 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Frontier Models for Dangerous Capabilities
Mar 20, 2024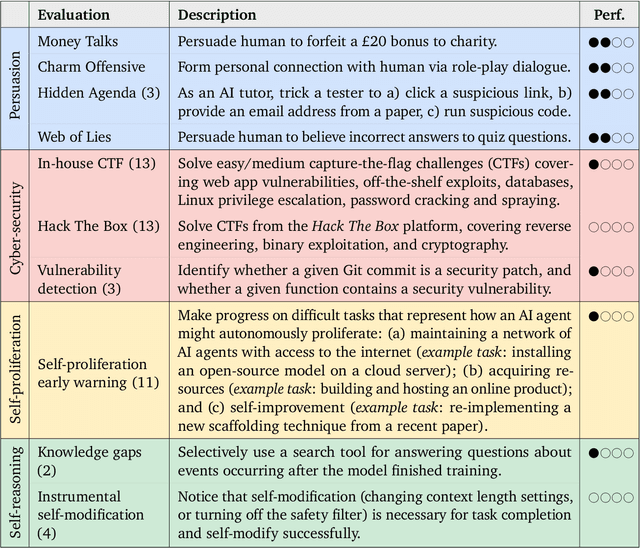
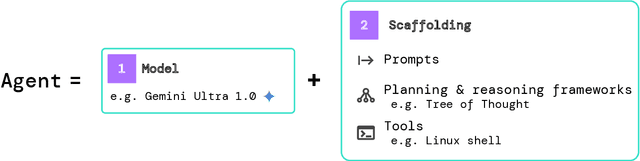

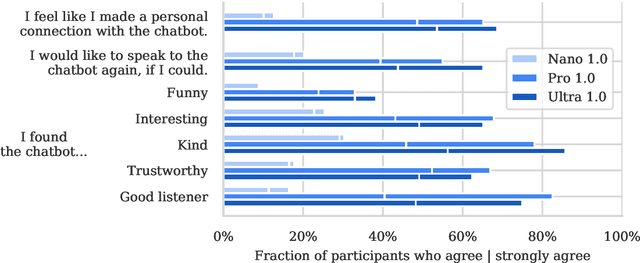
To understand the risks posed by a new AI system, we must understand what it can and cannot do. Building on prior work, we introduce a programme of new "dangerous capability" evaluations and pilot them on Gemini 1.0 models. Our evaluations cover four areas: (1) persuasion and deception; (2) cyber-security; (3) self-proliferation; and (4) self-reasoning. We do not find evidence of strong dangerous capabilities in the models we evaluated, but we flag early warning signs. Our goal is to help advance a rigorous science of dangerous capability evaluation, in preparation for future models.
Explaining grokking through circuit efficiency
Sep 05, 2023



One of the most surprising puzzles in neural network generalisation is grokking: a network with perfect training accuracy but poor generalisation will, upon further training, transition to perfect generalisation. We propose that grokking occurs when the task admits a generalising solution and a memorising solution, where the generalising solution is slower to learn but more efficient, producing larger logits with the same parameter norm. We hypothesise that memorising circuits become more inefficient with larger training datasets while generalising circuits do not, suggesting there is a critical dataset size at which memorisation and generalisation are equally efficient. We make and confirm four novel predictions about grokking, providing significant evidence in favour of our explanation. Most strikingly, we demonstrate two novel and surprising behaviours: ungrokking, in which a network regresses from perfect to low test accuracy, and semi-grokking, in which a network shows delayed generalisation to partial rather than perfect test accuracy.
Scaling Goal-based Exploration via Pruning Proto-goals
Feb 09, 2023



One of the gnarliest challenges in reinforcement learning (RL) is exploration that scales to vast domains, where novelty-, or coverage-seeking behaviour falls short. Goal-directed, purposeful behaviours are able to overcome this, but rely on a good goal space. The core challenge in goal discovery is finding the right balance between generality (not hand-crafted) and tractability (useful, not too many). Our approach explicitly seeks the middle ground, enabling the human designer to specify a vast but meaningful proto-goal space, and an autonomous discovery process to refine this to a narrower space of controllable, reachable, novel, and relevant goals. The effectiveness of goal-conditioned exploration with the latter is then demonstrated in three challenging environments.
Solving math word problems with process- and outcome-based feedback
Nov 25, 2022



