 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRequisite Variety in Ethical Utility Functions for AI Value Alignment
Paper and Code
Jun 30, 2019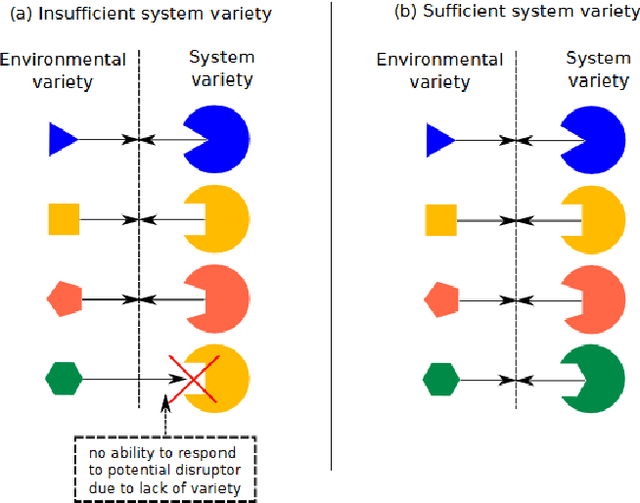
Being a complex subject of major importance in AI Safety research, value alignment has been studied from various perspectives in the last years. However, no final consensus on the design of ethical utility functions facilitating AI value alignment has been achieved yet. Given the urgency to identify systematic solutions, we postulate that it might be useful to start with the simple fact that for the utility function of an AI not to violate human ethical intuitions, it trivially has to be a model of these intuitions and reflect their variety $ - $ whereby the most accurate models pertaining to human entities being biological organisms equipped with a brain constructing concepts like moral judgements, are scientific models. Thus, in order to better assess the variety of human morality, we perform a transdisciplinary analysis applying a security mindset to the issue and summarizing variety-relevant background knowledge from neuroscience and psychology. We complement this information by linking it to augmented utilitarianism as a suitable ethical framework. Based on that, we propose first practical guidelines for the design of approximate ethical goal functions that might better capture the variety of human moral judgements. Finally, we conclude and address future possible challenges.