous safety-critical and ethical issues that risk overshadowing the broad beneficial impacts of AI. In this context, the implementation of AI observatory endeavors represents one key research direction. This paper motivates the need for an inherently transdisciplinary AI observatory approach integrating diverse retrospective and counterfactual views. We delineate aims and limitations while providing hands-on-advice utilizing concrete practical examples. Distinguishing between unintentionally and intentionally triggered AI risks with diverse socio-psycho-technological impacts, we exemplify a retrospective descriptive analysis followed by a retrospective counterfactual risk analysis. Building on these AI observatory tools, we present near-term transdisciplinary guidelines for AI safety. As further contribution, we discuss differentiated and tailored long-term directions through the lens of two disparate modern AI safety paradigms. For simplicity, we refer to these two different paradigms with the terms artificial stupidity (AS) and eternal creativity (EC) respectively. While both AS and EC acknowledge the need for a hybrid cognitive-affective approach to AI safety and overlap with regard to many short-term considerations, they differ fundamentally in the nature of multiple envisaged long-term solution patterns. By compiling relevant underlying contradistinctions, we aim to provide future-oriented incentives for constructive dialectics in practical and theoretical AI safety research.
Requisite Variety in Ethical Utility Functions for AI Value Alignment
Jun 30, 2019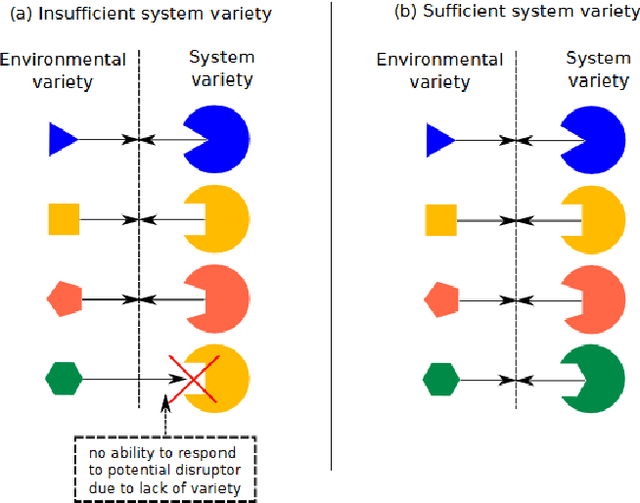
Being a complex subject of major importance in AI Safety research, value alignment has been studied from various perspectives in the last years. However, no final consensus on the design of ethical utility functions facilitating AI value alignment has been achieved yet. Given the urgency to identify systematic solutions, we postulate that it might be useful to start with the simple fact that for the utility function of an AI not to violate human ethical intuitions, it trivially has to be a model of these intuitions and reflect their variety $ - $ whereby the most accurate models pertaining to human entities being biological organisms equipped with a brain constructing concepts like moral judgements, are scientific models. Thus, in order to better assess the variety of human morality, we perform a transdisciplinary analysis applying a security mindset to the issue and summarizing variety-relevant background knowledge from neuroscience and psychology. We complement this information by linking it to augmented utilitarianism as a suitable ethical framework. Based on that, we propose first practical guidelines for the design of approximate ethical goal functions that might better capture the variety of human moral judgements. Finally, we conclude and address future possible challenges.
Augmented Utilitarianism for AGI Safety
Apr 02, 2019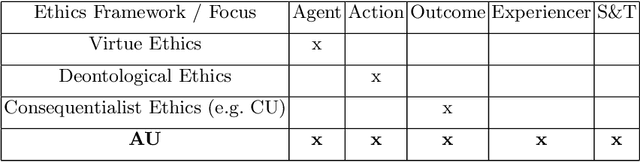
In the light of ongoing progresses of research on artificial intelligent systems exhibiting a steadily increasing problem-solving ability, the identification of practicable solutions to the value alignment problem in AGI Safety is becoming a matter of urgency. In this context, one preeminent challenge that has been addressed by multiple researchers is the adequate formulation of utility functions or equivalents reliably capturing human ethical conceptions. However, the specification of suitable utility functions harbors the risk of "perverse instantiation" for which no final consensus on responsible proactive countermeasures has been achieved so far. Amidst this background, we propose a novel socio-technological ethical framework denoted Augmented Utilitarianism which directly alleviates the perverse instantiation problem. We elaborate on how augmented by AI and more generally science and technology, it might allow a society to craft and update ethical utility functions while jointly undergoing a dynamical ethical enhancement. Further, we elucidate the need to consider embodied simulations in the design of utility functions for AGIs aligned with human values. Finally, we discuss future prospects regarding the usage of the presented scientifically grounded ethical framework and mention possible challenges.