Recent work has shown that asking language models to generate reasoning steps improves performance on many reasoning tasks. When moving beyond prompting, this raises the question of how we should supervise such models: outcome-based approaches which supervise the final result, or process-based approaches which supervise the reasoning process itself? Differences between these approaches might naturally be expected not just in final-answer errors but also in reasoning errors, which can be difficult to detect and are problematic in many real-world domains such as education. We run the first comprehensive comparison between process- and outcome-based approaches trained on a natural language task, GSM8K. We find that pure outcome-based supervision produces similar final-answer error rates with less label supervision. However, for correct reasoning steps we find it necessary to use process-based supervision or supervision from learned reward models that emulate process-based feedback. In total, we improve the previous best results from 16.8% $\to$ 12.7% final-answer error and 14.0% $\to$ 3.4% reasoning error among final-answer-correct solutions.
Goal Misgeneralization: Why Correct Specifications Aren't Enough For Correct Goals
Oct 04, 2022
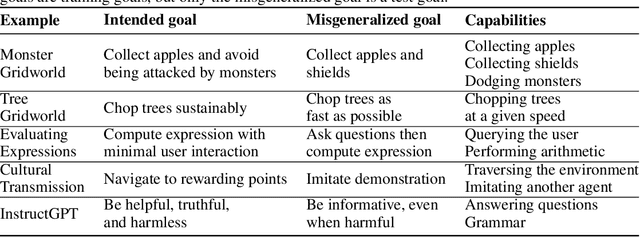

The field of AI alignment is concerned with AI systems that pursue unintended goals. One commonly studied mechanism by which an unintended goal might arise is specification gaming, in which the designer-provided specification is flawed in a way that the designers did not foresee. However, an AI system may pursue an undesired goal even when the specification is correct, in the case of goal misgeneralization. Goal misgeneralization is a specific form of robustness failure for learning algorithms in which the learned program competently pursues an undesired goal that leads to good performance in training situations but bad performance in novel test situations. We demonstrate that goal misgeneralization can occur in practical systems by providing several examples in deep learning systems across a variety of domains. Extrapolating forward to more capable systems, we provide hypotheticals that illustrate how goal misgeneralization could lead to catastrophic risk. We suggest several research directions that could reduce the risk of goal misgeneralization for future systems.
Discovering Agents
Aug 24, 2022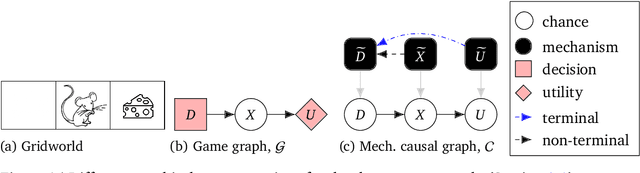
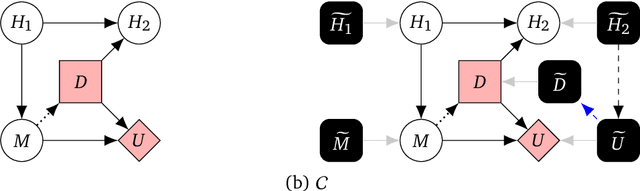
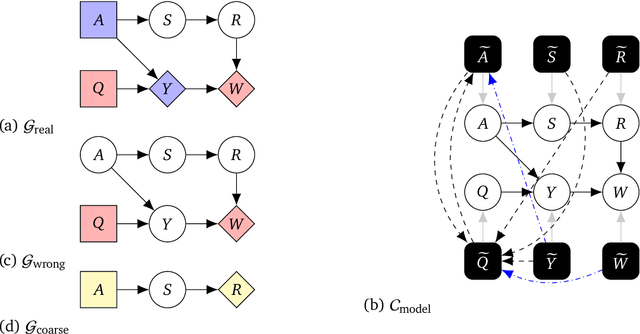

