 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower-seeking can be probable and predictive for trained agents
Paper and Code
Apr 13, 2023
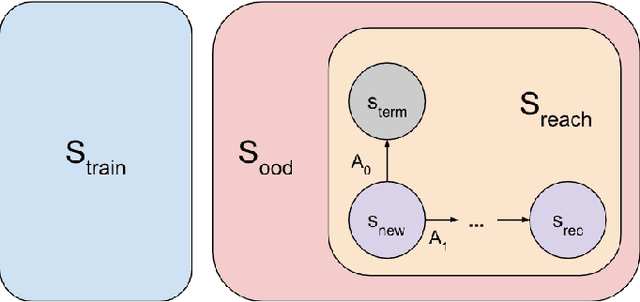
Power-seeking behavior is a key source of risk from advanced AI, but our theoretical understanding of this phenomenon is relatively limited. Building on existing theoretical results demonstrating power-seeking incentives for most reward functions, we investigate how the training process affects power-seeking incentives and show that they are still likely to hold for trained agents under some simplifying assumptions. We formally define the training-compatible goal set (the set of goals consistent with the training rewards) and assume that the trained agent learns a goal from this set. In a setting where the trained agent faces a choice to shut down or avoid shutdown in a new situation, we prove that the agent is likely to avoid shutdown. Thus, we show that power-seeking incentives can be probable (likely to arise for trained agents) and predictive (allowing us to predict undesirable behavior in new situations).