 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpossibility Results in AI: A Survey
Sep 01, 2021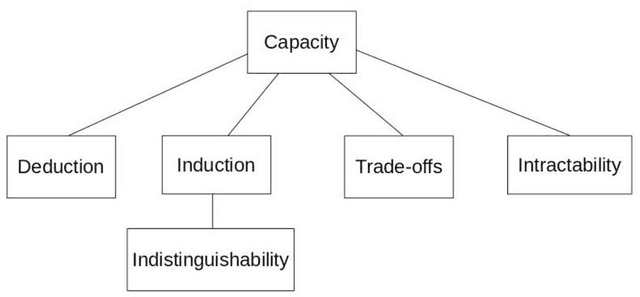
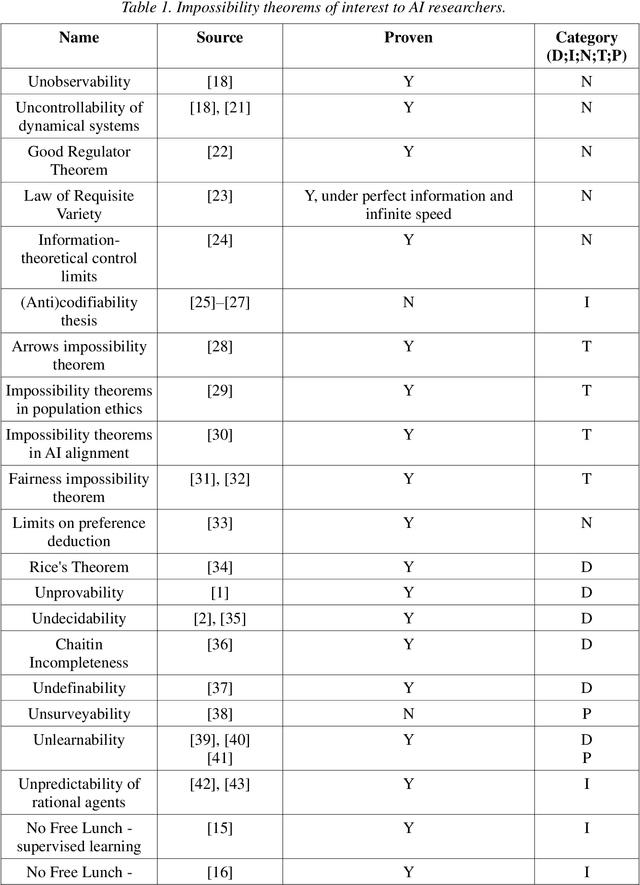

An impossibility theorem demonstrates that a particular problem or set of problems cannot be solved as described in the claim. Such theorems put limits on what is possible to do concerning artificial intelligence, especially the super-intelligent one. As such, these results serve as guidelines, reminders, and warnings to AI safety, AI policy, and governance researchers. These might enable solutions to some long-standing questions in the form of formalizing theories in the framework of constraint satisfaction without committing to one option. In this paper, we have categorized impossibility theorems applicable to the domain of AI into five categories: deduction, indistinguishability, induction, tradeoffs, and intractability. We found that certain theorems are too specific or have implicit assumptions that limit application. Also, we added a new result (theorem) about the unfairness of explainability, the first explainability-related result in the induction category. We concluded that deductive impossibilities deny 100%-guarantees for security. In the end, we give some ideas that hold potential in explainability, controllability, value alignment, ethics, and group decision-making. They can be deepened by further investigation.
AI Risk Skepticism
May 13, 2021
In this work, we survey skepticism regarding AI risk and show parallels with other types of scientific skepticism. We start by classifying different types of AI Risk skepticism and analyze their root causes. We conclude by suggesting some intervention approaches, which may be successful in reducing AI risk skepticism, at least amongst artificial intelligence researchers.