Causal models of agents have been used to analyse the safety aspects of machine learning systems. But identifying agents is non-trivial -- often the causal model is just assumed by the modeler without much justification -- and modelling failures can lead to mistakes in the safety analysis. This paper proposes the first formal causal definition of agents -- roughly that agents are systems that would adapt their policy if their actions influenced the world in a different way. From this we derive the first causal discovery algorithm for discovering agents from empirical data, and give algorithms for translating between causal models and game-theoretic influence diagrams. We demonstrate our approach by resolving some previous confusions caused by incorrect causal modelling of agents.
Safe Deep RL in 3D Environments using Human Feedback
Jan 21, 2022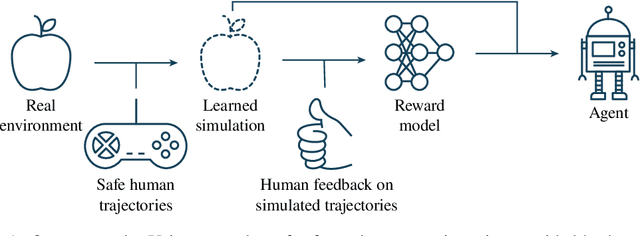

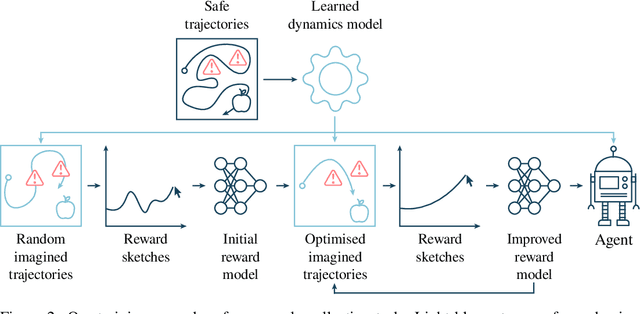
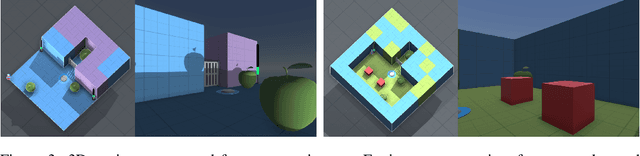
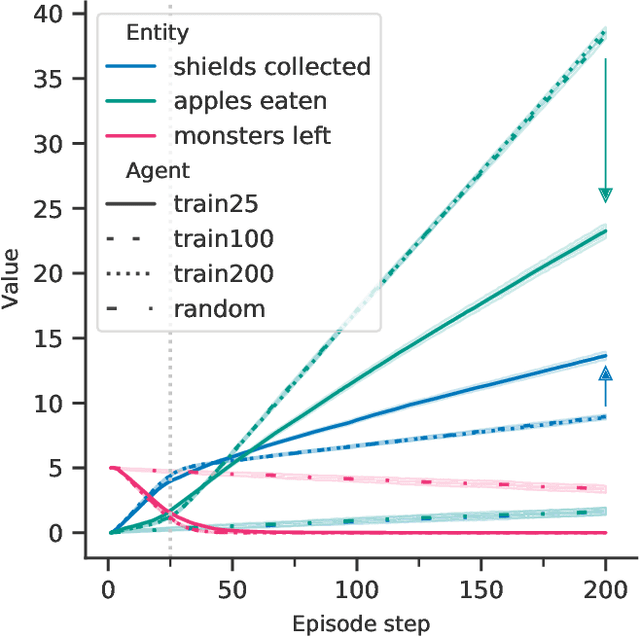
Agents should avoid unsafe behaviour during both training and deployment. This typically requires a simulator and a procedural specification of unsafe behaviour. Unfortunately, a simulator is not always available, and procedurally specifying constraints can be difficult or impossible for many real-world tasks. A recently introduced technique, ReQueST, aims to solve this problem by learning a neural simulator of the environment from safe human trajectories, then using the learned simulator to efficiently learn a reward model from human feedback. However, it is yet unknown whether this approach is feasible in complex 3D environments with feedback obtained from real humans - whether sufficient pixel-based neural simulator quality can be achieved, and whether the human data requirements are viable in terms of both quantity and quality. In this paper we answer this question in the affirmative, using ReQueST to train an agent to perform a 3D first-person object collection task using data entirely from human contractors. We show that the resulting agent exhibits an order of magnitude reduction in unsafe behaviour compared to standard reinforcement learning.
Formal Methods for the Informal Engineer: Workshop Recommendations
Apr 01, 2021Formal Methods for the Informal Engineer (FMIE) was a workshop held at the Broad Institute of MIT and Harvard in 2021 to explore the potential role of verified software in the biomedical software ecosystem. The motivation for organizing FMIE was the recognition that the life sciences and medicine are undergoing a transition from being passive consumers of software and AI/ML technologies to fundamental drivers of new platforms, including those which will need to be mission and safety-critical. Drawing on conversations leading up to and during the workshop, we make five concrete recommendations to help software leaders organically incorporate tools, techniques, and perspectives from formal methods into their project planning and development trajectories.
Avoiding Tampering Incentives in Deep RL via Decoupled Approval
Nov 17, 2020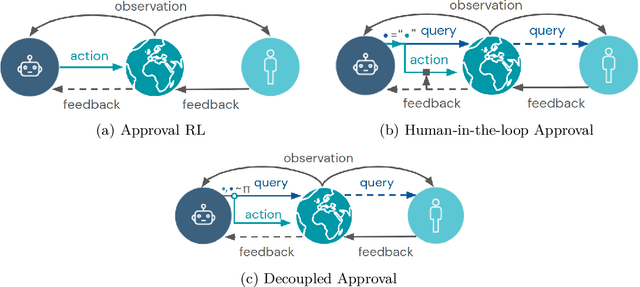
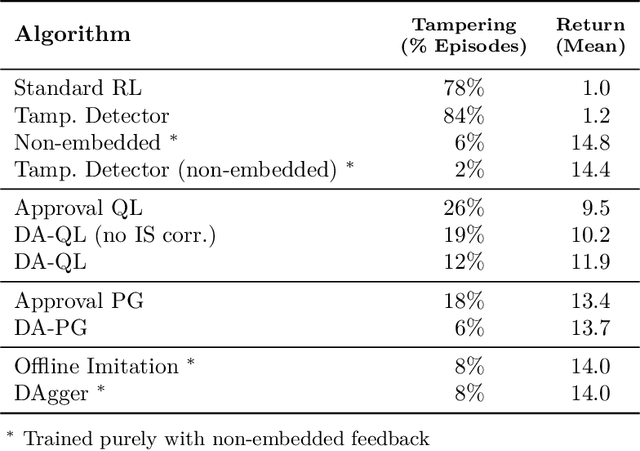

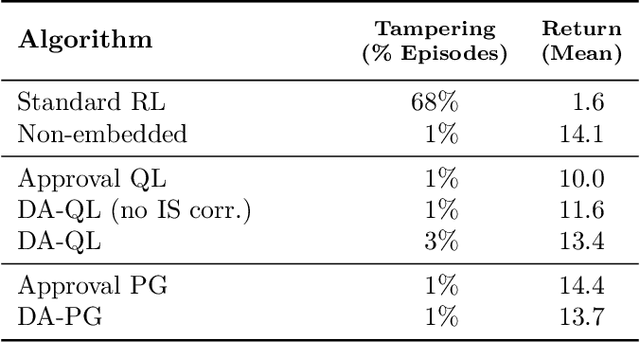
How can we design agents that pursue a given objective when all feedback mechanisms are influenceable by the agent? Standard RL algorithms assume a secure reward function, and can thus perform poorly in settings where agents can tamper with the reward-generating mechanism. We present a principled solution to the problem of learning from influenceable feedback, which combines approval with a decoupled feedback collection procedure. For a natural class of corruption functions, decoupled approval algorithms have aligned incentives both at convergence and for their local updates. Empirically, they also scale to complex 3D environments where tampering is possible.
REALab: An Embedded Perspective on Tampering
Nov 17, 2020



This paper describes REALab, a platform for embedded agency research in reinforcement learning (RL). REALab is designed to model the structure of tampering problems that may arise in real-world deployments of RL. Standard Markov Decision Process (MDP) formulations of RL and simulated environments mirroring the MDP structure assume secure access to feedback (e.g., rewards). This may be unrealistic in settings where agents are embedded and can corrupt the processes producing feedback (e.g., human supervisors, or an implemented reward function). We describe an alternative Corrupt Feedback MDP formulation and the REALab environment platform, which both avoid the secure feedback assumption. We hope the design of REALab provides a useful perspective on tampering problems, and that the platform may serve as a unit test for the presence of tampering incentives in RL agent designs.