Understanding and Avoiding AI Failures: A Practical Guide
Apr 28, 2021
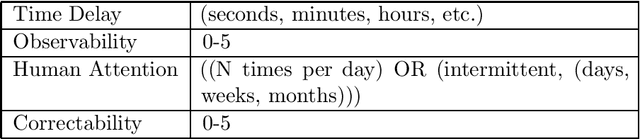


As AI technologies increase in capability and ubiquity, AI accidents are becoming more common. Based on normal accident theory, high reliability theory, and open systems theory, we create a framework for understanding the risks associated with AI applications. In addition, we also use AI safety principles to quantify the unique risks of increased intelligence and human-like qualities in AI. Together, these two fields give a more complete picture of the risks of contemporary AI. By focusing on system properties near accidents instead of seeking a root cause of accidents, we identify where attention should be paid to safety for current generation AI systems.
On Controllability of AI
Jul 19, 2020
Invention of artificial general intelligence is predicted to cause a shift in the trajectory of human civilization. In order to reap the benefits and avoid pitfalls of such powerful technology it is important to be able to control it. However, possibility of controlling artificial general intelligence and its more advanced version, superintelligence, has not been formally established. In this paper, we present arguments as well as supporting evidence from multiple domains indicating that advanced AI can't be fully controlled. Consequences of uncontrollability of AI are discussed with respect to future of humanity and research on AI, and AI safety and security.
Human $ eq$ AGI
Jul 11, 2020Terms Artificial General Intelligence (AGI) and Human-Level Artificial Intelligence (HLAI) have been used interchangeably to refer to the Holy Grail of Artificial Intelligence (AI) research, creation of a machine capable of achieving goals in a wide range of environments. However, widespread implicit assumption of equivalence between capabilities of AGI and HLAI appears to be unjustified, as humans are not general intelligences. In this paper, we will prove this distinction.
Unpredictability of AI
May 29, 2019The young field of AI Safety is still in the process of identifying its challenges and limitations. In this paper, we formally describe one such impossibility result, namely Unpredictability of AI. We prove that it is impossible to precisely and consistently predict what specific actions a smarter-than-human intelligent system will take to achieve its objectives, even if we know terminal goals of the system. In conclusion, impact of Unpredictability on AI Safety is discussed.
Personal Universes: A Solution to the Multi-Agent Value Alignment Problem
Jan 01, 2019AI Safety researchers attempting to align values of highly capable intelligent systems with those of humanity face a number of challenges including personal value extraction, multi-agent value merger and finally in-silico encoding. State-of-the-art research in value alignment shows difficulties in every stage in this process, but merger of incompatible preferences is a particularly difficult challenge to overcome. In this paper we assume that the value extraction problem will be solved and propose a possible way to implement an AI solution which optimally aligns with individual preferences of each user. We conclude by analyzing benefits and limitations of the proposed approach.
Emergence of Addictive Behaviors in Reinforcement Learning Agents
Nov 14, 2018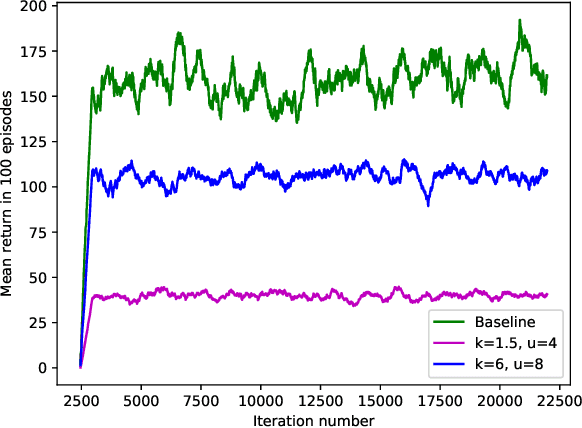
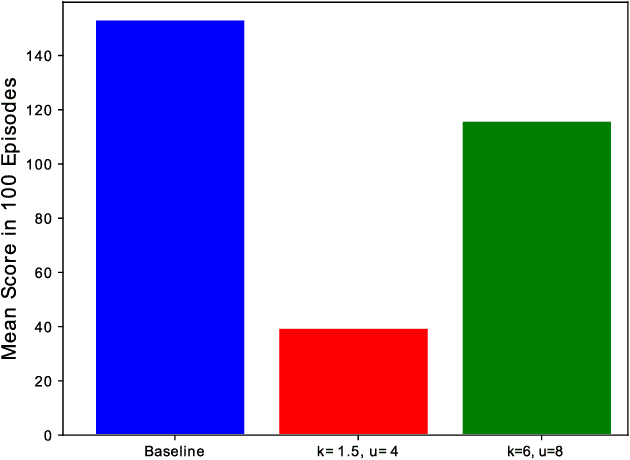

This paper presents a novel approach to the technical analysis of wireheading in intelligent agents. Inspired by the natural analogues of wireheading and their prevalent manifestations, we propose the modeling of such phenomenon in Reinforcement Learning (RL) agents as psychological disorders. In a preliminary step towards evaluating this proposal, we study the feasibility and dynamics of emergent addictive policies in Q-learning agents in the tractable environment of the game of Snake. We consider a slightly modified settings for this game, in which the environment provides a "drug" seed alongside the original "healthy" seed for the consumption of the snake. We adopt and extend an RL-based model of natural addiction to Q-learning agents in this settings, and derive sufficient parametric conditions for the emergence of addictive behaviors in such agents. Furthermore, we evaluate our theoretical analysis with three sets of simulation-based experiments. The results demonstrate the feasibility of addictive wireheading in RL agents, and provide promising venues of further research on the psychopathological modeling of complex AI safety problems.
Optical Illusions Images Dataset
Oct 16, 2018
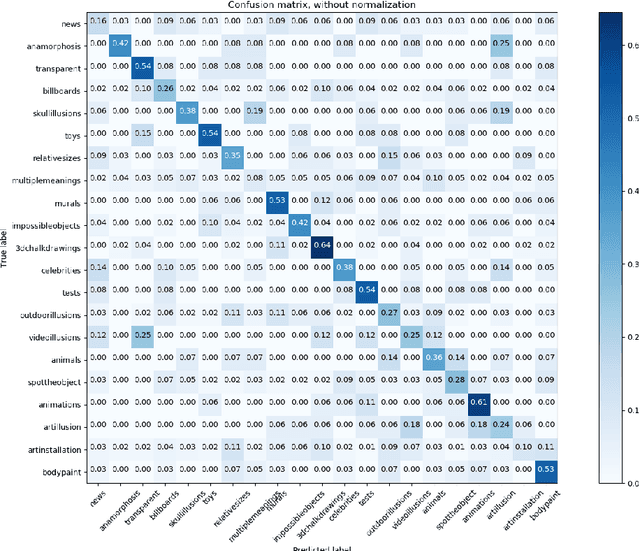

Human vision is capable of performing many tasks not optimized for in its long evolution. Reading text and identifying artificial objects such as road signs are both tasks that mammalian brains never encountered in the wild but are very easy for us to perform. However, humans have discovered many very specific tricks that cause us to misjudge color, size, alignment and movement of what we are looking at. A better understanding of these phenomenon could reveal insights into how human perception achieves these feats. In this paper we present a dataset of 6725 illusion images gathered from two websites, and a smaller dataset of 500 hand-picked images. We will discuss the process of collecting this data, models trained on it, and the work that needs to be done to make it of value to computer vision researchers.
Why We Do Not Evolve Software? Analysis of Evolutionary Algorithms
Oct 12, 2018In this paper, we review the state-of-the-art results in evolutionary computation and observe that we do not evolve non trivial software from scratch and with no human intervention. A number of possible explanations are considered, but we conclude that computational complexity of the problem prevents it from being solved as currently attempted. A detailed analysis of necessary and available computational resources is provided to support our findings.